Working with TAMS
When creating content within a TAMS store, the sequence of creating the different elements matters. The most important element to create are the flows.
A flow includes a reference to the source to which it belongs. If the source exists within the store, then the two will be linked. However, if the source does not exist, then the store will automatically create it. When a source is created, the label and description fields from the flow will initially be replicated to the source. It is up to the store implementation whether the tags from the flow will be replicated to the source. The AWS open source implementation does, but it is optional in the specification. Once the source is created, it is then possible to call the TAMS API and update the label or description as well as add tags required.
If creating a multi-essence flow, any mono-essence flows which are to be collected by it must exist in the store prior to creating the flow collection. The creation of a multi-essence flow will cause a multi-essence source to be created by the store. This new source will automatically collect any other sources associated to the flows collected by the multi-essence flow.
If new flows are to be added to an existing multi-flow, they must be created and then added to the collection. The store in turn will ripple the collections up from the flow to source level.
Within the store it is not possible to create sources directly. These are created and deleted along with their associated flows.
Reading Content
It is expected that a TAMS store will be used as a layer within a larger architecture that would include some form of MAM or PAM. This would give a user the rich media tools to be able to store and search content.
If locating content directly within a store, the usual place to start would be the top level sources–those which are not collected by any other source. It is possible to search on fields including label, description, and tags, but these are not expected to replace the rich search of a MAM layer.
Once the required top level source has been located, it is then possible to read down through the data model. Two routes are possible depending on what is required: either going through the collected sources or through the multi-essence flow.
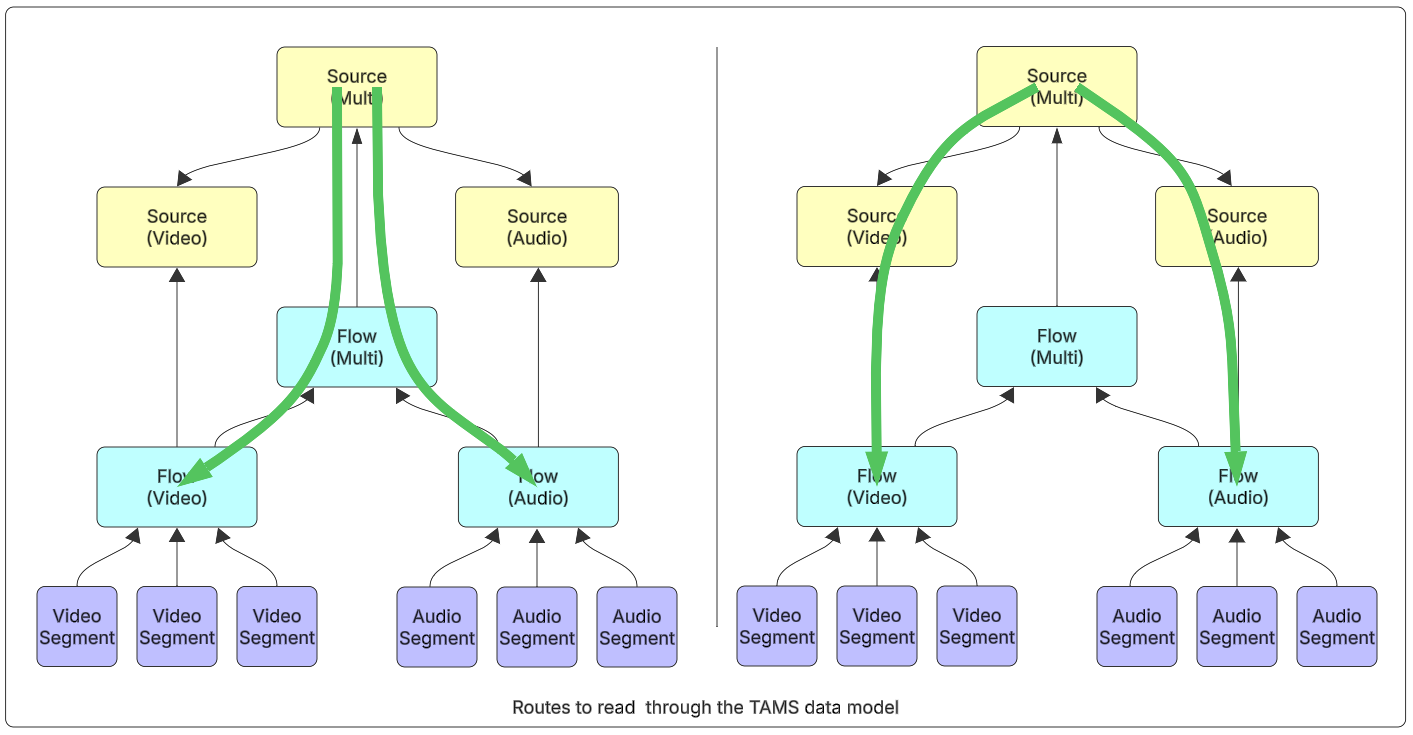
Figure 11: Routes to read through the TAMS data model
The reading system will need to locate the appropriate flows that match the task that is needs to fulfill. This may mean reading multiple flows (for example, high quality and proxy video), and then deciding which is most appropriate to use.
Once the flow has been located, it is possible to request the segments for the whole flow or just a specific timerange within the flow. The store will return the list of segments along with the timerange that they represent and the URL or URLs to be able to access the content.
Depending on the flags set when requesting content from the store, the list of URLs may include pre-signed links or direct paths. The pre-signed URLs allow direct access to the content on object storage without the need to provision storage credentials directly to the client. It also ensures permissions are handled within the store, meaning that reading systems can only access content to which they have permission.
For trusted systems, it is possible to provision direct access to the S3 bucket and then read the direct links. This is only recommended for trusted systems, as it will have access to all content stored within the bucket and will not be restricted by any permissions held within the TAMS API.
Mono Essence v Muxed Media
Creating new content in a TAMS store starts with the creation of the relevant essence flows. For simplicity in the workflows, we recommend using mono-essence flows. This means separating audio and video into separate segments and registering them under separate flows.
The separation means that for workflows where multiple video resolutions share the same audio or for edit by reference workflows, the media manipulation is simplified and no duplication is required. A multi-essence flow is created to represent the combination of video and audio, but for mono-essence workflows, this is represented using flow collections, and no segments are directly registered to the multi-essence flow.
It is possible to use muxed media files where the workflow requires this. In this scenario, the muxed media segments are registered directly to the multi-essence flow. It is still necessary to have the separate essence flows, as these contain the technical parameters for the essence. There are also additional container mapping elements added to the essence flows to point to the relevant tracks within the muxed essence files.
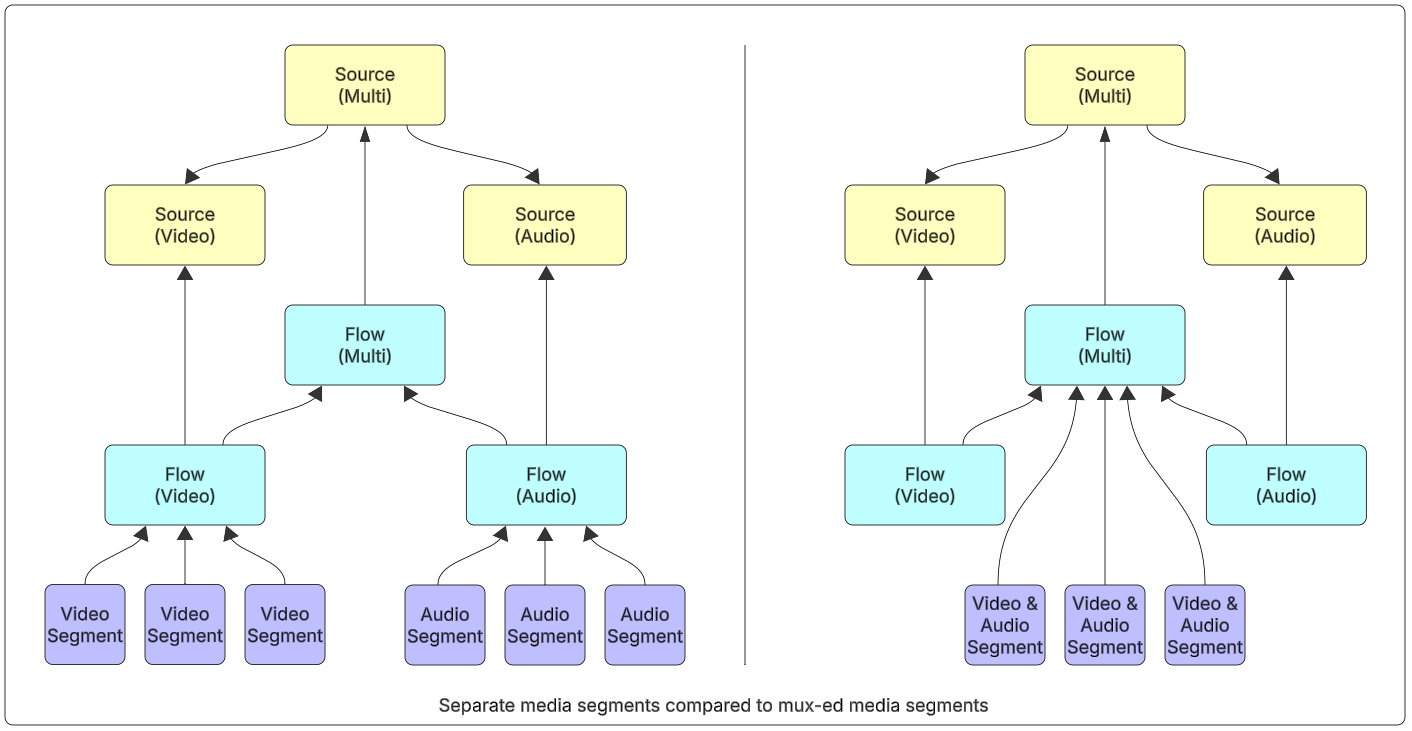
Figure 12: Separate media segments compared to muxed media segments
Creating New Mono Essence Sources and Flows
To store mono-essence media within TAMS, the first step is to create the separate mono-essence flows. These hold the technical characteristics of the segments registered to them. It is possible to have multiple flows representing the same content. For example, the video may have multiple different resolutions, bit rates, codecs or frame rates. Each variant would be stored as a separate flow but would be registered with the same source ID.
Upon creation of the mono-essence flows, the relevant source(s) will be automatically created in the TAMS store. At this point, the different media types will still be separate elements.
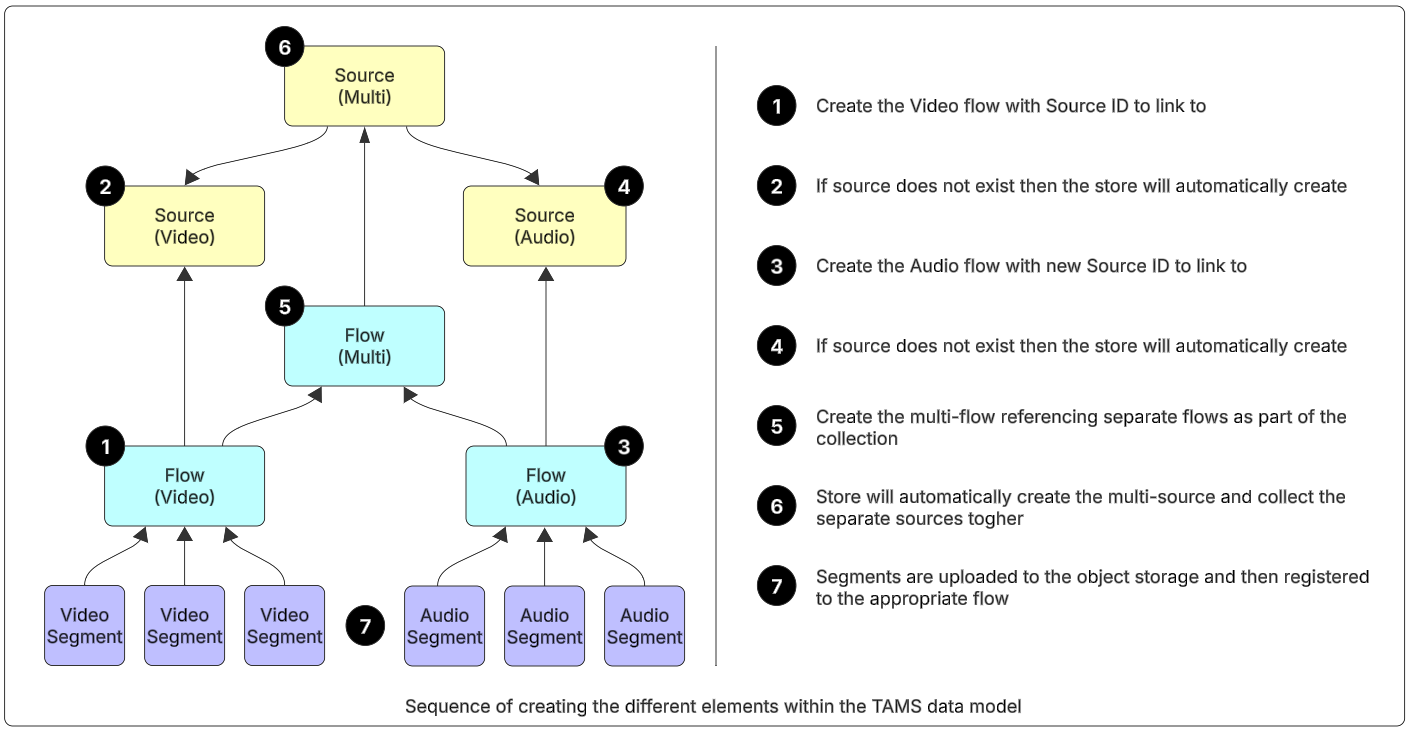
Figure 13: Sequence of creating the different elements within the TAMS data model
To represent the combination of audio and video into a single version, a multi-essence flow should be created. This flow has no essence parameters, as there is no media stored against it. The multi-flow definition includes a collection element, and this should include the IDs and roles of all flows to be collected together.
Flow collections can only be created or removed against the multi-flow. The store will manage the collections automatically, such that querying against a mono-essence flow will list all the flows it is collected by, but these cannot be modified against the mono-essence flow.
Upn creation of the multi-essence flow, the corresponding multi-essence source will be created. Where the flow collects other flows, the store will automatically resolve the links to the relevant sources and create the corresponding source collection links. The creating system does not need to create the source collections directly.
App Note 007 in the TAMS API repo describes how source metadata is populated within a store: https://github.com/bbc/tams/blob/aaefef3126606a02b73e4c9e24761364a5d5586a/docs/appnotes/0007-populating-source-metadata.md
A set of scripts walking through the process to create a set of flows and sources are available in the guidance repository. The process of using the scripts are described in the section on the AWS TAMS Sample Scripts.
Registering Segments
To simplify the need for both API and storage credentials, the TAMS API will supply pre-signed URLs for media objects to be uploaded to. This is done by calling the storage endpoint for a given flow and requesting the required number of pre-signed URLs.
The creating system then uploads the media object directly to the object storage using the pre-signed URL. No other credentials are required for this process.
After upload, the creating system then needs to call the TAMS API and register the object against the given flow. As part of the registration, the creating system will declare the timerange where the segment sits within the flow timeline. For the initial segment registration, the timing metadata within the media file is expected to match the timerange for the segment.
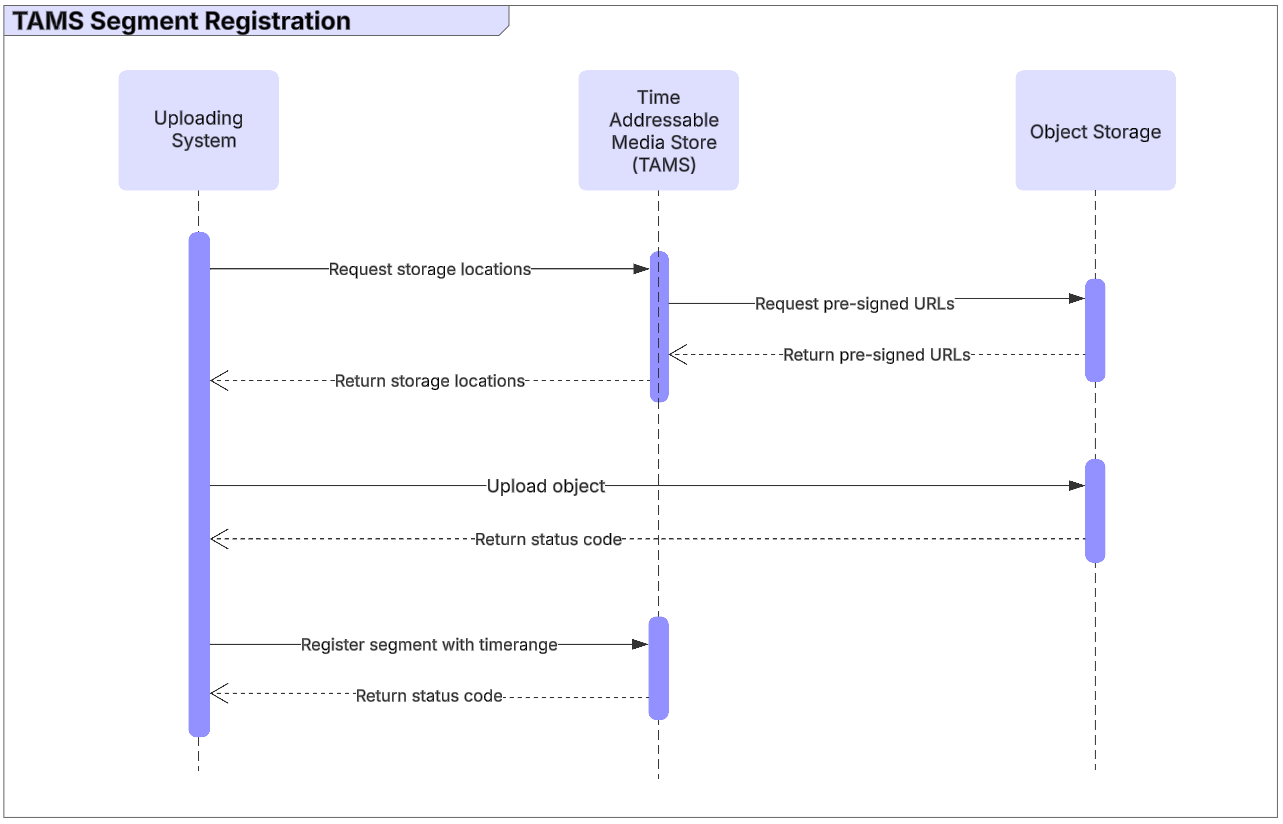
Figure 14: Sequence of registering segments with the store
For Edit by Reference workflows, it is possible to re-use a segment. This is done by registering a segment on the new flow timeline with the same object ID as the original object. The store will recognize the object re-use automatically. At the point of registration, it is also possible to specify only part of a segment to be used and offsets from the internal file timing to that of the flow timeline.
A script showing this process is available in the guidance repository and the process of using it to upload content is described in the section on the AWS TAMS Sample Scripts.
Deleting Content
Within a TAMS store, all content deletions happen at the flow level. There are three ways that content can be deleted:
- Delete the whole of a flow and all segments beneath it.
- Delete a segment.
- Delete part of a flow by specifying the timerange to be deleted.
In all scenarios, the TAMS store will process the delete in such a manner that the segments linked to the flow will appear to delete immediately and no longer be available for use. Depending on the implementation of the store, there may be a delay between the initial delete request processing and the actual removal of the objects from the object storage. In the AWS Open Source TAMS API, this is set to 1 hour by default.
For objects which are referenced in multiple flows, the store is responsible for managing the housekeeping of them. When a delete request is made, the store will check if the object is referenced in any other flows. If there are no other references, then the store will queue the object for deletion. If the object is used in other flows, then the pointer from the flow will be removed, but the object will remain in place until all references are removed.
Where a delete request will take longer than the time available to respond to a synchronous API call, the store can chose to create a delete task for asynchronous processing. There is a dedicated API endpoint to track progress of these requests.