Guidance for Automated Provisioning of Application-Ready Amazon EKS Clusters
Summary: This implementation guide provides an overview of the Guidance for Automated Provisioning of Application-Ready Amazon EKS Clusters, its reference architecture and components, considerations for planning the deployment, and configuration steps for deploying the sample code to Amazon Web Services (AWS). This guide is intended for solution architects, business decision makers, DevOps engineers, and cloud professionals who want to implement Guidance for Automated Provisioning of Application-Ready Amazon EKS Clusters in their environment.
Overview
The Guidance for Automated Provisioning of Application-Ready Amazon EKS Clusters is a collection of reference implementations for Amazon Elastic Kubernetes Service (EKS) designed to accelerate time it takes to launch a production workload-ready EKS cluster. It includes an “opinionated” set of pre-configured and integrated tools/add-ons, and follows best practices to support core capabilities including Autoscaling, Observability, Networking and Security.
This guidance addresses the following key points:
- Provides a simplified process for setting up an workoad-ready EKS cluster.
- Includes pre-configured tools and add-ons to support essential capabilities, including an option for automated EKS management with EKS AutoMode
- Aims to reduce the learning curve associated with deploying the first application-ready EKS cluster.
- Allows users to focus on deploying and testing applications rather than cluster setup.
The motivation behind this project is to accelerate and simplify the process of setting up a cluster that is ready to support applications and workloads. We’ve heard from customers that there can be a learning curve associated with deploying your first application ready EKS cluster. This project aims to simplify the undifferentiated lifting, allowing you to focus on deploying and testing your applications.
Features and Benefits
Single Cluster Deployment: Deploy one Amazon EKS cluster per environment in a single account, simplifying management and reducing complexity for users new to Kubernetes.
Ready-to-Use Configuration: Receive a pre-configured cluster with opinionated yet customizable tooling, accelerating the setup process and reducing the learning curve for containerization beginners.
Environment-Specific Customization: Easily tailor cluster configurations for different environments (e.g.
dev,staging,prod,automode), enabling flexible and consistent multi-environment setups.Integrated Tooling: Benefit from pre-integrated tools and add-ons that support core capabilities like Autoscaling, Observability, Networking, and Security, reducing the time and expertise needed to set up a production-ready EKS cluster.
Best Practices Implementation: Automatically apply AWS and Kubernetes best practices, enhancing security, performance, and cost-efficiency without requiring deep expertise.
Terraform-Based Deployment: Utilize IBM HashiCorp Terraform for infrastructure-as-code deployment, ensuring reproducibility and easier management of cluster configurations across environments.
This reference implementation is designed for customers that require a simple ready-to-use cluster, configured with a set of opinionated (yet configurable to some extent) tooling deployed alongside the cluster itself. Those customer profiles include:
- Organizations in the early stages of containerization/Kubernetes adoption looking for a simplified deployment to run their applications
- Teams with limited resources to manage cluster configurations
- Projects with applications that can be deployed in a single cluster
- Business units within an organization that need to deploy a multi-environment cluster for their specific workloads
Use Cases
Accelerating Initial Kubernetes Adoption Streamlining the transition to containerization for organizations new to Kubernetes/EKS. This use case addresses organizations in the early stages of adopting containerization and Kubernetes. The reference implementation provides a pre-configured, production-ready EKS cluster, reducing the complexity of initial setup. It allows teams to focus on application containerization rather than cluster configuration, accelerating the path to leveraging containerized workloads.
Optimizing DevOps Resources in Early Kubernetes Adoption Stages Enabling efficient cluster management for teams new to Kubernetes operations. For organizations in the early phases of Kubernetes adoption, DevOps teams often need to balance learning new technologies with maintaining existing systems. This implementation offers a pre-configured EKS cluster with best practices in security and scalability. It reduces the initial operational burden, allowing teams to gradually build Kubernetes expertise while maintaining productivity.
Simplified Single-Cluster Deployment for Initial Projects Providing a streamlined infrastructure for initial Kubernetes applications. This use case caters to teams deploying their first applications on Kubernetes. The reference implementation offers a robust, single-cluster environment per development stage. It’s ideal for initial projects that need containerization benefits without multi-cluster complexity, allowing teams to start small and scale as they gain experience.
Consistent Multi-Environment Setup for Kubernetes Newcomers Facilitating uniform cluster deployments across dev, staging, and production for teams new to Kubernetes. For organizations setting up their first Kubernetes environments, maintaining consistency across development stages is crucial. This implementation uses Terraform and environment-specific configurations to ensure identical setups across dev, staging, and production. It helps teams new to Kubernetes establish a solid foundation for their development pipeline from the start.
Adopting Terraform and AWS Best Practices for Amazon EKS Implementing infrastructure-as-code and AWS-recommended configurations for EKS deployments. This use case is tailored for organizations aiming to adopt or improve their DevOps practices using Terraform while leveraging AWS best practices for EKS. The reference implementation provides a Terraform-based deployment that incorporates AWS-recommended configurations for EKS. It allows teams to quickly implement infrastructure-as-code methodologies, ensuring reproducibility and version control of their EKS environments. Simultaneously, it applies AWS best practices, optimizing security, performance, and cost-efficiency. This approach enables companies to accelerate their DevOps transformation while ensuring their EKS deployments align with industry standards and AWS expertise.
Architecture Overview
This section provides a reference implementation architecture diagram for the components deployed with this Guidance.
At its core, the guidance deploys an Amazon EKS cluster within a custom Amazon VPC. This VPC is configured with public and private subnets across multiple Availability Zones for high availability and resilience.
Key elements of the architecture include:
- Amazon VPC: A custom VPC with public and private subnets, providing network isolation and security.
- Amazon EKS Cluster: The central component, managing the Kubernetes control plane and compute nodes
- EKS Managed Node Groups: Auto-scaling groups of EC2 instances that serve as EKS compute nodes.
- Amazon Identity & Access Management: Integrated with EKS for fine-grained access control.
- Amazon Elastic Container Registry (ECR): For storing and managing container images.
- AWS Load Balancer Controller: Automatically provisions Application Load Balancers or Network Load Balancers when a Kubernetes service of type LoadBalancer is created.
- Observability Tools: Amazon CloudWatch, Amazon Managed Grafana, and Amazon Managed Service for Prometheus for comprehensive monitoring and logging.
- Terraform Resources: Representing infrastructure-as-code components that define and provision the guidance architecture.
This architecture is designed to provide a secure, scalable, and easily manageable EKS environment, incorporating AWS best practices and ready for production workloads.
Architecture diagram
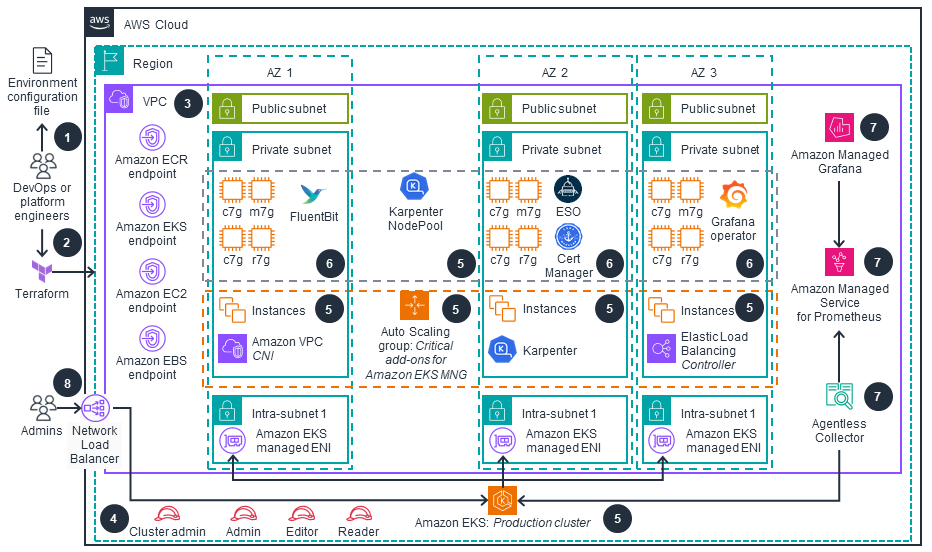
Figure 1: Application-Ready Amazon EKS Cluster Reference Architecture
Architecture Steps
DevOps engineer defines a per-environment Terraform variable file that controls all of the environment-specific configuration. This variable file is used in every step of the process by all IaC configurations.
DevOps engineer applies the per-environment configuration using Terraform following the deployment process defined in the guidance.
An Amazon Virtual Private Cloud (VPC) is provisioned and configured based on specified configuration. According to best practices for Reliability, 3 Availability Zones (AZs) are configured with VPC Endpoints for access to resources deployed in private VPCs. Provisioned resources for private clusters, including Amazon Elastic Container Registry (ECR), Amazon EKS, Amazon Elastic Compute Cloud (Amazon EC2), and Amazon Elastic Block Store (EBS) are available via corresponding VPC endpoints.
User-facing AWS Identity and Access Management (IAM) roles (Cluster Admin, Admin, Editor and Reader) are created for various access levels to EKS cluster resources, as recommended in Kubernetes security best practices.
Amazon Elastic Kubernetes Service (EKS) cluster is provisioned with Managed Node Groups that host critical cluster add-ons (CoreDNS, AWS Load Balancer Controller and Karpenter) on its compute node instances. Karpenter is an auto-scaler that manages compute capacity for other add-ons, as well as workloads that will be deployed by users while prioritizing provisioning AWS Graviton based compute node instances for the best price-performance.
NOTE: In case of EKS AutoMode enabled, Karpenter auto-scaler as well as other important EKS add-ons are available via managed options and do not need to be installed separately.
Other relevant EKS add-ons are provisioned based on the configurations defined in the per-environment Terraform configuration file.
AWS OSS Observability stack is deployed if configured, including Amazon Managed Service for Prometheus (AMP), AWS Managed Collector for Amazon EKS, and Amazon Managed Grafana (AMG). In addition, a Grafana-operator addon is deployed alongside a set of predefined Grafana dashboards to get started.
Amazon EKS cluster(s) with critical add-ons, configured managed Observability stack and RBAC based security mapped to IAM roles is available for workload deployment and its Kubernetes API is accessible via an AWS Network Load Balancer.
AWS Services in this Guidance
AWS Services used in this Guidance
| AWS Service | Role | Description |
|---|---|---|
| Amazon Elastic Kubernetes Service ( EKS) | Core service | Manages the Kubernetes control plane and worker nodes for container orchestration. |
| Amazon Elastic Compute Cloud (EC2) | Core service | Provides the compute instances for EKS worker nodes and runs containerized applications. |
| Amazon Virtual Private Cloud (VPC) | Core Service | Creates an isolated network environment with public and private subnets across multiple Availability Zones. |
| Amazon Elastic Container Registry (ECR) | Supporting service | Stores and manages Docker container images for EKS deployments. |
| Elastic Load Balancing (NLB) | Supporting service | Distributes incoming traffic across multiple targets in the EKS cluster. |
| Amazon Elastic Block Store (EBS) | Supporting service | Provides persistent block storage volumes for EC2 instances in the EKS cluster. |
| AWS Identity and Access Management (IAM) | Supporting service | Manages access to AWS services and resources securely, including EKS cluster access. |
| Amazon Managed Grafana (AMG) | Observability service | Provides fully managed service for metrics visualization and monitoring. |
| Amazon Managed Service for Prometheus (AMP) | Observability service | Offers managed Prometheus-compatible monitoring for container metrics. |
| AWS Certificate Manager (ACM) | Security service | Manages SSL/TLS certificates for secure communication within the cluster. |
| Amazon CloudWatch | Monitoring service | Collects and tracks metrics, logs, and events from EKS and other AWS resources provisoned in the guidance |
| AWS Systems Manager | Management service | Provides operational insights and takes action on AWS resources. |
| AWS Key Management Service (KMS) | Security service | Manages encryption keys for securing data in EKS and other AWS services. |
Plan your deployment
Cost
You are responsible for the cost of the AWS services used while running this guidance. As of August 2024, the cost for running this guidance with the default settings in the US East (N. Virginia) Region is approximately $447.47/month.
We recommend creating a budget through AWS Cost Explorer to help manage costs. Prices are subject to change. For full details, refer to the pricing webpage for each AWS service used in this guidance.
Sample cost table
The following table provides a sample cost breakdown for deploying this guidance with the default parameters in the us-east-1 (N. Virginia) Region for one month. This estimate is based on the AWS Pricing Calculator output for the full deployment as per the guidance.
| AWS service | Dimensions | Cost, month [USD] |
|---|---|---|
| Amazon EKS | 1 cluster | $73.00 |
| Amazon VPC | 3 NAT Gateways | $98.67 |
| Amazon EC2 | 2 m6g.large instances | $112.42 |
| Amazon Managed Service for Prometheus (AMP) | Metric samples, storage, and queries | $100.60 |
| Amazon Managed Grafana (AMG) | Metrics visualization - Editor and Viewer users | $14.00 |
| Amazon EBS | gp2 storage volumes and snapshots | $17.97 |
| Application Load Balancer | 1 ALB for workloads | $16.66 |
| Amazon VPC | Public IP addresses | $3.65 |
| AWS Key Management Service (KMS) | Keys and requests | $7.00 |
| Amazon CloudWatch | Metrics | $3.00 |
| Amazon ECR | Data storage | $0.50 |
| TOTAL | $447.47/month |
For a more accurate estimate based on your specific configuration and usage patterns, we recommend using the AWS Pricing Calculator.
Security
When you build systems on AWS infrastructure, security responsibilities are shared between you and AWS. This shared responsibility model reduces your operational burden because AWS operates, manages, and controls the components including the host operating system, the virtualization layer, and the physical security of the facilities in which the services operate. For more information about AWS security, visit AWS Cloud Security.
This guidance implements several security best practices and AWS services to enhance the security posture of your EKS Workload Ready Cluster. Here are the key security components and considerations:
Identity and Access Management (IAM)
- IAM Roles: The architecture uses predefined IAM roles (Cluster Admin, Admin, Edit, Read) to manage access to the EKS cluster resources. This follows the principle of least privilege, ensuring users and services have only the permissions necessary to perform their tasks.
- EKS Managed Node Groups: These use IAM roles with specific permissions required for nodes to join the cluster and for pods to access AWS services.
Network Security
- Amazon VPC: The EKS cluster is deployed within a custom VPC with public and private subnets across multiple Availability Zones, providing network isolation.
- Security Groups: Although not explicitly shown in the diagram, security groups are typically used to control inbound and outbound traffic to EC2 instances and other resources within the VPC.
- NAT Gateways: Deployed in public subnets to allow outbound internet access for resources in private subnets while preventing inbound access from the internet.
Data Protection
- Amazon EBS Encryption: EBS volumes used by EC2 instances are typically encrypted to protect data at rest.
- AWS Key Management Service (KMS): Used for managing encryption keys for various services, including EBS volume encryption.
Kubernetes-specific Security
- Kubernetes RBAC: Role-Based Access Control is implemented within the EKS cluster to manage fine-grained access to Kubernetes resources.
- AWS Certificate Manager: Integrated to manage SSL/TLS certificates for secure communication within the cluster.
Monitoring and Logging
- Amazon CloudWatch: Used for monitoring and logging of AWS resources and applications running on the EKS cluster.
- Amazon Managed Grafana and Prometheus: Provide additional monitoring and observability capabilities, helping to detect and respond to security events.
Container Security
- Amazon ECR: Stores container images in a secure, encrypted repository. It includes vulnerability scanning to identify security issues in your container images.
Secrets Management
- AWS Secrets Manager: While not explicitly shown in the diagram, it’s commonly used to securely store and manage sensitive information such as database credentials, API keys, and other secrets used by applications running on EKS.
Additional Security Considerations
- Regularly update and patch EKS clusters, worker nodes, and container images.
- Implement network policies to control pod-to-pod communication within the cluster.
- Use Pod Security Policies or Pod Security Standards to enforce security best practices for pods.
- Implement proper logging and auditing mechanisms for both AWS and Kubernetes resources.
- Regularly review and rotate IAM and Kubernetes RBAC permissions.
Supported AWS Regions
The core components of “Guidance for Automated Provisioning of Application-Ready Amazon EKS Clusters” are available in all AWS Regions where Amazon EKS service is supported.
The observability components of this guidance use Amazon Managed Service for Prometheus (AMP) and Amazon Managed Grafana (AMG). These services are available in the following regions (as of September 2025):
| Region Name | Region Code |
|---|---|
| US East (N. Virginia) | us-east-1 |
| US East (Ohio) | us-east-2 |
| US West (Oregon) | us-west-2 |
| Asia Pacific (Mumbai) | ap-south-1 |
| Asia Pacific (Seoul) | ap-northeast-2 |
| Asia Pacific (Singapore) | ap-southeast-1 |
| Asia Pacific (Sydney) | ap-southeast-2 |
| Asia Pacific (Tokyo) | ap-northeast-1 |
| Europe (Frankfurt) | eu-central-1 |
| Europe (Ireland) | eu-west-1 |
| Europe (London) | eu-west-2 |
| Europe (Paris) | eu-west-3 |
| Europe (Stockholm) | eu-north-1 |
| South America (São Paulo) | sa-east-1 |
| Greater China (Beijing) | cn-north-1 |
| Greater China (Ningxia) | cn-northwest-1 |
| GovCloud region (US-west) | us-gov-west-1 |
| GovCloud region (US-east) | us-gov-east-1 |
Regions Supporting Core Components Only
The core components of this guidance can be deployed in any AWS Region where Amazon EKS is available.
For the most current availability of AWS services by Region, refer to the AWS Regional Services List.
NOTE: If you deploy this guidance into a region where AMP and/or AMG are not available, you can disable the OSS observability tooling (AMP, AMG) during deployment. This allows you to use the core components of the guidance without built-in observability features. Configuration of
.tfvarsfile for that case is shown below:
...
observability_configuration = {
aws_oss_tooling = false
aws_native_tooling = true
aws_oss_tooling_config = {
enable_managed_collector = false
enable_adot_collector = false
prometheus_name = "prom"
enable_grafana_operator = false
}
}
Service Quotas
Service quotas, also referred to as limits, are the maximum number of service resources or operations for your AWS account.
Quotas for AWS services in this Guidance
Ensure you have sufficient quota for each of the AWS services utilized in this guidance. For more details, refer to AWS service quotas.
If you need to view service quotas across all AWS services within the documentation, you can conveniently access this information in the Service endpoints and quotas page in the PDF.
For specific implementation quotas, consider the following key components and services used in this guidance:
- Amazon EKS: Ensure that your account has sufficient quotas for Amazon EKS clusters, node groups, and related resources.
- Amazon EC2: Verify your EC2 instance quotas, as EKS node groups rely on these.
- Amazon VPC: Check your VPC quotas, including subnets and Elastic IPs, to support the networking setup.
- Amazon EBS: Ensure your account has sufficient EBS volume quotas for persistent storage.
- IAM Roles: Verify that you have the necessary quota for IAM roles, as these are critical for securing your EKS clusters.
- AWS Systems Manager: Review the quota for Systems Manager resources, which are used for operational insights and management.
- AWS Secrets Manager: If you’re using Secrets Manager for storing sensitive information, ensure your quota is adequate.
Deploy the Guidance
Prerequisites
Before deploying this guidance, please ensure you have met the following prerequisites:
AWS Account and Permissions: Ensure you have an active AWS account with appropriate permissions to create and manage AWS resources like Amazon EKS, EC2, IAM, and VPC.
AWS CLI and Terraform Installation: Install and configure the AWS CLI and Terraform tools on your local machine.
Makefile Setup: This guidance uses a
Makefileto automate various tasks related to managing the Terraform infrastructure. Ensuremakeutility is installed on your system.S3 Bucket and DynamoDB Table: Set up an S3 bucket and DynamoDB table for storing Terraform state and providing a locking mechanism for managing deployments across environments.
Environment Variables: Set the required environment variables, including
AWS_REGIONandAWS_PROFILE, to specify the AWS region and profile for deployment.VPC and Network Configuration: Ensure that you have a VPC configuration ready or are prepared to deploy a new VPC as part of this guidance, with public and private subnets across multiple Availability Zones.
IAM Roles: Define and configure the necessary IAM roles and policies required for accessing the Amazon EKS cluster and related resources.
Observability Tools (Optional): If using the AWS OSS observability stack, ensure the necessary services like Amazon Managed Service for Prometheus and Amazon Managed Grafana are configured. Since AMG uses IAM Identity Center to provide authentication to its Workspace, you’ll have to enable IAM Identity center before deploying this pattern.
For further examples, refer to Dynamic Object and Rule Extensions for AWS Network Firewall and Scale-Out Computing on AWS.
Deployment process overview
Before launching the guidance, review the cost, architecture, security, and other considerations discussed in this guide. Follow these step-by-step instructions to configure and deploy the guidance into your account.
NOTE: Time to deploy: Approximately 25-35 minutes
Step-by-Step Deployment Instructions
Step 1 - Deploy the Terraform resources for state management
Initialize and apply the Terraform configuration in the root directory single-account-single-cluster-multi-env to set up the backend (S3 bucket and DynamoDB table) for Terraform state management.
export AWS_REGION=us-east-1
export AWS_PROFILE=default
make bootstrap
Step 2 - Configure environments for deployment
Define the environments you want to deploy (e.g., automode, dev, staging, prod) by creating configuration files for each environment in the 00.global/vars/ directory. This guidance includes sample configuration file named example.tfvars and files for dev, prod and automode environments.
Configurable Variables:
This pattern uses a global configurable variable file per environment to customize environment-specific objects for different environments. The variables are documented in the configuration file under the 00.global/var/base-env.tfvars file.
Instead of configuring flags for provisioning resources, this pattern uses use-case-driven flags that result in a complete configuration for a collection of deployments, services, and configurations. For example, setting observability_configuration.aws_oss_tooling = true will result in provisioning the relevant AWS resources (such as AMP and AMG) as well as the configurations that connect them together.
Step 3 - Deploy the environment
Deploy the environment based on the configuration defined in the previous step by running the apply-all against selected Makefile target. To deploy a cluster with the recommended EKS AutoMode which is configured in this automode.tfvars file, please run the following command:
export AWS_REGION=us-east-1
export AWS_PROFILE=default
make ENVIRONMENT=automode apply-all
Deploying the pattern:
This pattern relies on Terraform configurations residing in multiple folders (such as 10.networking, 20.iam-roles-for-eks, 30.eks, and 40.observability). Each folder that holds a Terraform configuration also contains a backend.tf Terraform configuration file used to indicate the backend S3 prefix key.
Before deploying the entire cluster configuration, this pattern uses Amazon S3 and Amazon DynamoDB to store the Terraform state of all resources across environments and provide a locking mechanism. The deployment of the S3 Bucket and the DynamoDB table is configured under the root environment folder.
- Default S3 bucket name:
tfstate-<AWS_ACCOUNT_ID> - Default DynamoDB table name:
tfstate-lock
Several environment variables must be set before running any target:
AWS_REGION: Specify the AWS region to run onAWS_PROFILE: The AWS account configuration profile to be used
Step 4 - Deploy a specific module
To deploy a specific module, specify a MODULE variable before the Makefile target. Below is the example of deploying a 10.networking module in defined dev environment:
export AWS_REGION=us-east-1
export AWS_PROFILE=default
make ENVIRONMENT=dev MODULE=10.networking apply
Makefile Targets:
We are using a Makefile utility that is designed to automate various tasks related to managing the Terraform infrastructure. It provides several targets (or commands) to handle different aspects of the Terraform workflow:
bootstrap: Initializes and applies the Terraform configuration in the00.global/varsdirectory, which is assumed to be responsible for setting up the backend (S3 bucket and DynamoDB table) for state management.init-all: Initializes all Terraform modules by calling theinittarget for each module.plan-all: Runs theplantarget for all Terraform modules.apply-all: Runs theapplytarget for all Terraform modules.plan: Runs theterraform plancommand for a specific module.apply: Runs theterraform applycommand for a specific module.
Step 5 (optional) - Deploy Observability OSS tooling for Amazon EKS Cluster
This part of this pattern helps you to monitor your Amazon Elastic Kubernetes Service (Amazon EKS) cluster with the AWS Observability tooling for OSS tooling. This includes the following resources:
- Amazon Managed Service for Prometheus for storing metrics (AMP)
- Amazon Managed Service for Prometheus Managed Collector
- Amazon Managed Grafana - for metrics visualization (AMG)
- AWS Identity Store user - this is a prerequisite to authenticate to an Amazon Managed Grafana workspace
- grafana-operator - this operator allows admin to manage grafana data-source, dashboards, and other configuration directly from Kubernetes using Custom-Resources
- Observability specific addons - Prometheus node-exporter and kube-state-metrics
Using Observability Services Deployed by this Guidance
AMP
To access AMP Workspace, you’ll have to use awscurl as guided in the docs. At the bottom of this page, there’s a troubleshooting section with useful commands.
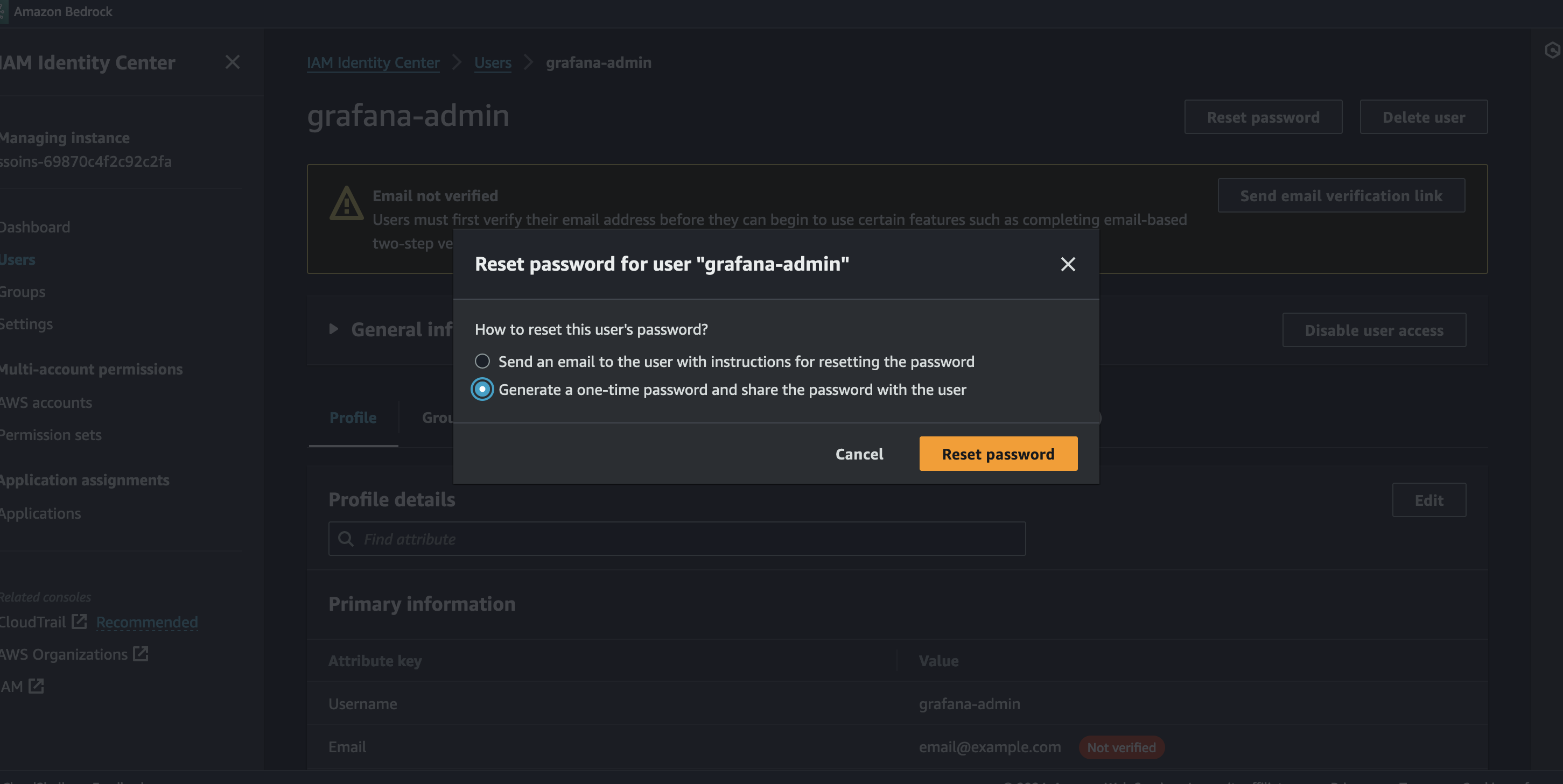
AMG
Since AMG uses IAM Identity Center to provide authentication to the AMG workspace, and since this automation deploys a default grafana-admin user that is allowed to access the workspace, you’ll need to reset its password through the console. See the image below:
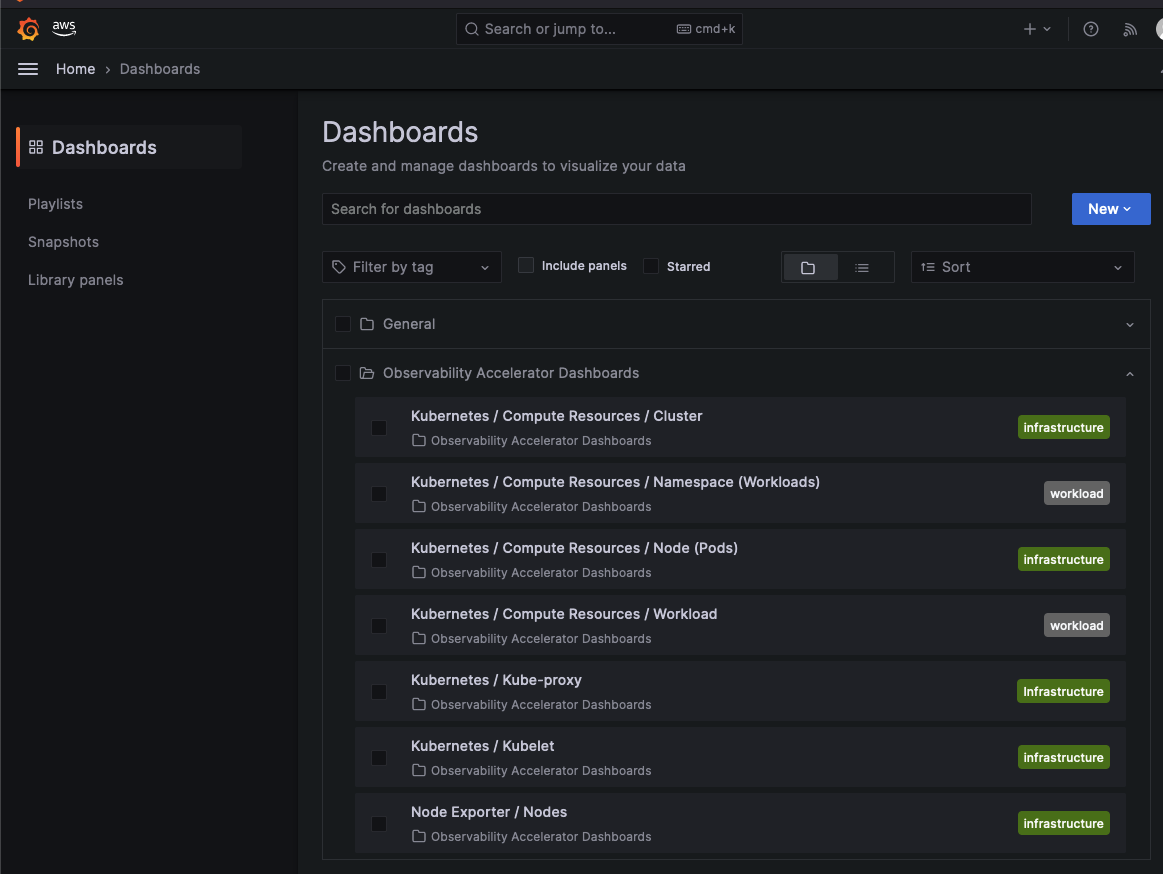
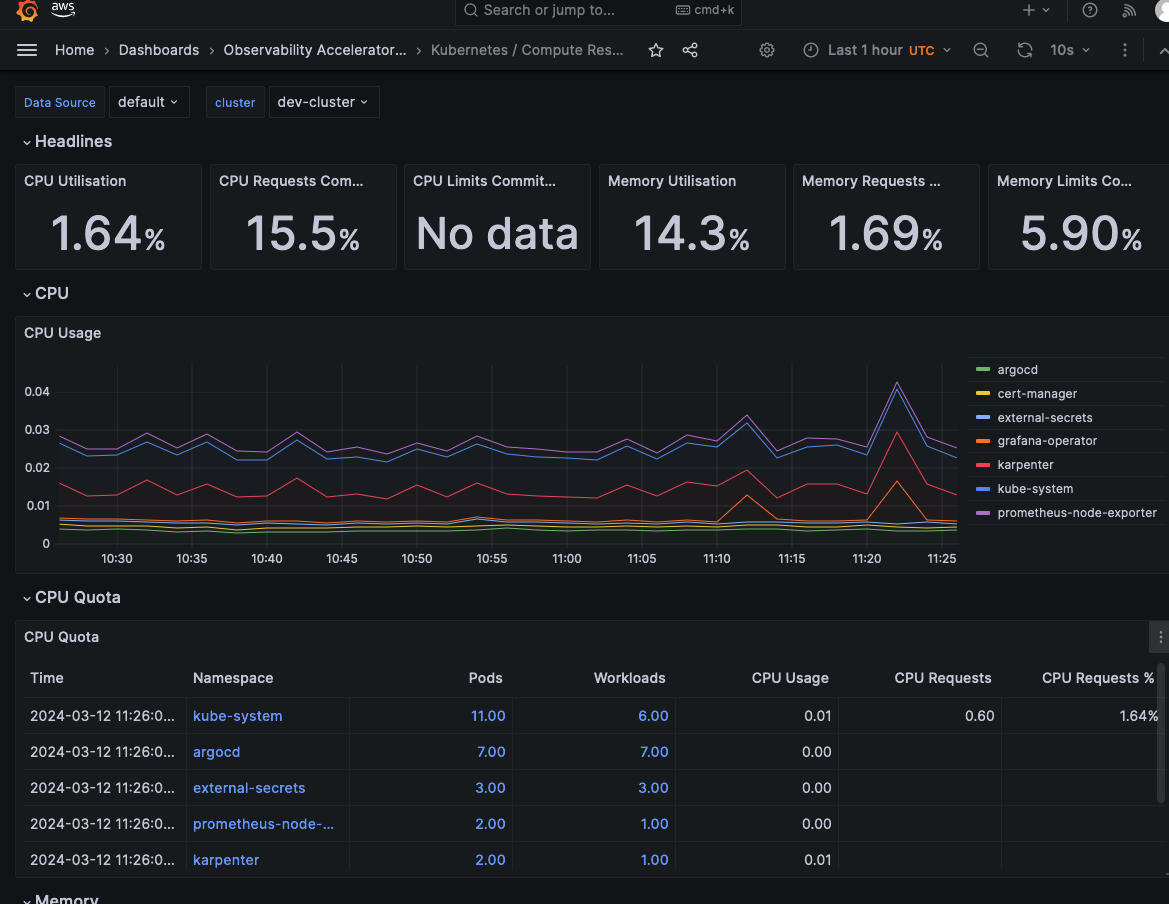
After logging into the AMG workspace, you should expect to see the following dashboards already configured and ready to use:
CloudWatch logs
Although CW logs are not configured in this folder, the log-group convention to access the CW logs ingested by the AWS for fluentbit addon is /aws/eks/<CLUSTER_NAME>/aws-fluentbit-logs
Architecture Decisions
Using AWS Managed Services for OSS Observability tooling
Context
This pattern runs a single Amazon EKS cluster per environment in a single account. One of the reasons for that is to simplify the operational processes for managing the cluster and its infrastructure (including connected services, addons, etc…).
Decision
To reduce the need to manage observability tooling and infrastructure, this pattern uses the Amazon Managed Service for Prometheus (AMP), and the Amazon Managed Grafana (AMG) as the observability metric database and visualization service. Amazon CloudWatch is used as the logging visualization tool alongside a deployed addon of aws-fluent-bit. It also uses an in-cluster Prometheus kube-stack, or manages an ADOT Collector, this pattern uses the recently launched AWS Managed Collector for AMP.
Consequences
Consequences of this decision, true to the date of writing this README, is that there is a 1:1 mapping between an EKS cluster and an AMP workspace, meaning that each cluster will have its own AMP workspace. This shouldn’t be a concern as the design consideration of this pattern is to create isolated per-environment deployments of the cluster, its supporting services, and addons.
A challenging consequence of this decision is that currently the AWS Managed Collector is using the previous way of authenticating to an EKS cluster, using the aws-auth ConfigMap entry, and not the new EKS Cluster Access Management feature of managing access to the EKS Cluster using Amazon EKS APIs. Because of that, the AWS Managed Collector role needs to be added with eksctl which is the best available tool to this date to manage aws-auth configMap entries.
Keep an eye on the output of this Terraform folder which includes the eksctl command to create the entry for the AWS Managed Scraper IAM Role
Grafana-Operator to configure AMG workspace
Context
To provide a complete solution in this pattern, the observability resources need to be configured as part of the deployment of this pattern. This includes connecting the AMP workspace as a data-source for the AMG workspace, deploying a set of predefined dashboards as a starting point, and a process to deploy new dashboards in the same way the “basic”/predefined dashboards were deployed.
Decision
Since the AMG API doesn’t support managing the workspace APIs itself (meaning the grafana APIs), and only the AMG service specific configurations, this pattern uses the grafana-operator to connect to the AMG workspace, and deploy dashboards into it.
Consequences
- The Grafana operator requires the cluster to have an API key stored as a Kubernetes secret in the cluster so that the grafana-operator can connect to the workspace. That means that the API key is generated and stored in the cluster itself.
- The dashboards are managed as assets/files stored in a GitRepo and synced to the AMG workspace continuously.
- TBD - use of an API key requires a process for rotating a key and redeploying it to system manager as a secret object, and sync it to the cluster afterwards (using ESO - External Secrets Operator).
Deploy it
To deploy resources contained in this folder to a specific environment, use the following commands:
export AWS_REGION=us-east-1
export AWS_PROFILE=default
make ENVIRONMENT=dev MODULE=40.observability/45.aws-oss-observability apply
Troubleshooting
How can I check that metrics are ingested to the AMP workspace?
Using awscurl allows you to interact with the AMP workspace. Use the following command samples to query collecting jobs running, labels collected, and metrics values:
REGION=<YOUR_REGION>
WSID=<YOUR_AMP_WORKSPACE_ID>
# List jobs collecting metrics
awscurl --service="aps" --region=$REGION "https://aps-workspaces.$REGION.amazonaws.com/workspaces/$WSID/api/v1/label/job/values" | jq
# List labels collected
awscurl --service="aps" --region=$REGION "https://aps-workspaces.$REGION.amazonaws.com/workspaces/$WSID/api/v1/label/__name__/values" | jq
# List values for a specific label
awscurl --service="aps" --region=$REGION "https://aps-workspaces.$REGION.amazonaws.com/workspaces/$WSID/api/v1/query?query=apiserver_request_duration_seconds_bucket" | jq
Variables:
ENVIRONMENT: Specifies the environment (e.g., dev, prod) for which the Terraform configuration will be applied. It defaults todevif not set.MODULE: Specifies a specificMODULEto run.
Uninstall the Guidance
To uninstall the guidance and remove all associated resources, follow the cleanup steps provided below:
Destroy Specific Modules: If you only want to destroy specific modules, use the following command. Replace
10.networkingwith the module you wish to destroy:export AWS_REGION=us-east-1 export AWS_PROFILE=default make ENVIRONMENT=dev MODULE=10.networking destroy AUTO_APPROVE=trueDestroy All Resources: To remove all resources created by this guidance, use the following command. This will run
terraform destroyon all modules in reverse order:export AWS_REGION=us-east-1 export AWS_PROFILE=default make ENVIRONMENT=dev destroy-all AUTO_APPROVE=trueRemove Resources Provisioned Outside This Guidance
Please note that any resources provisioned outside of this guidance will need to be removed manually by the user. These may include, but are not limited to:
- Application Load Balancers (ALBs) created for testing or production use
- Elastic IP addresses associated with instances or network interfaces
- S3 buckets created for data storage or logging
- IAM roles or policies created for specific use cases
- EC2 instances launched manually for testing or additional workloads
- RDS databases created for application data storage
- CloudWatch Logs log groups and metrics
- Route 53 hosted zones and records
To remove these resources:
- Use the AWS Management Console to identify and delete the resources
- Use AWS CLI commands to remove resources programmatically
- Check each AWS service used in your project for any lingering resources
Architecture Decisions
Global variable file per environment
Context:
This pattern can deploy the same configuration to multiple environments. There’s a need to customize environment-specific configurations to support gradual updates or per-environment specific configuration.
Decision:
This pattern standardizes on a shared Terraform variable file per environment, which is used in the CLI (see Makefile as it wraps the CLI commands) to use this file throughout multiple folder configurations.
Consequences:
This decision helps share the variables across different folders and standardizes variable naming and values.
Storing Environment-Specific State Using Terraform Workspaces
Context:
To keep the IaC code DRY, the state of the different resources needs to be kept in the context of an environment so that other configurations in different folders can access the outputs of the right environment.
Decision:
This pattern uses Terraform Workspaces to store and retrieve environment-specific state from the S3 Backend being used as the remote state backend. Per Hashicorp recommendations on “Multi-Environment Deployment”, it’s encouraged to use Terraform workspaces to manage multiple environments: “Where possible, it’s recommended to use a single backend configuration for all environments and use the terraform workspace command to switch between workspaces.”
Consequences:
The use of Terraform workspaces allows us to use the same IaC code and backend configuration without changing it per environment. As this project’s Makefile wraps the relevant workspace commands, if users choose to rewrite their own CLI automation, they’ll need to handle workspace switching before applying per-environment configuration.
Related resources
Contributors
- Tsahi Duek, Principal GTM Specialist Solutions Architect, Containers
- Erez Zarum, Solutions Architect, Containers
- Alexander Pinsker, Sr Solutions Architect, Containers
- Daniel Zilberman, Sr Solutions Architect, Tech Solutions Team
- Tal Hibner, Technical Account Manager
Notices
Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents AWS current product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied…