TAMS Data Model
This section provides more information about the underlying data model described in the TAMS specification. Where this guide differs from the information provided in the specification, the specification should be treated as the authoritative source.
The TAMS data model is based on elements of the AMWA NMOS MS-04 model which in turn is based on the Joint Taskforce on Network Media (JT-NM)reference architecture for best practice in how to build IP based media solutions. This means that many of the core terms (for example, flows and sources) used within the API will be recognizable to anyone who as worked with the live IP video world.
Sources
Sources represent the actual piece of content that a user might want to access, while the actual representations of this content are held at the Flow level. Within a TAMS store, we recommend that content be stored as a separate essence with video and audio held separately.
Media workflows and applications are likely to use Sources as their references to media, for example, a MAM might reference an asset using the ID of a Source (in lieu of a file name). Then, business logic can be applied to identify a suitable Flow representing that Source at the point when operations need to be performed on the media, for example, choosing between proxy-quality for an offline edit and full-quality for a render.
For content stored as a separate essence, there will usually be two levels of sources. The first would group together all the content of the same type (for example, audio or video), and the second would then collect these to create a muxed version of the content. This muxed version of the content would be considered the primary version which the user would be aware of. The muxed version is created in the TAMS API by collecting all separate sources together as a collection with space to indicate the role of each source within the collection.
For content where the audio and video are muxed, or there is only a single type of essence present, it is possible to only have the single level of source content.
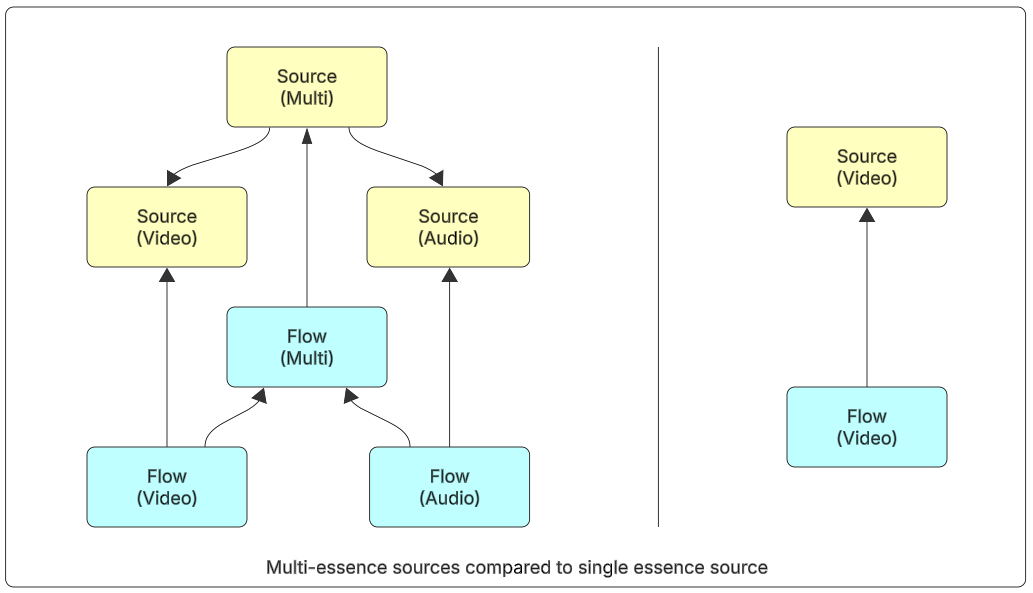
Figure 7: Multi-essence sources compared to single essence source
The source allows for both a label and description within the data model, both of which are free text and available for the content creator to populate. In typical usage, the label is often a short form human readable identifier, while the description provides additional context to help locate and identify content. The source can also contain tags, which are a freeform key value pairing to assign additional metadata at the source level. There is an app note in the specification which lists some of the known tags.
The data model of the source deliberately does not contain a rich editorial metadata model as the TAMS specification defines a media storage layer. For workflows requiring complex metadata models, it is expected that this will be stored in another layer, for example, a MAM.
Flows
In the TAMS data model, the flow is a technical representation of the source content to which it is linked. This will define the type (for example, audio or video) and the technical characteristics of all the segments linked to it. Typically, the audio and video elements of the content are split into separate mono-essence segments for ease of working, which are then stored under separate flows.
There are four types of flows:
- Video: For storing video only segments, no audio is present in them
- Audio: For audio only segments
- Data: For other non-media segment types
- Multi: To store media which has both video and audio in the same segment and to link the mono-essence flows
The flow data model contains all the technical characteristics of the segments. The API is agnostic for the format of the media, so when creating the flow, you can specify key fields such as codec, wrapper, bit rate, and others.
For content where multiple versions of the media exists (for example, HD and proxy), multiple flows are created and linked to the corresponding source. In these cases, the content needs to be editorially identical, just with different technical characteristics.
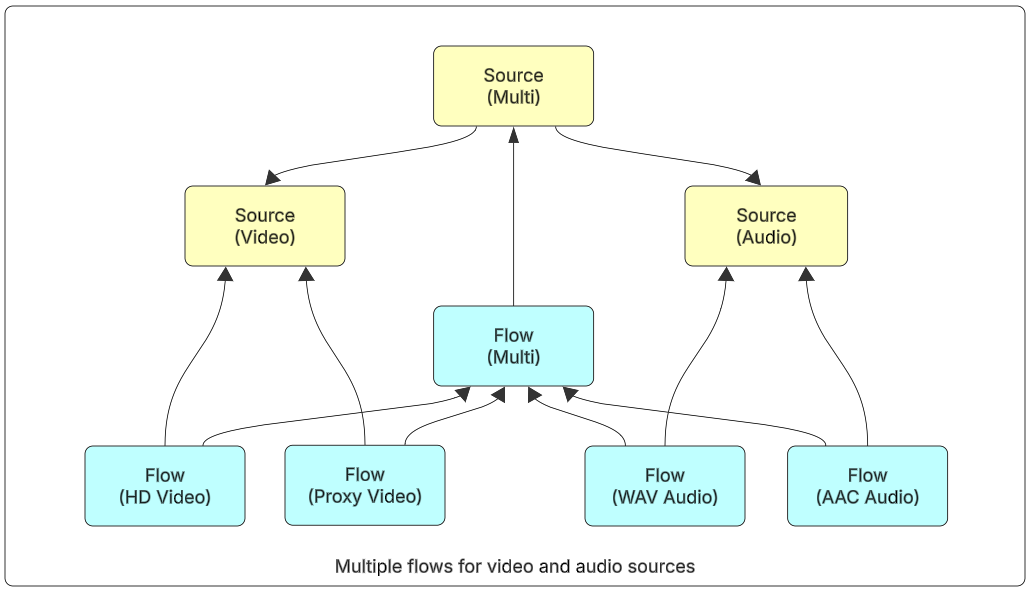
Figure 8: Multiple flows for video and audio sources
More information on multiple mono essence sources can be found in the App Note 0001:
https://github.com/bbc/tams/blob/main/docs/appnotes/0001-multi-mono-essence-flows-sources.md
Segments
A segment in the data model is the link between the actual media object and the flow which technically describes it. When an object is uploaded to the store, it is registered against an initial flow with the relevant timing data.
All the segments for a given flow exist on a virtual and infinite timeline. When a new segment is registered to a flow, the timing data declares where on the timeline the segment exists. The reader can then read a flow and will get a series of segment data back which will describe how the segments fit together on the timeline as well as links to the actual objects.
Once a segment is registered in the store, it can be reused across multiple flows in an “edit by reference” style workflow. This means that to create new versions or edits of the content, the segments which are unchanged in the new content can just be linked to the new source and flow without duplicating. The store then handles the management of the segments and housekeeping process to ensure that segments used multiple times are only deleted when no more references remain in the store.
The actual segment files are short, independent media files, which are then played back in sequence such that a viewer would not realize that they were separate files. We strongly recommended that the media files be independently decodable. This means that for Long GOP codecs, the segments should have complete sets of GOPs present in them. Otherwise, it would be necessary for the decoder to be aware of the surrounding segments in order to play back the required one.
More information on file encoding and decoding can be found in App Note 0005:
https://github.com/bbc/tams/blob/aaefef3126606a02b73e4c9e24761364a5d5586a/docs/appnotes/0005-indepentent-segments.md
Timelines and Timeranges
Time is a core element to a TAMS store, as each flow has a virtual and infinite timeline associated with it to which segments are registered. Rather than using the traditional SMPTE timecode, the TAMS store uses actual timing data in the form of International Atomic Time (TAI) plus nano-seconds.
The timerange format allows for both instantaneous timestamps, for declaring content such as images, and timeranges with both a start and finish time. The format also has the ability to indicate whether the time is inclusive or exclusive of the timing point, which is declared by the use of square or round brackets. For continuous segments, typically, the start timestamp is declared as inclusive and end is exclusive. By reusing the same timestamp as the end of the previous segment and start of the next timestamp, you are declaring there is no gap between the segments.
While gaps are allowed in a timeline, it is not allowed for segments to be created which overlap. If a writer tries to create overlapping segments, then the store will reject this. Gaps may exist for legitimate reasons where content does not exist to fill them. This could include scenarios where a camera was not recording for that period or where only certain sections of content have been replicated between multiple TAMS stores.
If only part of a flow timeline is required, it is possible to query the flow using a time range. The store will return only the segments which either partially or fulling within the timerange specified.

Figure 9: Example of segments on a flow timeline with query by timerange
It is expected that the timing data is created by the component which registers the segment with the store. For a live feed, it is expected that the encoder would be locked to a high quality time signal, such as PTP, which would then be used to generate the timing information for the TAMS store. This means that for multiple live feeds, if all the encoders are locked to the same time source, then all the segments should be time referenced correctly relative to each other.
The ability for the creator to specify the timerange also allows for other behaviors. For example, it is possible to populate a timeline in any order required. If a camera uploads live segments and the connection is interrupted, then it can resume uploading the segments when the connection is restored. In the background, the camera can then work back and fill in the missing segments, such that the gap in the timeline is filled. It also allows for multi-store workflows where content is replicated, complete with both timing and identify information, between the stores.
The move away from SMPTE timecode–which is based on a 24 hour clock–to actual time makes a number of live workflows simpler. Live recordings running across midnight have traditionally been an issue, as the timecode resets to 0:00:00:00. However in a TAMS store, this is not an issue, as all the timing includes both date and time. Similarly, very long recordings over 24 hours are possible as more segments can simply be appended and the new timestamps declared.
Full details of the timerange format can be found in App Note 0008 in the TAMS repo:
https://github.com/bbc/tams/blob/aaefef3126606a02b73e4c9e24761364a5d5586a/docs/appnotes/0008-timestamps-in-TAMS.md
Multi-channel audio
The TAMS store is horizontally scalable to support multiple audio and video components for a single piece of content. The most common use case for this will be to support multi-channel audio workflows where additional tracks are required for example multiple languages, audio descriptions, or mix and effects tracks.
Each of the audio sources has one or more flows associated with it to represent the technical characteristics of the media segments.
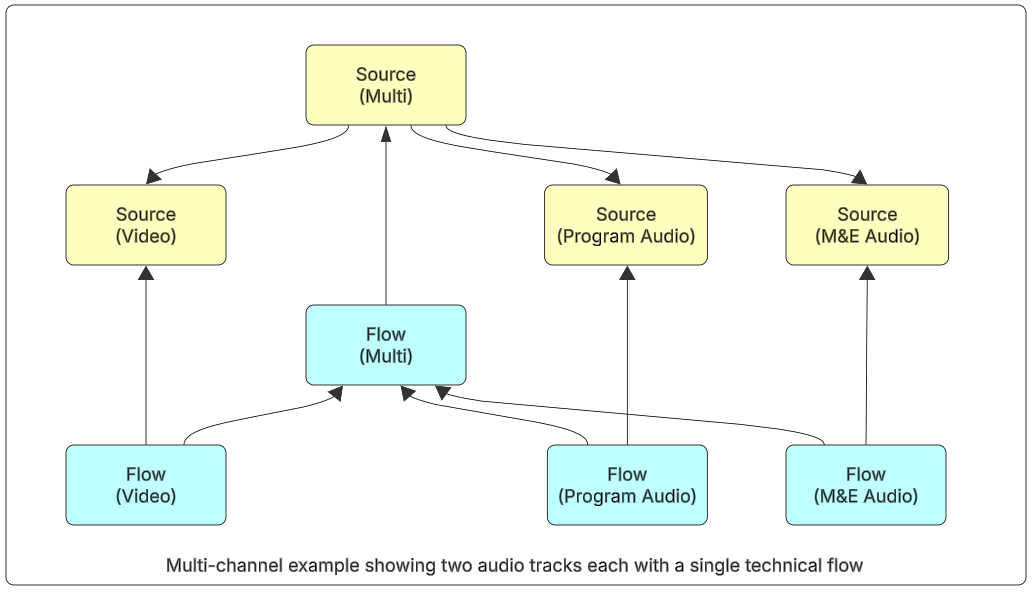
Figure 10: Multi-channel audio example showing two audio tracks each with a single technical flow
Tags
Within both the source and flow data models, there is the ability to add tags. These are simple key value pairs aimed at holding implementation specific metadata. It is possible to add, remove, and search on these tags, providing a great level of flexibility within the data model. In some cases, a tag may also be used to trial metadata fields before consideration and before being elevated to the core API.
To assist in tracking common tags, there is an app note within the TAMS specification repository. If a tag is being used across multiple systems or vendors, we recommend registering it with the app note to prevent compatibility issues in the future:
https://github.com/bbc/tams/blob/main/docs/appnotes/0003-tag-names.md.