Time Based Metadata
The design of TAMS lends itself very well to AI analysis of content, stored in small segments. As segments arrive in the store, it is possible to use the webhook event notifications to trigger the content to be analysed. Equally, most live workflows have additional feeds of metadata alongside the media, whether this is created through manual logging processes or through data feeds such as sports data.
App Note 0004 on the TAMS spec Github provides some more detail on the different types of non-media files and when they could or could not be a good fit to store within a TAMS store. This document focuses on the question of where to store the time-based metadata that is generated and whether this should be stored within TAMS.
At its core, TAMS is designed to hold media and allow the discovery of all the media elements that make up a piece of content. The store does have a flow type for storing data files against a timerange. This means that it is possible to take the file from AI analysis processes or the output from a logging stage and then upload that as a segment against a flow. While this is a perfectly legitimate use for the TAMS store, it will not give the user the ability to use the data for activities like searching content.
Time Addressable metaData Store
The Time Addressable metaData Store (TADS) is a concept for how time based metadata should be stored in a way that is optimized for working with a TAMS.
The TADS approach assumes that the TAMS store is part of a wider architecture. The TADS element could either be a separate microservice or integrated into a larger component, such as a MAM system.
TAMS provides both strong identity and timing data for media content. For the TADS to work with it efficiently, this timing and identity information should also be used to store the metadata. This removes the need for converting back and forth between different identities and timing models when locating media.
Metadata should be stored in the TADS model using the source and flow ID’s used within the TAMS store. If the live source originates in an NMOS environment, then the source and flow identities can be preserved between the different domains, offering greater interoperability.
Where the metadata is relevant to a particular section of the content, the time range format from the TAMS store should be used. This preserves the timing data in a consistent format between the two components. If the source metadata is provided with a different timing data model, we recommend converting it to the same code timing model used in the TAMS store, which is based on International Atomic Time (TAI).
Working with TADS and TAMS
To locate content in the TAMS store using the time based metadata, it is expected that a user would start the process in some form of UI presentation layer, most likely a MAM or PAM system. This would provide the user with an interface to be able search for content.
The presentation layer would forward the search request to the TADS service, which could then search through the time based metadata. It would then return the list of potential sources in which a user might be interested in addition to time ranges.
On selecting the content to be viewed, the TADS store could provide more data to populate the presentation layer UI. For example, the time based metadata may be displayed as additional metadata tracks on a UI alongside a player window.
To enable the user to quickly access the right piece of content, the presentation layer could take the source and time range metadata from the TADS service. Using this data, it could then query TAMS for the relevant flows for media playback and then jump directly to the required time range.
The key to making this process as simple as possible at the point of search is to normalize the data on the way in and the consistency between the different components.
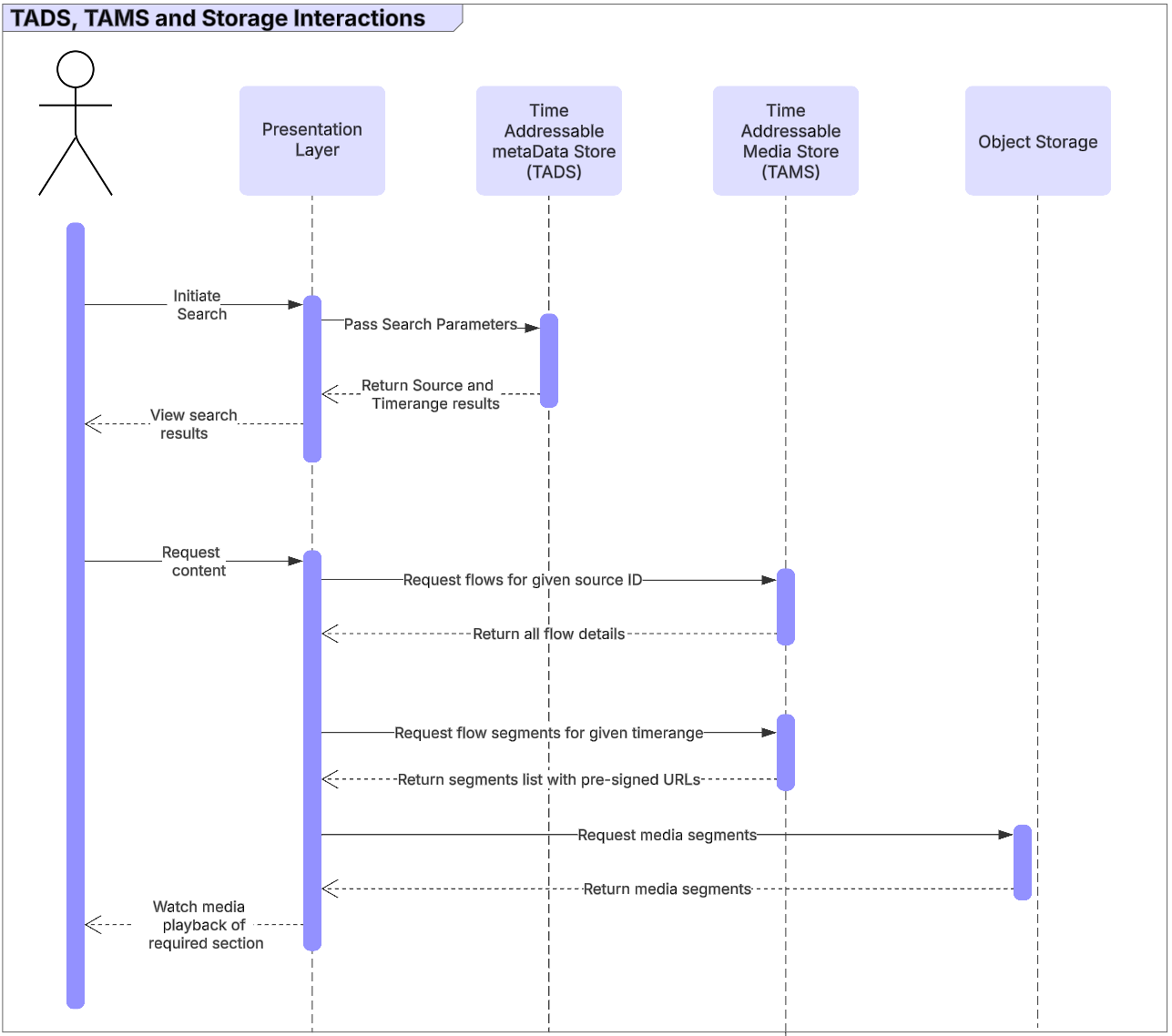
Figure 15: Process of working with TAMS and TADS
TADS Design
Currently, there is no reference architecture or API specification for TADS as there is for TAMS. However, the technical approach is not dissimilar to that already taken by MAM and PAM vendors. The key difference is in the timing and reference data stored in the correct formats.
We recommend that the TADS component should store the following fields as a minimum:
Top level Source ID of the required content
Flow ID if the analysis is specific to a certain flow
Time range that the metadata applies to
Metadata type (or track), for example transcription or logging metadata
Data to be searched
Vector embedding (optional)
For speed of search, we also recommend that implementers look at tools such as OpenSearch. This provides a rich set of tools for search across content types, including the ability to merge results and semantic search capabilities.