Customizations¶
Custom events + queries (sample walkthroughs)¶
- non-real-time
- real-time
Custom ETL¶
(Optional) Glue Iceberg Parameter Setup¶
If the data lake is configured with Apache Iceberg, Glue configuration parameters need to be specified to enable Apache Iceberg for Spark jobs. These can be specified under default parameters
-
Create a new parameter with the key
--datalake-formats. Set the value to beiceberg. -
Create a new parameter with the key
--enable-glue-datacatalog. Set the value to betrue. -
Create a new parameter with the key
--conf. Set the value to bespark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog --conf spark.sql.catalog.glue_catalog.warehouse=s3://<ANALYTICS_S3_BUCKET_NAME>/ --conf spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO.- Replace
<ANALYTICS_S3_BUCKET_NAME>with the name of the created S3 bucket for analytics.
- Replace
You can view more on setting up Iceberg with Glue jobs here.
Custom Real-Time Metrics¶
For live analytics, this solution deploys an Amazon Managed Service for Apache Flink application. This application utilizes PyFlink with the Flink Table API to build custom metrics using SQL. Please see the Flink Table API Tutorial to learn more.
The pre-created job defines two streams, a source and a sink. These are defined using a CREATE TABLE command with the Amazon Kinesis Data Streams SQL Connector.
The source reads from the input Kinesis data stream and the sink writes to the output Kinesis data stream. These streams are configured using variables loaded from the application's configured runtime properties.
Source Stream Properties¶
- Since data is nested in the
eventJSON attribute of the message, the FlinkROWdata type is utilized to define known attributes and make them accessible using a dot notation.- This is done for the attributes
event_version,event_id,event_type,event_name,event_timestamp, andevent_data.
- This is done for the attributes
event_datacontains a nested JSON object, of which has a user-defined schema that varies depending on the event. Since the schema changes dpeending on the event type, it is extracted as aSTRINGdata type.- To retrieve values nested in the object, the
JSON_VALUEfunction is used within aggregation queries.
- To retrieve values nested in the object, the
rowtimeis retrieved explicitly fromevent.event_timestampobject and converted into aTIMESTAMP_LTZdata type attribute. This makes the event time accessible for use in windowing functions.rowtimeis used for watermarking within Flink.
Modifying schema¶
Modifying/extending architecture¶
- Allow both Redshift and non-redshift
Modifying dashboards (ops and analytics)¶
Configuring Access to OpenSearch UI¶
The deployed OpenSearch Application can be configured to allow users access through SAML federation.
For this, three components are needed:
-
Set up SAML Federation to connect your identity provider with the OpenSearch Interface. The federation must be set up to assume a created IAM role. The steps to do so can be found here.
-
Update the IAM role that users will assume when accessing the dashboard. This role must have access to OpenSearch Serverless and OpenSearch UI. Example permissions for configuring OpenSearch Serverless can be found here, permissions to allow access to OpenSearch UI can be found here.
-
Update the data access policy to grant the created IAM role permission to access the OpenSearch Serverless collection. More information on OpenSearch Serverless data access policies can be found here.
After these steps are complete, users can use their logins to access the dashboard and create visualizations.
Creating Visualizations and Dashboards with OpenSearch¶
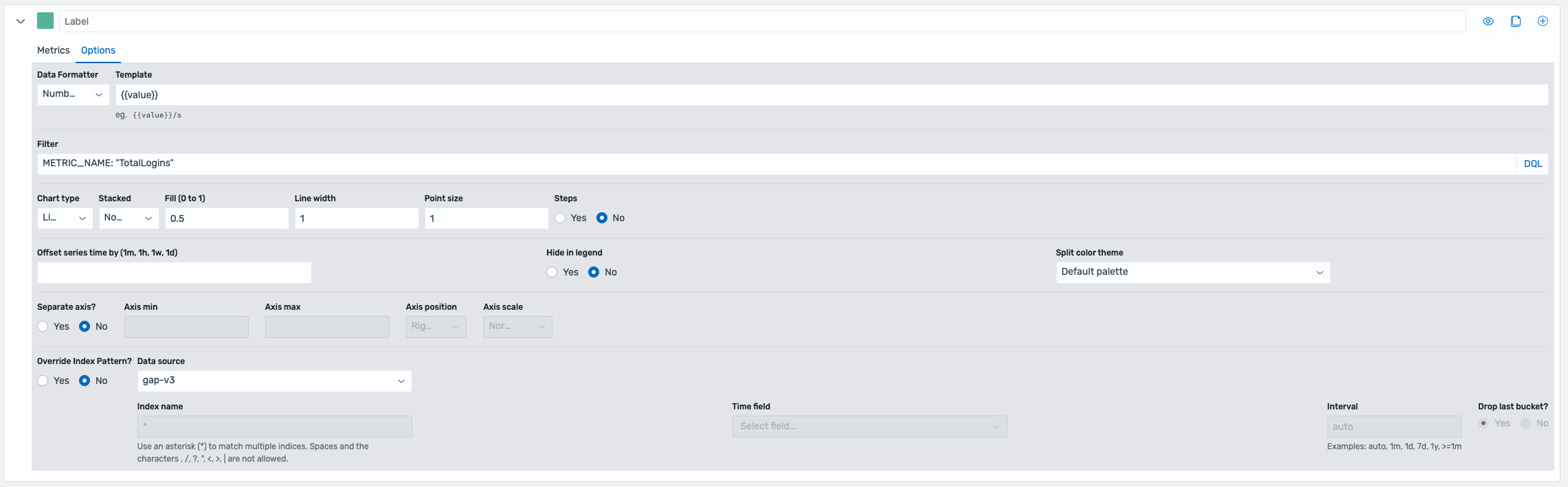
The metric data stored in the OpenSearch index can be used to create visualizations which can be combined into dashboards. OpenSearch offers a variety of visualizations as well as the Dashboards Query Language (DQL) to filter data.
A strong visualization for metrics are time-series visualizations. These can be created using the Time-Series Visual Builder (TSVB) visualization tool.
Since different metrics have different dimension data, it is strongly recommended to filter data for a specific metric name before proceeding with metric creation. This can be done using the DQL filter under options.
(TODO: Send from game engines)¶
Utilize the integrated HTTP libraries in your game engine to form and send requests to the Send Events API.