Guidance for Scalable Model Inference and Agentic AI on Amazon EKS
Summary: This implementation guide provides an overview of the Guidance for Scalable Model Inference and Agentic AI on Amazon EKS, its reference architecture and components, and considerations for planning the deployment, and configuration steps for deploying the Guidance name to Amazon Web Services (AWS). This guide is intended for solution architects, business decision makers, DevOps engineers, data scientists, and cloud professionals who want to implement Guidance for Scalable Model Inference and Agentic AI on Amazon EKS in their environment.
Overview
This guidance implements a comprehensive, scalable Machine Learning model Inference architecture on Amazon Elastic Kubernetes Service (EKS), container orchestration platform leveraging both AWS Graviton processors for cost-effective CPU-based core services and agentic workflows and NVIDIA GPU based and AWS Inferentia instances for accelerated inference tasks as compute nodes managed by Karpenter auto-scaler. This architecture provides a complete end-to-end application platform for deploying Large Language Models (LLM) and appplications with Agentic AI capabilities, including Retrieval Augmented Generation (RAG) and Intelligent Document Processing (IDP).
Features and Benefits
The Guidance for Scalable Model Inference and Agentic AI on Amazon EKS provides the following features:
Amazon EKS Cluster: the foundation of guidance architecture, providing a managed Kubernetes environment with automated provisioning and best-practices based configuration.
Karpenter Compute Auto-scaling: dynamically provisions and scales compute resources based on workload demands across multiple node pools.
Compute Node Pools:
- AWS Graviton-based nodes (ARM64): Cost-effective CPU inference using
m8g/c8g(or other, per desired configuration) instances - GPU-based nodes (x86_64): High-performance inference using NVIDIA GPU instances (
g5,g6families) - AWS Inferentia-based nodes: High-performance inference using AWS Inferentia instances with Neuron SDK (
inf2family) - x86-based nodes: General purpose compute nodes for compatibility requirements
- Model Hosting Services:
- KubeRay Service: Distributed model serving with automatic scaling
- Standalone Services: Direct model deployment for specific use cases
- Multi-modal Support: Text, vision, and reasoning model capabilities
- Model Gateway Proxy:
- LiteLLM Proxy: Unified OpenAI-compatible API gateway proxy with load balancing and routing
- Ingress Controller: External access management with SSL termination
- Agentic AI Applications:
- Retrieval Augmented Generation (RAG) with AWS OpenSearch: Intelligent document retrieval and question answering
- Intelligent Document Processing (IDP): Automated document analysis and content extraction
- Multi-Agent Systems: Coordinated AI workflows with specialized agents
- Observability & Monitoring:
- LangFuse: LLM observability and performance monitoring
- Prometheus & Grafana: Infrastructure monitoring and alerting
This architecture provides users with flexibility to choose between running ML inference on cost-optimized AWS Graviton processors based compute nodes or on high-throughput GPU or AWS Inferentia based inference, based on their specific requirements, while maintaining elastic scalability through Kubernetes API and Karpenter auto-scaler.
Use cases
This guidance demonstrates how to optimize ML workload distribution, provide unified model inference API Gateway, implement agentic AI capabilities to enable models interactions with external APIs, provide augmented LLM capabilities by combining tool usage with Retrieval Augmented Generation (RAG) for enhanced context awareness. It also features Efficient (AWS Graviton) and Accelerated (AWS Inferentia) processor compute architectures for EKS compute nodes for agentic and Model inference specific tasks respectively.
Architecture overview
This section provides a reference implementation architecture for infrastructure and components deployed with this Guidance.
Infrastructure Architecture
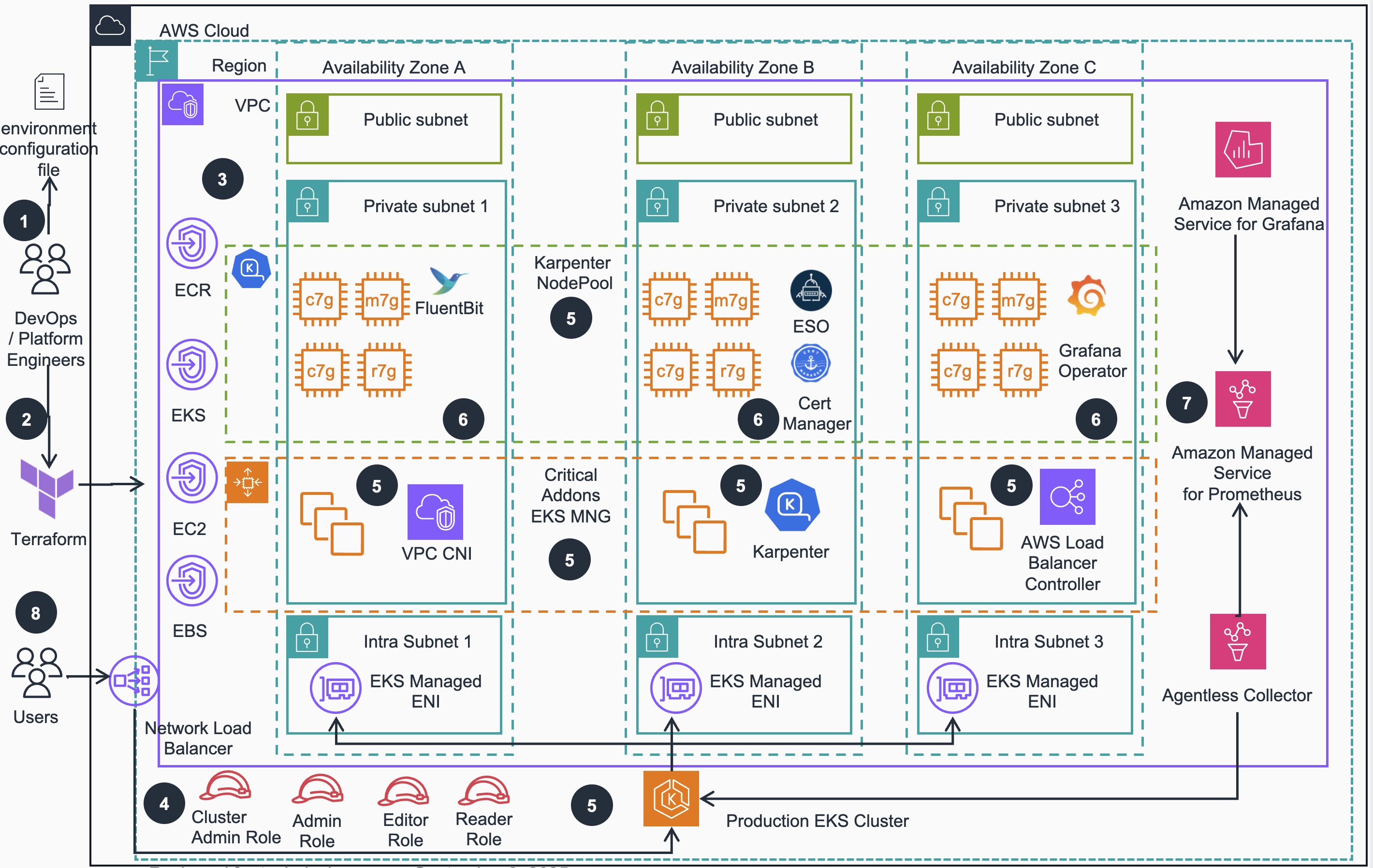
Figure 1: Scalable Model Inference and Agentic AI - Infrastructure Deployment Reference Architecture
Infrastructure Architecture steps
- DevOps engineer defines a per-environment Terraform variable file that control all of the environment-specific configuration. This configuration file is used in all steps of deployment process by all IaC configurations to create different EKS environments
- DevOps engineer applies the environment configuration using Terraform following the deployment process defined in the guidance.
- An Amazon Virtual Private Network (VPC) is provisioned and configured based on specified configuration. According to best practices for Reliability, 3 Availability zones (AZs) are configured with corresponding VPC Endpoints to provide access to resources deployed in private VPC.
- User facing Identity and Access Management (IAM) roles (Cluster Admin, Admin, Editor and Reader) are created for various access levels to EKS cluster resources, as recommended in Kubernetes security best practices
- Amazon Elastic Kubernetes Service (EKS) cluster is provisioned with Managed Nodes Group that run critical cluster add-ons (CoreDNS, AWS Load Balancer Controller and Karpenter) on its compute node instances. Karpenter will manage compute capacity to other add-ons, as well as applications that will be deployed by user while prioritizing provisioning AWS Graviton instances for the best price-performance.
- Other relevant EKS add-ons are deployed based on the configurations defined in the per-environment Terraform configuration file (see Step1 above).
- AWS Managed Observability stack is deployed (if configured), including Amazon Managed Service for Prometheus (AMP), AWS Managed collector for Amazon EKS, and Amazon Managed Service for Grafana (AMG).In addition, a grafana-operator addon is deployed with a set of predefined Grafana dashboards to get started.
- Amazon EKS cluster(s) with important add-ons, optionally configured managed Observability stack and RBAC based security mapped to IAM roles available for workload deployment, its Kubernetes API is exposed via AWS Network Load Balancer.
Application Architecture
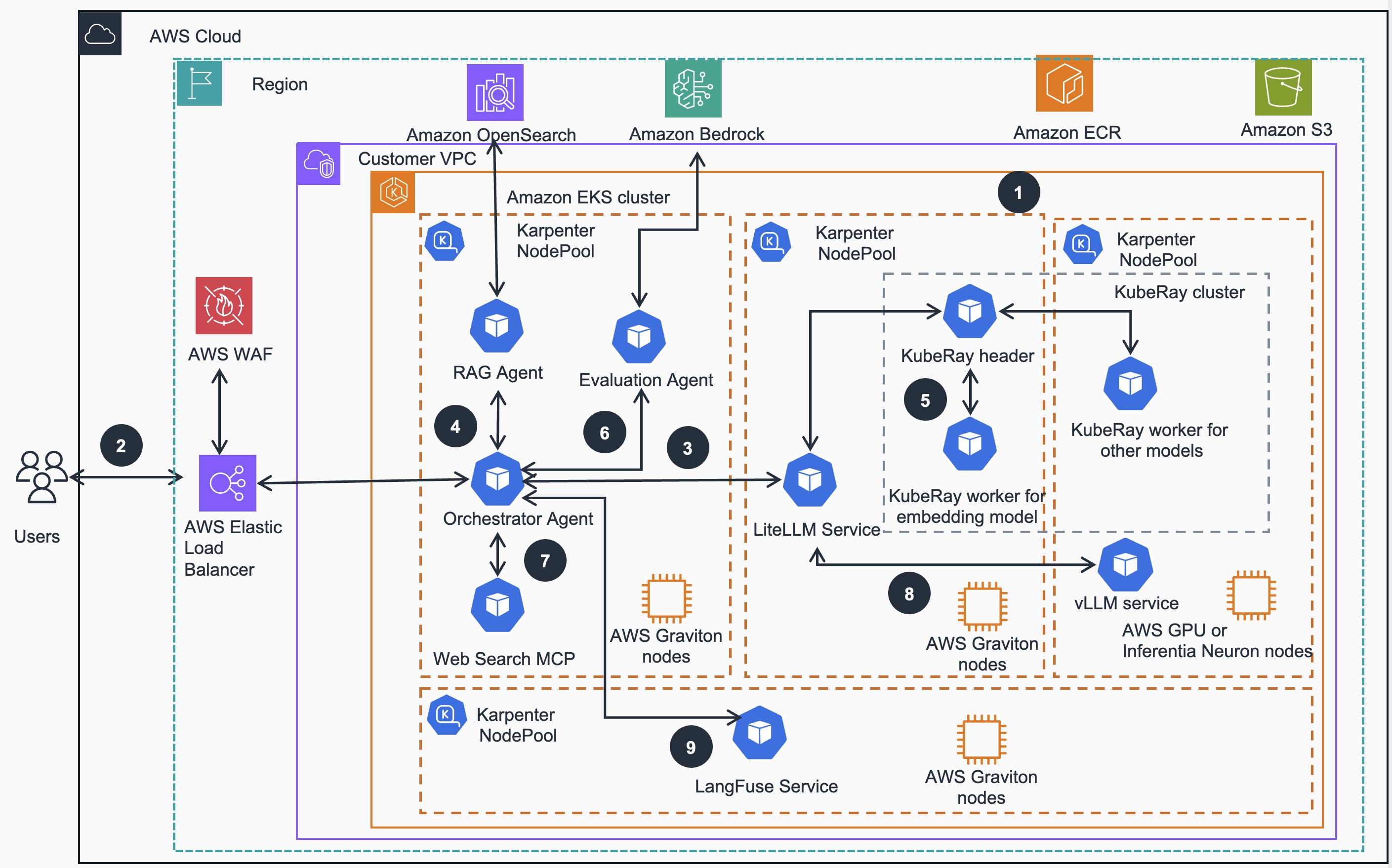
Figure 2: Scalable Model Inference and Agentic AI - Application Deployment Reference Architecture
Application Architecture Steps
Foundation Setup - Guidance is deployed on an Amazon EKS cluster, configured for application readiness and with compute plane managed by Karpenter. This setup efficiently auto-scales both AWS Graviton , GPU and Inferentia based compute nodes across multiple Availability Zones (AZs), ensuring robust infrastructure distribution and high availability of various Kubernetes services.
User Interaction - starts with an authentication to the EKS cluster via IAM (CLI or Console). Application HTTP(s) requests directed to an exposed guidance endpoint, managed by Elastic Load Balancing (ELB). This endpoint URL serves as the gateway for all user queries and ensures balanced distribution of incoming traffic while maintaining consistent accessibility.
Orchestration and Analysis: The Orchestrator agent, powered by Strands Agent SDK, serves as the central workflow coordination hub. It processes incoming queries by connecting with reasoning models supported by LiteLLM and vLLM services, analysing the requests, and determining the appropriate workflow and tools needed for response generation. LiteLLM functions as a unified API gateway proxy for model management, providing centralized security controls and standardized access to both embedding and reasoning models.
Knowledge Validation: Orchestrator agent delegates to RAG agent to verify knowledge base validity to initiate Knowledge validation. When updates are needed, the RAG agent initiates the process of embedding new information into the Amazon OpenSearch cluster, ensuring the Knowledge Base remains current and comprehensive.
Embedding Process: KubeRay cluster handles the embedding process where the Ray header dynamically manages cluster worker node scaling based on resource demands. These worker nodes execute the embedding process through the llamacpp framework, while the RAG agent simultaneously embeds user questions and searches for relevant information with the OpenSearch cluster
Quality Assurance: Evaluation agent performs Response Quality assurance which leverages models hosted in Amazon Bedrock. This agent implements a feedback-based correction loop using RAGAS metrics to assess response quality and provides relevancy scores to the orchestrator agent for decision-making purposes
Web Search Fallback: When the RAG agent’s responses receive relevancy scores below the configured threshold, the Orchestrator agent initiates a web search process. It retrieves the Tavily web search API tool from the Web search Model context Protocol (MCP) server and performs dynamic queries to obtain supplementary or corrective information.
Final Response Generation: vLLM models running on GPU (or Inferentia) instances generate final responses which are returned via LiteLLM gateway to Orchestrator agent. The reasoning model processes the aggregated information, including both Knowledge Base data and Web search results when applicable, refining and rephrasing the content to create a coherent and accurate response for the user’s prompt.
Comprehensive Tracking and Monitoring: Throughout this entire process, the Strands Agent SDK maintains comprehensive interaction tracking. The Strands Agent SDK automatically traces all agent activities and communications, with the resulting metrics visualized via the LangFuse service, providing transparency and monitoring of the system’s operations. Additional, infrastructure level observability is provided via previously deployed and configured Prometheus /Grafana observability stack.
AWS services in this Guidance
| AWS Service | Role | Description |
|---|---|---|
| Amazon Elastic Kubernetes Service (EKS) | Core service | Manages the Kubernetes control plane and worker nodes for container orchestration. |
| Amazon Elastic Compute Cloud (EC2) | Core service | Provides the compute instances for EKS worker nodes and runs containerized applications. |
| Amazon Virtual Private Cloud (VPC) | Core Service | Creates an isolated network environment with public and private subnets across multiple Availability Zones. |
| Amazon Elastic Container Registry (ECR) | Supporting service | Stores and manages Docker container images for EKS deployments. |
| AWS Elastic Load Balancing (ELB) | Supporting service | Distributes incoming traffic across multiple targets in the EKS cluster. |
| Amazon Elastic Block Store (EBS) | Supporting service | Provides persistent block storage volumes for EC2 instances in the EKS cluster. |
| AWS Identity and Access Management (IAM) | Supporting service | Manages access to AWS services and resources securely, including EKS cluster access. |
| Amazon Managed Service for Grafana (AMG) | Observability service | Provides fully managed service for metrics visualization and monitoring. |
| Amazon Managed Service for Prometheus (AMP) | Observability service | Offers managed Prometheus-compatible monitoring for container metrics. |
| AWS Certificate Manager (ACM) | Security service | Manages SSL/TLS certificates for secure communication within the cluster. |
| Amazon CloudWatch | Monitoring service | Collects and tracks metrics, logs, and events from EKS and other AWS resources provisioned in the guidance |
| AWS Systems Manager | Management service | Provides operational insights and takes action on AWS resources. |
| AWS Key Management Service (KMS) | Security service | Manages encryption keys for securing data in EKS and other AWS services. |
| Amazon Open Search | Supporting Service | Simplify AI-powered search, observability, and vector database operations with a secure, cost-effective managed service |
| Amazon Bedrock | Supporting Service | Provides foundation models and agent capabilities for natural language processing and multi-agent orchestration. |
Plan your deployment
This section covers prerequisites for successful deployment of this guidance.
Cost
You are responsible for the cost of the AWS services used while running this Guidance. As of November, 2025, the cost for running this Guidance with the default settings in the US East (N. Virginia) us-east-1 region is approximately $447.47/month.
We recommend creating a budget through AWS Cost Explorer to help manage costs. Prices are subject to change, for full details, refer to the pricing webpage for each AWS service used in this guidance.
Sample cost table
The following table provides a sample cost breakdown for deploying this guidance with the default parameters in the us-east-1 (N. Virginia) Region for one month. This estimate is based on the AWS Pricing Calculator output for the full deployment as per the guidance.
| AWS service | Dimensions | Cost, month [USD] |
|---|---|---|
| Amazon EKS | 1 cluster | $73.00 |
| Amazon VPC | 3 NAT Gateways | $98.67 |
| Amazon EC2 | 2 m6g.large instances | $112.42 |
| Amazon Managed Service for Prometheus (AMP) | Metric samples, storage, and queries | $100.60 |
| Amazon Managed Grafana (AMG) | Metrics visualization - Editor and Viewer - for users | $14.00 |
| Amazon EBS | gp2 storage volumes and snapshots | $17.97 |
| Application Load Balancer | 1 ALB for workloads | $16.66 |
| Amazon VPC | Public IP addresses | $3.65 |
| AWS Key Management Service (KMS) | Keys and requests | $7.00 |
| Amazon CloudWatch | Metrics | $3.00 |
| Amazon ECR | Container image storage | $0.50 |
| TOTAL | $447.47/month |
For a more accurate estimate based on your specific configuration and usage patterns, we recommend using the AWS Pricing Calculator.
Security
When you build systems on AWS cloud infrastructure, security responsibilities are shared between you and AWS. This shared responsibility model reduces your operational burden because AWS operates, manages, and controls the components including the host operating system, the virtualization layer, and the physical security of the facilities in which the services operate. For more information about AWS security, visit AWS Cloud Security.
This guidance implements several security best practices and AWS services to enhance the security posture of your EKS Workload Ready Cluster. Here are the key security components and considerations:
Identity and Access Management (IAM)
- IAM Roles: The architecture uses predefined IAM roles (Cluster Admin, Admin, Edit, Read) to manage access to the EKS cluster resources. This follows the principle of least privilege, ensuring users and services have only the permissions necessary to perform their tasks.
- EKS Managed Node Groups: These use IAM roles with specific permissions required for nodes to join the cluster and for pods to access AWS services.
Network Security
- Amazon VPC: The EKS cluster is deployed within a custom VPC with public and private subnets across multiple Availability Zones, providing network isolation.
- Security Groups: Although not explicitly shown in the diagram, security groups are typically used to control inbound and outbound traffic to EC2 instances and other resources within the VPC.
- NAT Gateways: Deployed in public subnets to allow outbound internet access for resources in private subnets while preventing inbound access from the internet.
Data Protection
- Amazon EBS Encryption: EBS volumes used by EC2 instances are typically encrypted to protect data at rest.
- AWS Key Management Service (KMS): Used for managing encryption keys for various services, including EBS volume encryption.
Kubernetes-specific Security
- Kubernetes RBAC: Role-Based Access Control is implemented within the EKS cluster to manage fine-grained access to Kubernetes resources.
- AWS Certificate Manager: Integrated to manage SSL/TLS certificates for secure communication within the cluster.
Monitoring and Logging
- Amazon CloudWatch: Used for monitoring and logging of AWS resources and applications running on the EKS cluster.
- Amazon Managed Grafana and Prometheus: Provide additional monitoring and observability capabilities, helping to detect and respond to security events.
Container Security
- Amazon ECR: Stores container images in a secure, encrypted repository. It includes vulnerability scanning to identify security issues in your container images.
Secrets Management
- AWS Secrets Manager: While not explicitly shown in the diagram, it’s commonly used to securely store and manage sensitive information such as database credentials, API keys, and other secrets used by applications running on EKS.
Additional Security Considerations
- Regularly update and patch EKS clusters, worker nodes, and container images.
- Implement network policies to control pod-to-pod communication within the cluster.
- Use Pod Security Policies or Pod Security Standards to enforce security best practices for pods.
- Implement proper logging and auditing mechanisms for both AWS and Kubernetes resources.
- Regularly review and rotate IAM and Kubernetes RBAC permissions.
Supported AWS Regions
Guidance for Scalable Model Inference and Agentic AI on Amazon EKS is supported in the following AWS Regions:
| Region Name | Region Code |
|---|---|
| US East (N. Virginia) | us-east-1 |
| US East (Ohio) | us-east-2 |
| US West (Oregon) | us-west-2 |
| Asia Pacific (Mumbai) | ap-south-1 |
| Asia Pacific (Seoul) | ap-northeast-2 |
| Asia Pacific (Singapore) | ap-southeast-1 |
| Asia Pacific (Sydney) | ap-southeast-2 |
| Asia Pacific (Tokyo) | ap-northeast-1 |
| Europe (Frankfurt) | eu-central-1 |
| Europe (Ireland) | eu-west-1 |
| Europe (London) | eu-west-2 |
| Europe (Paris) | eu-west-3 |
| Europe (Stockholm) | eu-north-1 |
| South America (São Paulo) | sa-east-1 |
Quotas
Service quotas, also referred to as limits, are the maximum number of service resources or operations for your AWS account.
Quotas for AWS services in this Guidance
Make sure you have sufficient quota for each of the AWS services implemented in this solution (see AWS Services in this guidance). For more information, see AWS service quotas.
To view the service quotas for all AWS services in the documentation without switching pages, view the information in the Service endpoints and quotas page in the PDF format.
Deploy the Guidance
Prerequisites
- Amazon EKS cluster provisioned following the best practices for handling Inference workloads, such as AWS Guidance for Automated Provisioning of Application-Ready Amazon EKS Clusters
dockerdomain and CLI tool installedkubectlCLI tool configured to access your EKS cluster API- Other required CLI tools installed (
pnpm,pip, etc.) - a Hugging Face API Token obtained (see below)
- a Tavily MCP server API Token obtained (see below)
How to generate a Hugging Face Token
To access Hugging Face models referenced in this guidance, you’ll need to create an access token:
- Sign up or log in to Hugging Face
- Navigate to Settings: Click on your profile picture in the top right corner and select “Settings”
- Access Tokens: In the left sidebar, click on “Access Tokens”
- Create New Token: Click “New token” button
- Configure Token:
- Name: Give your token a descriptive name (e.g., “EKS-ML-Inference”)
- Type: Select “Read” for most use cases (allows downloading models)
- Repositories: Leave empty to access all public repositories, or specify particular ones
- Generate Token: Click “Generate a token”
- Copy and Store: Copy the generated token immediately and store it securely
Note:
- Keep your token secure and never share it publicly
- You can revoke tokens at any time from the same settings page
- For production environments, consider using organization tokens with appropriate permissions
- Some models may require additional permissions or agreements before access
Deployment process overview
Before you launch the Guidance, review the cost, architecture, security, and other considerations discussed in this guide. Follow the step-by-step instructions in this section to configure and deploy the Guidance into your account.
Time to deploy: Approximately 35-45 minutes
The guidance deployment consists of two parts: Inference and Agentic AI platform and Agentic AI application.
First, let us go through the Inference and Agentic AI platform deployment.
Start with cloning the project code repository locally:
git clone https://github.com/aws-solutions-library-samples/guidance-for-scalable-model-inference-and-agentic-ai-on-amazon-eks.git
cd guidance-for-scalable-model-inference-and-agentic-ai-on-amazon-eks
NOTE: Currently used for EKS cluster provisoning Guidance for Automated Provisioning of Application-Ready Amazon EKS clusters defaults to EKS AutoMode for an easier lifecycle management and upgrade of cluster services and add-ons. In order to enable AutoMode, please make sure that in your per-environment Terraform configuration file you have settings similar to this sample configuration file:
... cluster_config = { kubernetes_version = "1.34" eks_auto_mode = true // AutoMode enabled, when set to true, all other self-managed add-ons are set to false private_eks_cluster = false capabilities = { gitops = false } } ...To deploy this guidance appllications for EKS AutoMode, please use the
eks-automodecode branch: For that purpose, use the following command after the cloning the repository locally:
git checkout eks-automode
..
git branch
main
* eks-automode
and follow the instructions below since all make commands are applicable to both code branches.
If you prefer NOT to use EKS AutoMode, you can deploy the EKS cluster using another sample configuration file:
...
cluster_config = {
kubernetes_version = "1.34"
eks_auto_mode = false // When set to true, all other self-managed add-ons are set to false
private_eks_cluster = false
capabilities = {
gitops = false
}
}
...
and then use the main code branch (which is checked out by default), following the instructuions below.
There are two approaches to deploy the Inference and Agentic AI applications:
Option 1: Automated Setup with Makefile (Recommended)
For the fastest and most reliable setup, use the automated Makefile option.
Verify that AWS Region and profile settings used to provision EKS cluster are in place:
export AWS_REGION=us-east-1 #use your AWS Region value
export AWS_PROFILE=default
Complete Installation
# Install all core components (base infrastructure, models, gateway, observability, agent app)
make install
You will need to input the required information through the interaction terminal after entering the ‘make install’ command
- Enter your Hugging Face model token obtained earlier:
Figure 3: Enter Hugging Face token interface
NOTE: it may take up to 20 min from entering HuggingFace token to navigation to LangFuse service
- Follow the instructions below to obtain the Langfuse keys and store the keys, you will need them when configuring the application settings
Figure 4: Enter LangFuse configuration interface
After you open your browser and navigate to the LangFuse endpoint, you need sign up first:
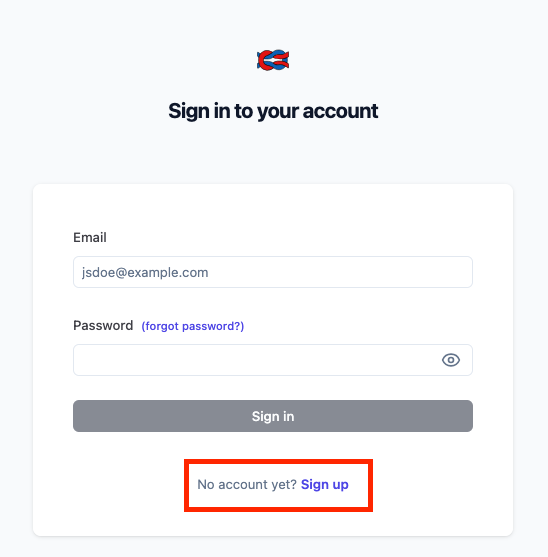
Figure 5: LangFuse user signup page
After you fill in the ‘Name’, ‘Email’ and ‘Password’ fields, click the Sign up button, copy and paste the LangFuse endpoint address in the browser again, and finish the following instructions to get the LangFuse keys and paste them in the terminal as required
Follow the steps shown below to finish the LangFuse keys setup
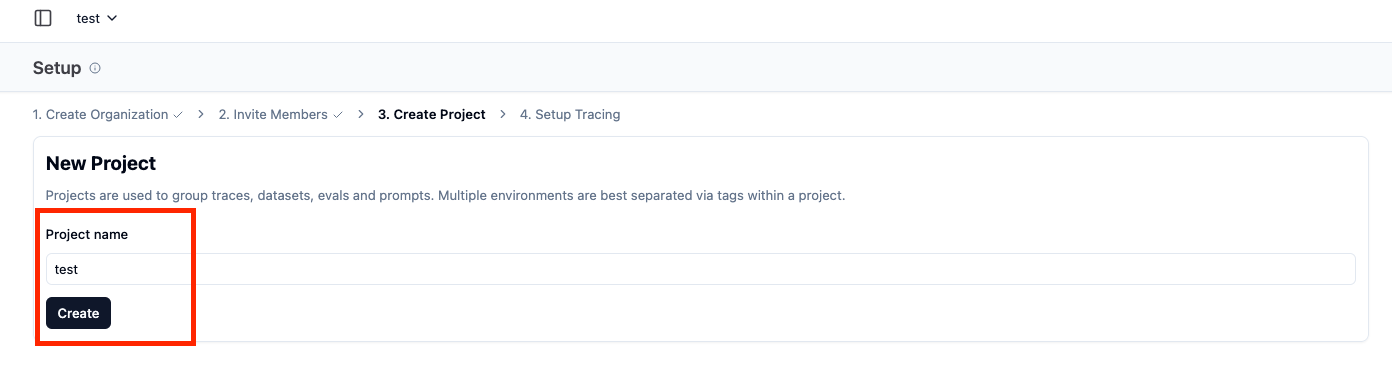
Navigate to “API Keys” section of UI, create and note values of LangFuse public and secret keys:
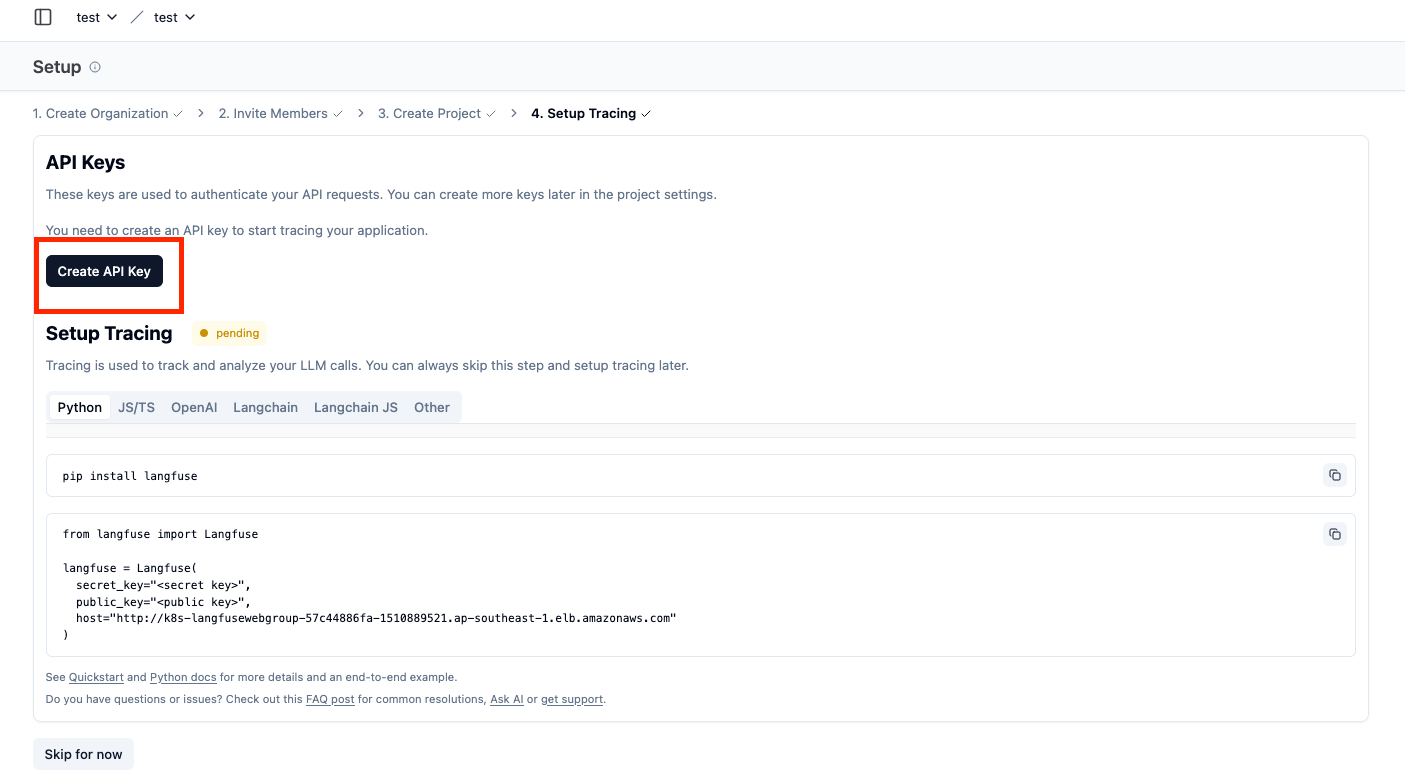
Figure 6: Steps to configure LangFuse application organization, members, project and generate secret keys
- From the LiteLLM configuration, obtain LiteLLM virtual API key and store it - you will need them when configuring the application settings

Figure 7: Using LiteLLM configuration interface to create API Key
- Edit the OpenSearch CloudFormation stack information (you can just leave it as default) and hit the ‘return’ button.

Figure 8: Edit OpenSearch CloudFormation stack configuration
NOTE: it may take up to 20 min to provision an OpenSearch cluster via CloudFormation
- Copy the value of
OPENSEARCH_ENDPOINTfrom CFN output and paste in the terminal (or you can paste your own OpenSearch domain).

Figure 9: Enter OpenSearch domain endpoint value
- Follwing the configuration prompts, fill in the values of other services (LangFuse, LiteLLM) endpoints and keys you get from previous steps:

Figure 10: Enter application settings configuration
- Congratulations - deployment of Scalable Inference and Agentic AI is completed when you see messages similar to shown below. Wait around 5 minutes for the Application Load Balancer (ALB) setup then you can run the test endpoints from your local with
curlclient and monitor the AI Agent activity via LiteLLM or LangFuse
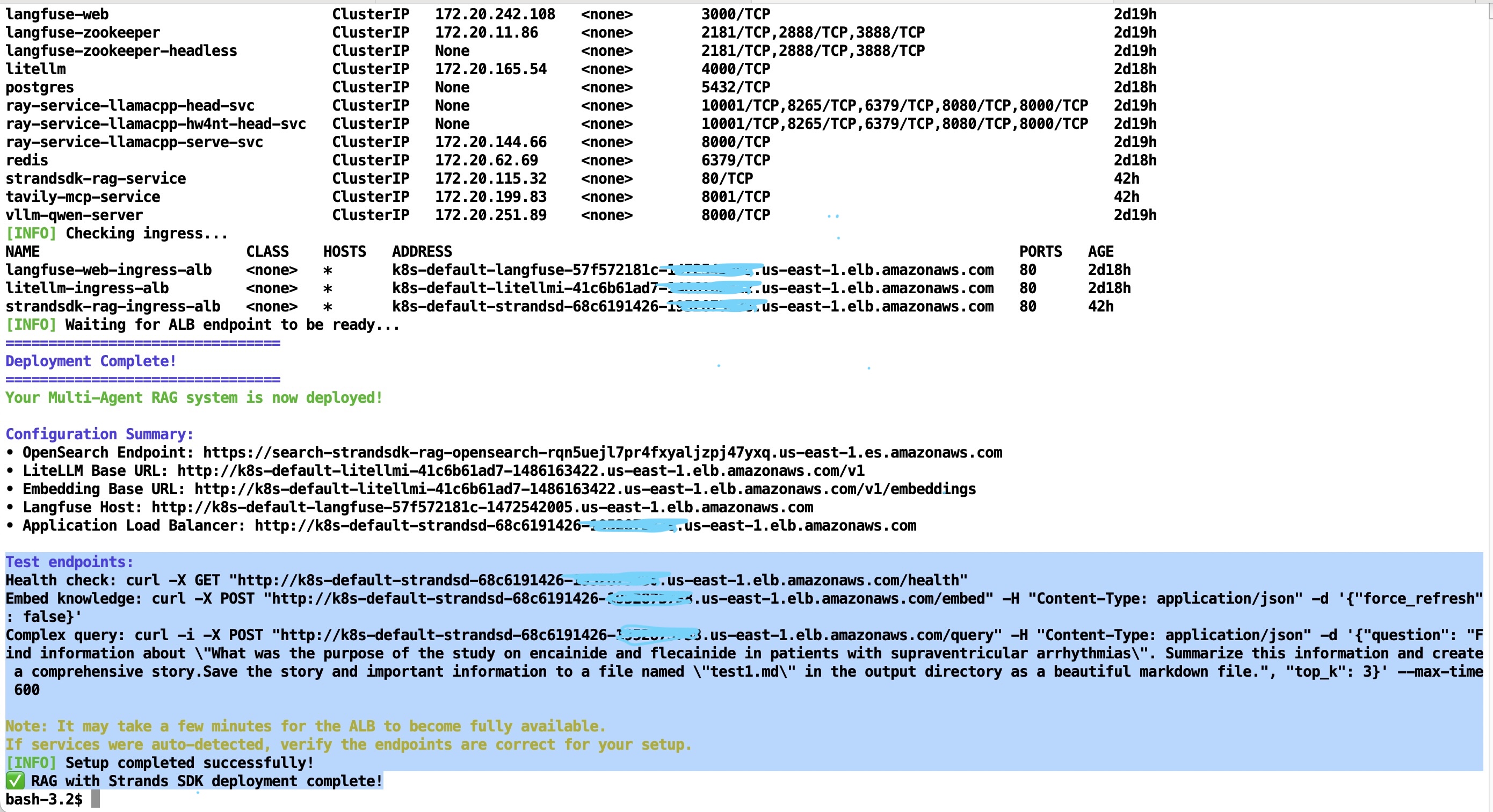
Figure 11: Successful Application stack deployment completion message
Individual Components Installation
Alternatively to make install end-to-end automation, you can run the following make commands one by one to complete the guidance deployment.
# Install specific components as needed
make setup-base # Base EKS infrastructure
make setup-models # Model hosting services
make setup-observability # LangFuse monitoring
make setup-gateway # LiteLLM proxy gateway
make setup-rag-strands # Agentic AI app with Strands Agent SDK
Utility Commands
make help # Show all available targets
make status # Check deployment status
make verify-cluster # Verify EKS cluster access
make clean # Remove all deployments
Option 2: Manual Step-by-Step Setup
If you prefer manual control or need to customize the installation, please follow the steps below:
Verify that AWS Region and profile settings used to provision EKS cluster are in place:
export AWS_REGION=us-east-1 #use your Region value
export AWS_PROFILE=default
Step 1: Set Up EKS Cluster
Provision your EKS cluster following the AWS Solutions Guidance: Automated Provisioning of Application-Ready Amazon EKS Clusters
This guidance provides:
- Automated EKS cluster provisioning with best practices
- Pre-configured EKS add-ons and operators
- Security and networking configurations
- Monitoring and observability setup
NOTE: Please see the Note for Option 1 above for deployment of EKS cluster in Auto Mode and using the the
eks-automodecode branch for Scalable Inference and Agentic AI application installation or “opting out” of Auto Mode and using themaincode branch for applications deployment.
After completing deployment of EKS cluster, confirm your kubectl is configured to access it:
# Verify cluster access
kubectl cluster-info
kubectl get nodes
Step 2: Install Base Infrastructure Components
Navigate to the base setup directory and run the installation script:
cd base_eks_setup
chmod +x install_operators.sh
./install_operators.sh
This script installs:
- KubeRay Operator for distributed model serving
- NVIDIA GPU Operator for GPU workloads
- GP3 storage class for optimized storage
- All Karpenter auto-scaler node pools for different workload types
Step 3: Deploy Model Hosting Services
Set up the model hosting infrastructure:
cd model-hosting
chmod +x setup.sh
./setup.sh
This deploys:
- Ray service with LlamaCPP and embedding capabilities
- Standalone vLLM reasoning service
- Standalone vLLM vision service
- All necessary Kubernetes resources and configurations
Step 4: Set Up Observability
Deploy monitoring and observability tools:
cd model-observability
chmod +x setup.sh
./setup.sh
This installs:
- LangFuse for LLM observability
- Web ingress for external access
- Service monitoring and logging
Important: After deployment, configure LangFuse:
- Access LangFuse web interface
- Create an organization named “test”
- Create a project inside it named “demo”
- navigate to “Tracing” menu and set up tracing
- Record the Public Key (PK) and Secret Key (SK) - you’ll need these for the agentic applications
Step 5: Deploy Model Gateway
Set up the unified API gateway:
cd model-gateway
chmod +x setup.sh
./setup.sh
This deploys:
- LiteLLM proxy deployment
- Load balancer and ingress configuration
- Waits for services to be ready before proceeding
Important: After deployment, configure LiteLLM proxy:
- Access the LiteLLM web interface
- Login with username “admin” and password “sk-123456”
- Navigate to “Virtual Keys” on the sidebar and create a new key
- Mark “All Team Models” for the models field
- Store the generated secret key - you’ll need it for the agentic applications
Right now, let us go through the deployment of an Agentic RAG application based on the Agentic AI platform
Deploy Agentic Applications
Multi-Agent RAG with Strands SDK and OpenSearch
This project implements a sophisticated multi-agent Large Language Model (LLM) system using the Strands SDK that combines Model Context Protocol (MCP) for tool usage and Retrieval Augmented Generation (RAG) for enhanced context awareness, using OpenSearch as the vector database.
The system is built with a modular multi-agent architecture using Strands SDK patterns with built-in OpenTelemetry tracing:
SupervisorAgent (Orchestrator) [with built-in tracing]
├── KnowledgeAgent → Manages knowledge base and embeddings [traced]
├── MCPAgent → Manages tool interactions via MCP protocol [traced]
└── Strands SDK → Provides agent framework, tool integration, and OpenTelemetry tracing
🚀 Key Features
Multi-Agent Orchestration
- SupervisorAgent: Main orchestrator with integrated RAG capabilities using Strands SDK
- KnowledgeAgent: Monitors and manages knowledge base changes
- MCPAgent: Executes tasks using MCP tools and file operations
- Built-in Tracing: All agents include OpenTelemetry tracing via Strands SDK
Advanced RAG Capabilities
- OpenSearch Integration: Vector storage and similarity search
- Embedding Generation: Configurable embedding models and endpoints
- Multi-format Support: Handles markdown, text, JSON, and CSV files
- Intelligent Search: Vector similarity search with metadata and scoring
- Relevance Scoring: Automatic relevance assessment for search results
External Web Search Integration 🌐
- Tavily API Integration: Real-time web search via MCP server
- Automatic Triggering: Web search activated when RAG relevance < 0.3
- News Search: Dedicated recent news and current events search
- Hybrid Responses: Combines knowledge base and web search results
- Smart Fallback: Graceful degradation when web search unavailable
MCP Tool Integration
- Filesystem Operations: Read, write, and manage files using Strands tools
- Web Search Tools: Tavily-powered web and news search capabilities
- Extensible Architecture: Easy to add new MCP servers
- Error Handling: Robust tool execution with fallbacks
- Built-in Tools: Integration with Strands built-in tools
Observability & Tracing
- OpenTelemetry Integration: Native tracing through Strands SDK
- Multiple Export Options: Console, OTLP endpoints, Jaeger, LangFuse
- Automatic Instrumentation: All agent interactions are automatically traced
- Performance Monitoring: Track execution times, token usage, and tool calls
🏃♂️ Usage
Option 1: Container Deployment on Kubernetes - Recommended
For production deployments, use the containerized solution with Kubernetes:
Prerequisites
- Python 3.9+
- EKS cluster
- TAVILY_API_KEY - see documentation here
- AWS credentials configured with administrator level access
- Docker daemon in
runningstatus
Installation
1. Build and Push Container Images
# Navigate to the strandsdk agentic RAG app directory
cd agentic-apps/strandsdk_agentic_rag_opensearch
# Build Docker images and push to ECR
./build-images.sh
# This script will:
# - Create ECR repositories if they don't exist
# - Build main application and MCP server images
# - Push images to ECR
# - Update Kubernetes deployment files with ECR image URLs
2. Deploy OpenSearch Cluster
# Deploy OpenSearch with CloudFormation and EKS Pod Identity
./deploy-opensearch.sh [stack-name] [region] [namespace]
# Example:
./deploy-opensearch.sh strandsdk-rag-opensearch-stack us-east-1 default
# This script will:
# - Deploy OpenSearch cluster via CloudFormation
# - Set up EKS Pod Identity for secure access
# - Create the vector index automatically
# - Configure IAM roles and policies
3. Configure Kubernetes Secrets and ConfigMap
Update the ConfigMap with your actual service endpoints and configuration:
# Apply the ConfigMap and Secrets
kubectl apply -f k8s/configmap.yaml
# Edit the ConfigMap with your actual values
kubectl edit configmap app-config
# Key values to update:
# - LITELLM_BASE_URL: Your LiteLLM service endpoint
# - EMBEDDING_BASE_URL: Your embedding service endpoint
# - OPENSEARCH_ENDPOINT: From OpenSearch deployment output
# - LANGFUSE_HOST: Your LangFuse instance (optional)
Update secrets with your API keys:
# Update secrets with base64 encoded values
kubectl edit secret app-secrets
# To encode your keys:
echo -n "your-api-key" | base64
# Keys to update:
# - litellm-api-key: Your LiteLLM API key
# - embedding-api-key: Your embedding service API key
# - tavily-api-key: Your Tavily API key for web search
# - langfuse-public-key: LangFuse public key (optional)
# - langfuse-secret-key: LangFuse secret key (optional)
4. Deploy Kubernetes Applications
# Apply the service account (if not already created)
kubectl apply -f k8s/service-account.yaml
# Deploy the MCP server first
kubectl apply -f k8s/tavily-mcp-deployment.yaml
# Deploy the main application
kubectl apply -f k8s/main-app-deployment.yaml
# Check deployment status
kubectl get pods -l app=tavily-mcp-server
kubectl get pods -l app=strandsdk-rag-app
# Check services and ingress
kubectl get svc
kubectl get ingress
5. Test the Deployed System
# Get the Application Load Balancer endpoint
ALB_ENDPOINT=$(kubectl get ingress strandsdk-rag-ingress-alb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
# Test the health endpoint
curl -X GET "http://${ALB_ENDPOINT}/health"
# Test a simple query
curl -X POST "http://${ALB_ENDPOINT}/query" \
-H "Content-Type: application/json" \
-d '{
"query": "What is Bell'\''s palsy?",
"include_web_search": true
}'
# Test knowledge embedding
curl -X POST "http://${ALB_ENDPOINT}/embed-knowledge" \
-H "Content-Type: application/json"
# Test with a more complex medical query
curl -X POST "http://${ALB_ENDPOINT}/query" \
-H "Content-Type: application/json" \
-d '{
"question": "Find information about \"What was the purpose of the study on encainide and flecainide in patients with supraventricular arrhythmias\". Summarize this information and create a comprehensive story.Save the story and important information to a file named \"test1.md\" in the output directory as a beautiful markdown file.",
"top_k": 3
}' \
--max-time 600
Option 2: Local Development
Prerequisites
- Python 3.9+
- EKS cluster
- TAVILY_API_KEY
- Public facing OpenSearch cluster
- AWS credentials configured with administrator access
Installation
# Navigate to the strandsdk agentic app directory
cd agentic-apps/strandsdk_agentic_rag_opensearch
# Create virtual environment
python3 -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install dependencies
pip install -r requirements.txt
# Set up environment variables
cp .env.example .env
# Edit .env with your configuration
Configuration
Create a .env file with the following variables:
# OpenAI Configuration
OPENAI_API_KEY=your-openai-api-key
OPENAI_BASE_URL=https://api.openai.com/v1
DEFAULT_MODEL=us.anthropic.claude-3-7-sonnet-20250219-v1:0
# AWS Configuration
AWS_REGION=us-east-1
OPENSEARCH_ENDPOINT=https://your-opensearch-domain.region.es.amazonaws.com
# Tavily Web Search Configuration
TAVILY_API_KEY=your-tavily-api-key
# Tracing Configuration (Optional)
OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4318
OTEL_EXPORTER_OTLP_HEADERS=key1=value1,key2=value2
STRANDS_OTEL_ENABLE_CONSOLE_EXPORT=true
# Optional: LangFuse for observability
LANGFUSE_HOST=https://cloud.langfuse.com
LANGFUSE_PUBLIC_KEY=your-public-key
LANGFUSE_SECRET_KEY=your-secret-key
# Application Settings
KNOWLEDGE_DIR=knowledge
OUTPUT_DIR=output
VECTOR_INDEX_NAME=knowledge-embeddings
TOP_K_RESULTS=5
Deploy
1. Start Tavily MCP Server (for Web Search)
# Start the Tavily web search server
python scripts/start_tavily_server.py
# Or run directly
python src/mcp_servers/tavily_search_server.py
2. Embed Knowledge Documents
# Process and embed all knowledge documents
python -c "from src.agents.knowledge_agent import knowledge_agent; print(knowledge_agent('Please embed all knowledge files'))"
3. Run the Multi-Agent System
# Standard mode (with built-in tracing)
source venv/bin/activate
python -m src.main
# Clean mode (async warnings suppressed)
python run_main_clean.py
# Single query - standard mode
python -c "from src.main import run_single_query; print(run_single_query('What is Bell\'s palsy?'))"
# Single query - clean mode
python run_single_query_clean.py "What is Bell's palsy?"
# Single query - ultra clean mode (completely suppressed stderr)
python run_completely_clean.py "What is Bell's palsy?"
4. Test the System
# Run comprehensive tests including web search integration
python -m src.test_agents
# Test the enhanced RAG system with chunk relevance evaluation
python test_enhanced_rag.py
# Test web search integration specifically
python src/test_web_search_integration.py
# Run tests with clean output (async warnings filtered)
python run_clean_test.py
Note: The enhanced system uses RAGs for chunk relevance evaluation, which may generate harmless async cleanup warnings. Use
run_clean_test.pyfor a cleaner testing experience.
Container Features
- Auto-scaling: Kubernetes HPA for dynamic scaling
- Health Checks: Built-in health endpoints for monitoring
- Service Discovery: Internal service communication via Kubernetes DNS
- Security: EKS Pod Identity for secure AWS service access
- Observability: OpenTelemetry tracing with multiple export options
- Load Balancing: ALB for external traffic distribution
- Configuration Management: ConfigMaps and Secrets for environment-specific settings
🔍 Observability & Tracing
The system includes comprehensive observability through Strands SDK’s built-in OpenTelemetry integration:
Automatic Tracing
- All agents are automatically traced using Strands SDK
- Tool calls, LLM interactions, and workflows are captured
- Performance metrics including token usage and execution times
Trace Export Options
- Console Output: Set
STRANDS_OTEL_ENABLE_CONSOLE_EXPORT=truefor development - OTLP Endpoint: Configure
OTEL_EXPORTER_OTLP_ENDPOINTfor production - LangFuse: Use LangFuse credentials for advanced observability
- Jaeger/Zipkin: Compatible with standard OpenTelemetry collectors
Local Development Setup
# Pull and run Jaeger all-in-one container
docker run -d --name jaeger \
-e COLLECTOR_OTLP_ENABLED=true \
-p 16686:16686 \
-p 4317:4317 \
-p 4318:4318 \
jaegertracing/all-in-one:latest
# Access Jaeger UI at http://localhost:16686
🧠 Agent Workflows
Knowledge Management Workflow
- File Monitoring: Scans knowledge directory for changes
- Change Detection: Uses file hashes and timestamps
- Document Processing: Handles multiple file formats
- Embedding Generation: Creates vector embeddings
- Vector Storage: Stores in OpenSearch with metadata
RAG Retrieval Workflow
- Query Processing: Analyzes user queries
- Embedding Generation: Converts queries to vectors
- Similarity Search: Finds relevant documents in OpenSearch
- Context Formatting: Structures results for LLM consumption
- Relevance Ranking: Orders results by similarity scores
MCP Tool Execution Workflow
- Tool Discovery: Connects to available MCP servers
- Context Integration: Combines RAG context with user queries
- Tool Selection: Chooses appropriate tools for tasks
- Execution Management: Handles tool calls and responses
- Result Processing: Formats and returns final outputs
🔧 Extending the System
Adding New Agents
from strands import Agent, tool
from src.utils.strands_langfuse_integration import create_traced_agent
# Define tools for the agent
@tool
def my_custom_tool(param: str) -> str:
"""Custom tool implementation."""
return f"Processed: {param}"
# Create the agent with built-in tracing
my_agent = create_traced_agent(
Agent,
model="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
tools=[my_custom_tool],
system_prompt="Your specialized prompt here",
session_id="my-agent-session",
user_id="system"
)
Adding New MCP Servers
from fastmcp import FastMCP
mcp = FastMCP("My Custom Server")
@mcp.tool(description="Custom tool description")
def my_custom_tool(param: str) -> str:
"""Custom tool implementation."""
return f"Processed: {param}"
if __name__ == "__main__":
mcp.run(transport="streamable-http", port=8002)
📊 Monitoring and Observability
The system includes comprehensive observability features:
- OpenTelemetry Integration: Native tracing through Strands SDK
- Multiple Export Options: Console, OTLP endpoints, Jaeger, LangFuse
- Workflow Summaries: Detailed execution reports
- Performance Metrics: Duration and success tracking
- Error Handling: Comprehensive error reporting and recovery
🧪 Example Use Cases
Medical Knowledge Query
query = "What are the symptoms and treatment options for Bell's palsy?"
result = supervisor_agent(query)
print(result['response'])
Document Analysis and Report Generation
query = "Analyze the medical documents and create a summary report saved to a file"
result = supervisor_agent(query)
# System will retrieve relevant docs, analyze them, and save results using MCP tools
🔍 Architecture Benefits
- Modularity: Each agent has specific responsibilities
- Scalability: Agents can be scaled independently
- Reliability: Isolated failures don’t affect the entire system
- Extensibility: Easy to add new capabilities
- Observability: Comprehensive monitoring and tracing via Strands SDK
- Standards Compliance: Uses MCP for tool integration and OpenTelemetry for tracing
🔧 Key Improvements
Unified Architecture
- Single Codebase: No separate “enhanced” versions - all functionality is built into the standard agents
- Built-in Tracing: OpenTelemetry tracing is automatically enabled through Strands SDK
- Simplified Deployment: One main application with all features included
- Consistent API: All agents use the same tracing and configuration patterns
Enhanced Developer Experience
- Automatic Instrumentation: No manual trace management required
- Multiple Export Options: Console, OTLP, Jaeger, LangFuse support out of the box
- Environment-based Configuration: Easy setup through environment variables
- Clean Code Structure: Removed duplicate wrapper functions and complex manual tracing
- Async Warning Management: Clean test runner filters harmless async cleanup warnings
- Robust Error Handling: Fallback mechanisms ensure system reliability
Uninstall the Guidance
You can uninstall the “Guidance for Scalable Model Inference and Agentic AI on Amazon EKS” from the AWS Management Console or by using the AWS Command Line Interface. The most reliable way to perform an uninstall of this guidance resources is by running the following command:
make clean
if uninstall works fine your should see the following lines at the end:
...
pod "redis-59c756bbd4-bvp8r" force deleted
🗑️ Removing Helm repositories...
helm repo remove kuberay 2>/dev/null || true
helm repo remove nvidia 2>/dev/null || true
helm repo remove langfuse 2>/dev/null || true
....
✅ Comprehensive cleanup complete!
ℹ️ >Note: Some AWS Load Balancers and EBS volumes may take additional time to be cleaned up by AWS.
ℹ️ Check your AWS console to verify all resources have been properly removed.
ℹ️ Karpenter-managed nodes will be automatically terminated
An output like shown above should confirm uninstallation of the guidance from your AWS account
Related resources
- AWS EKS documentation
- AWS OpenSearch documentation
- AWS Graviton documentation
- KubeRay documentation
- Strands Agents documentation
- LangFuse Documentation
- LiteLLM project documentation
Contributors
- Vincent Wang, Solutions Architect, GTM Efficient Compute ANZ
- Daniel Zilberman, Sr. Solutions Architect, Technical Solutions
Notices
Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents AWS current product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. AWS responsibilities and liabilities to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers.