Guidance for Media2Cloud on AWS
Summary: This implementation guide provides details on how to extract key details from your media files in your AWS accounts. It provides an overview of the Guidance for Media2Cloud on AWS, its reference architecture and components, considerations for planning the deployment, and configuration steps for deploying the Guidance to the AWS Cloud.
Last update: September 2023
(see Revisions)
Guidance overview
Migrating your digital asset management to the cloud allows you to take advantage of the latest innovations in asset management and supply chain applications. However, transferring your existing video archives to the cloud can be a challenging and slow process.
The Guidance for Media2Cloud on AWS helps streamline and automate the content ingestion process. It sets up serverless end-to-end ingestion and analysis workflows to move your video assets and associated metadata to the Amazon Web Services (AWS) Cloud. During the migration, this Guidance analyzes and extracts machine learning metadata from your video and images using Amazon Rekognition, Amazon Transcribe, and Amazon Comprehend. It extracts tabular information from scanned documents using Amazon Textract. This Guidance also includes a web interface to help you to immediately start ingesting and analyzing your content.
Guidance for Media2Cloud on AWS is designed to provide a serverless framework for accelerating the setup and configuration of a content ingestion and analysis process. We recommend that you use this Guidance as a baseline and customize it to meet your specific needs.
The guide is intended for IT infrastructure architects and developers who have practical experience working with video workflows and architecting in the AWS Cloud.
Features and benefits
The Guidance provides the following features:
Simple user interface
Create a web interface that makes it easy to upload, browse, and search your video and image files and extracted metadata.
Integration with AWS Service Catalog AppRegistry and AWS Systems Manager Application Manager
This Guidance includes a Service Catalog AppRegistry resource to register the Guidance’s CloudFormation template and its underlying resources as an application in both AWS Service Catalog AppRegistry and AWS Systems Manager Application Manager. With this integration, you can centrally manage the Guidance’s resources and enable application search, reporting, and management actions.
Concepts and definitions
This section describes key concepts and defines terminology specific to this Guidance:
application
A logical group of AWS resources that you want to operate as a unit.
workflow
Generated state machines that run a number of operations in sequence.
proxies
Files created at a lower reGuidance using compression technology for video, audio, images, and documents.
LTO
Linear Tape-Open is a magnetic tape data storage technology used for backup and archiving purposes.
MAM
Media Asset Management is a software tool that centrally manages, organizes, and catalogs media assets. MAM provides the option to associate media assets to one or several files with customized metadata to ease the content searching, retrieving, and distribution tasks.
For a general reference of AWS terms, see the AWS glossary in the AWS General Reference.
Architecture overview
This section provides a reference implementation architecture diagram for the components deployed with this Guidance.
Architecture diagram
Deploying this Guidance with the default parameters deploys the following components in your AWS account.
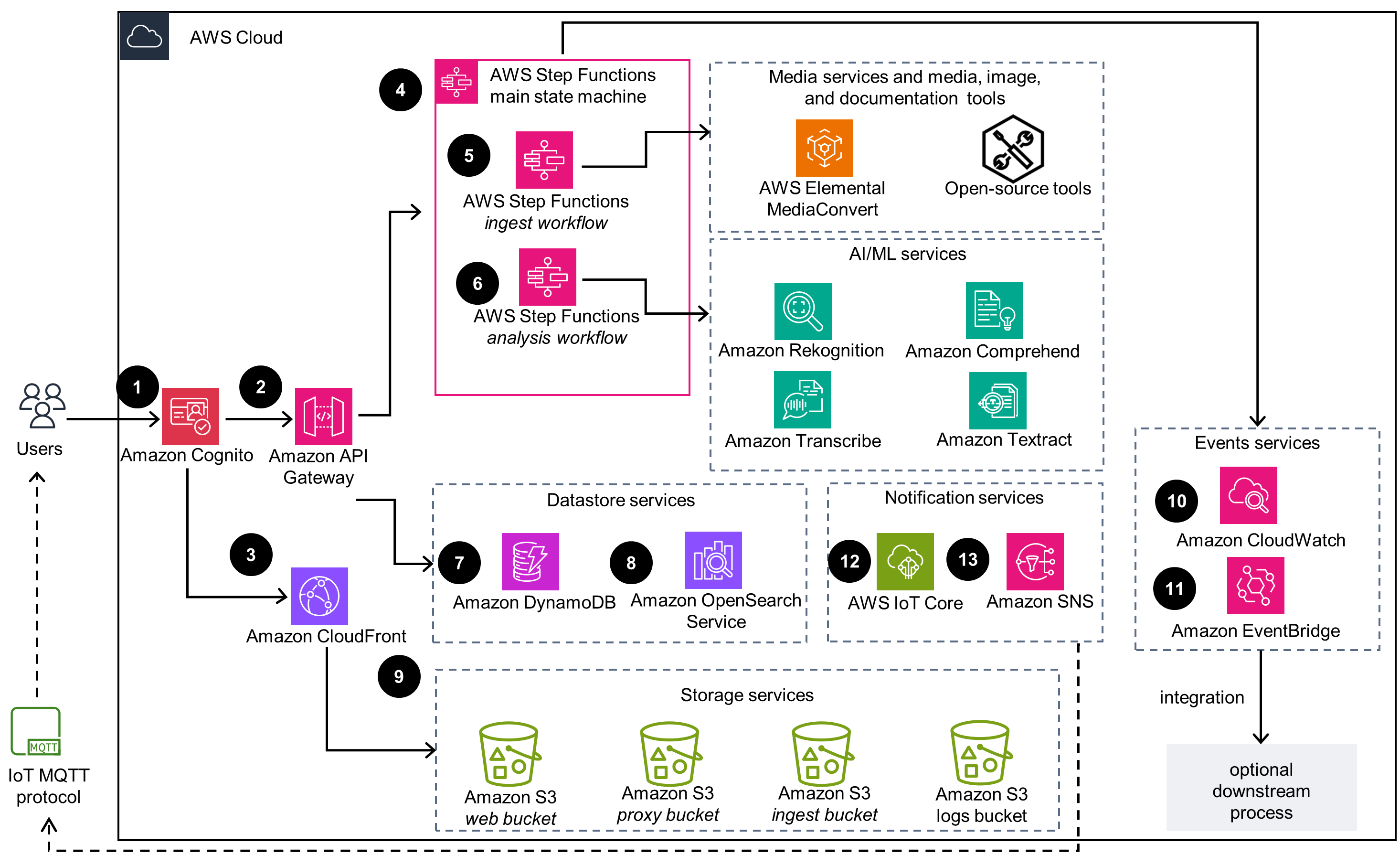
Guidance for Media2Cloud on AWS architecture on AWS
The AWS CloudFormation template deploys the following infrastructure:
An Amazon Cognito user pool to provide a user directory.
An Amazon API Gateway RESTful API endpoint, which is configured to use AWS Identity and Access Management(IAM) authentication.
An Amazon CloudFront distribution that hosts the web application artifacts such as minimized JavaScript files and graphics stored in the web bucket.
An AWS Step Functions main state machine which serves as the entry point to the backend ingestion and analysis workflows.
A Step Functions ingestion sub-state machine that orchestrates the ingestion process by media file type and generates proxies for ingested media. It uses AWS Elemental MediaConvert for video and audio files and open-source tools for image files and documents.
A Step Functions analysis sub-state machine that is responsible for the analysis process. It consists of Step Functions that run analysis jobs with Amazon Rekognition, Amazon Transcribe, Amazon Comprehend, and Amazon Textract.
Amazon DynamoDB tables store artifacts generated during the ingestion and analysis processes, such as overall status, pointers to where intermediate files are stored, and state machine run tokens.
An Amazon OpenSearch Service cluster, which stores ingestion attributes and machine learning metadata, and facilitates customers’ search and discovery needs.
Four Amazon Simple Storage Service (Amazon S3) buckets store uploaded content, file proxies that the Guidance generates during ingestion, static web application artifacts, and access logs for services used.
Amazon CloudWatch event rules are logged when specific tasks undergo state changes.
Amazon EventBridge used by an internal queue management system where the backlog system notifies workflows (state machines) when a queued AI/ML request has been processed.
An AWS IoT Core topic that allows the ingestion and analysis workflows to communicate with the front-end web application asynchronously through publish or subscribe MQTT messaging.
Amazon Simple Notification Service (Amazon SNS) topics to allow Amazon Rekognition to publish job status in the video analysis workflow, and to support custom integration with customers’ system, by allowing the Guidance to publish ingest_completed and analysis_completed events.
Architecture details
The AWS CloudFormation template deploys three logical components: a front-end web application, orchestration workflows (ingestion and analysis), and data storage. The web application provides an interface for customers to upload media content, and view and manage their archive collection. The ingestion and analysis workflows are initiated when a customer uploads content to the application. The ingestion workflow orchestrates tasks to ingest source videos, images, audio, and documents in a serverless manner. The analysis workflow analyzes and extracts machine learning metadata from content. When you upload a media asset to the Amazon S3 ingestion bucket, the ingestion workflow creates a standardized proxy file and thumbnails for analysis. The analysis workflow analyzes the content and extracts metadata using AWS AI services.
The S3 ingestion bucket has an Amazon S3 lifecycle policy that allows the Guidance to move uploaded videos and images to Amazon Simple Storage Service Glacier (Amazon S3 Glacier) for archiving. Additionally, the AWS CloudFormation template deploys multiple Amazon DynamoDB tables to store metadata about each processed content, such as pointers to where its proxy files are stored in Amazon S3 and the types of AI/ML analysis performed on it. The Guidance also deploys an OpenSearch Service cluster that allows customers to search and discover technical media metadata or AI/ML generated metadata.
Web interface
This Guidance deploys a web interface that allows you to upload, browse, search video and image files, extract metadata, and search and discover content metadata. The web interface leverages Amazon Cognito for user authentication and is powered by web assets hosted in the web Amazon S3 bucket. Amazon CloudFront provides public access to the Guidance’s website bucket contents. An Amazon API Gateway RESTful API is used for searching results stored in the OpenSearch Service cluster, and AWS IoT Core is used as a publish/subscribe message broker to periodically update workflow progress to connected web clients.
The web interface also provides a human-in-the-loop feature that allows customers to remediate cases where Amazon Rekognition cannot detect individuals in a video or cannot provide logical groupings of related individuals based on the customer’s specific use case, for example, Olympic athletes for a specific year. Using the web interface, customers can create face collections and index people in the video to that face collection.
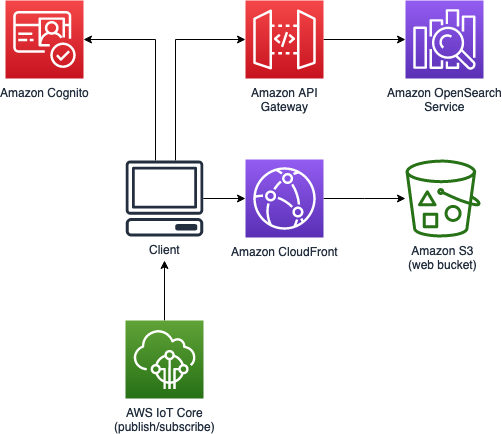
Guidance for Media2Cloud on AWS web interface
Ingestion workflow
The ingestion workflow includes AWS Step Functions and AWS Lambda, which orchestrate the specific ingestion workflow for a video, image, audio file, or document. When a customer uploads a new media file to the Amazon S3 ingestion bucket through the Media2Cloud on AWS web interface, the ingestion process starts. The workflow generates an asset unique identifier, computes and validates an MD5 checksum, and extracts media information such as bitrate, formats, audio channels container format for video, or EXIF information such as GPS location, model, and make for image.
For video and audio files, the ingestion workflow initiates AWS Elemental MediaConvert to create standardized proxy files and thumbnails of the media for analysis. For image files, the ingestion workflow uses an open-source tool, EXIFTool to extract technical metadata and to create proxy images. Similarly for documents, the ingestion workflow generates image proxies for each page in a document.
If the media content is in Amazon S3 Glacier or S3 Glacier Deep Archive storage, the workflow temporarily restores the media content from archive storage to Amazon S3 storage. Proxy files are created and stored in a Amazon S3 proxy bucket, while the technical metadata extracted from media content are indexed in an OpenSearch cluster. When video ingestion process completes, Amazon SNS sends notifications to subscribed users who might use the notification to start other workflows. When an Amazon SNS ingestion notification is received, the automated system can import the files into its system. For more information, refer to Amazon SNS notifications.
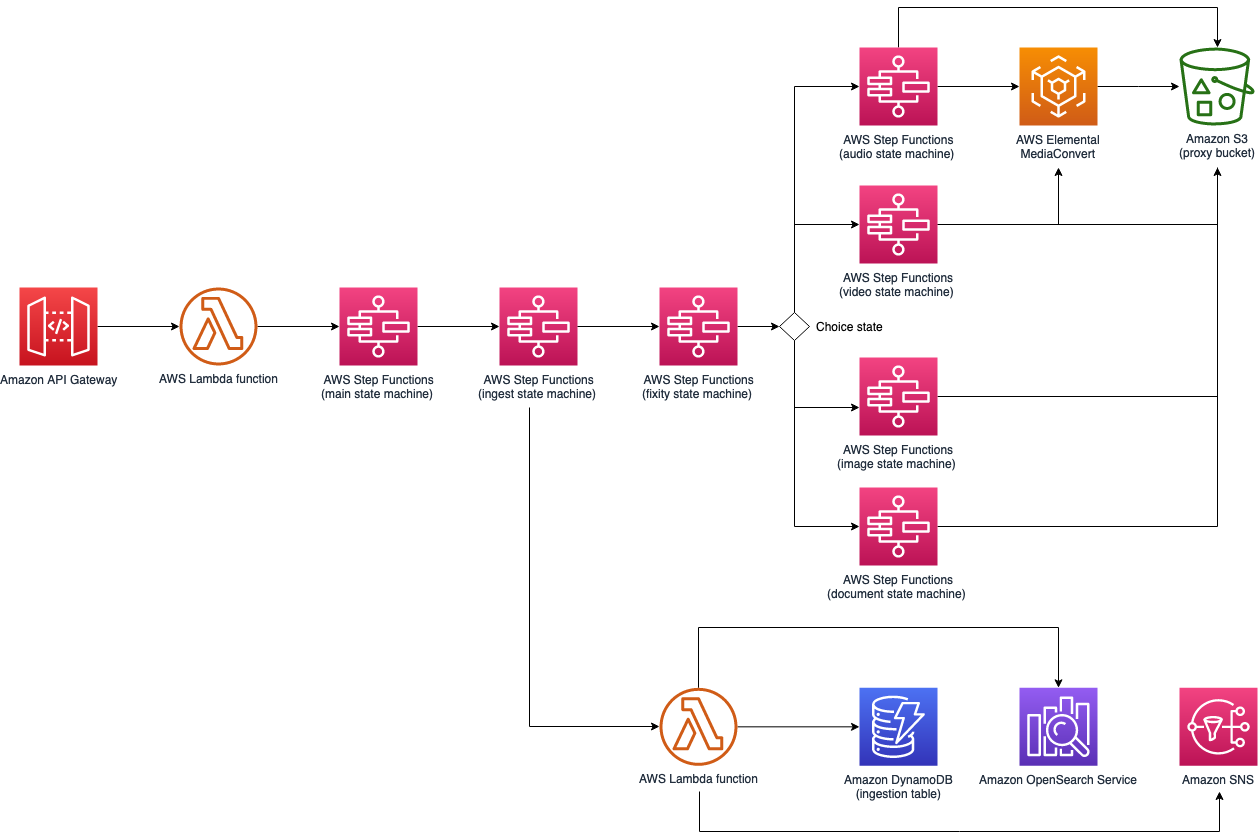
Guidance for Media2Cloud on AWS ingestion workflow
Analysis workflow
The analysis workflow includes AWS Step Functions and AWS Lambda which leverage Amazon Rekognition, Amazon Transcribe, Amazon Comprehend, and Amazon Textract to analyze and extract machine learning metadata from the proxy files generated in the ingestion workflow. The Media2Cloud on AWS Guidance provides the following preset options for the analysis process when you deploy the template: Default, All, and Audio and Text.
Default - Activates celebrity recognition, labels, transcription, key phrases, entities, and text processes.
All - Activates all detections including celebrity recognition, labels, transcription, key phrases, entities, text, faces, face matches, person, moderation, sentiment, and topic processes.
Audio and Text - Activates transcription, key phrases, entities, and text processes.
The web interface also allows the end user to refine the AI/ML settings during the upload process.
The analysis workflow includes four sub-state machines to process the analysis.
The video analysis state machine analyzes and extracts AI/ML metadata from the video proxy using Amazon Rekognition video APIs.
The audio analysis state machine analyzes and extracts AI/ML metadata from the audio stream of the proxy file using Amazon Transcribe and Amazon Comprehend.
The image analysis state machine analyzes and extracts image metadata with Amazon Rekognition image APIs.
The document analysis state machine extracts text, images, and data using Amazon Textract.
To start the analysis workflow, a Lambda function first checks an incoming analysis request and prepares the optimal AI/ML analysis option to run, based on the type of media in the request, and the availability of specific detections. For video and audio, it transforms the metadata results into WebVTT subtitle tracks, chapter markers, key phrases, labels, sentiments, entities, and locations. The analysis workflow can also provide customized analysis output if the customer uses Amazon Rekognition custom label models, Amazon Transcribe custom vocabularies or Amazon Comprehend custom entity recognition. The machine learning metadata results are stored in an Amazon S3 proxy bucket and indexed in an OpenSearch Service cluster. When the analysis is completed, Amazon SNS sends notifications to subscribed users.
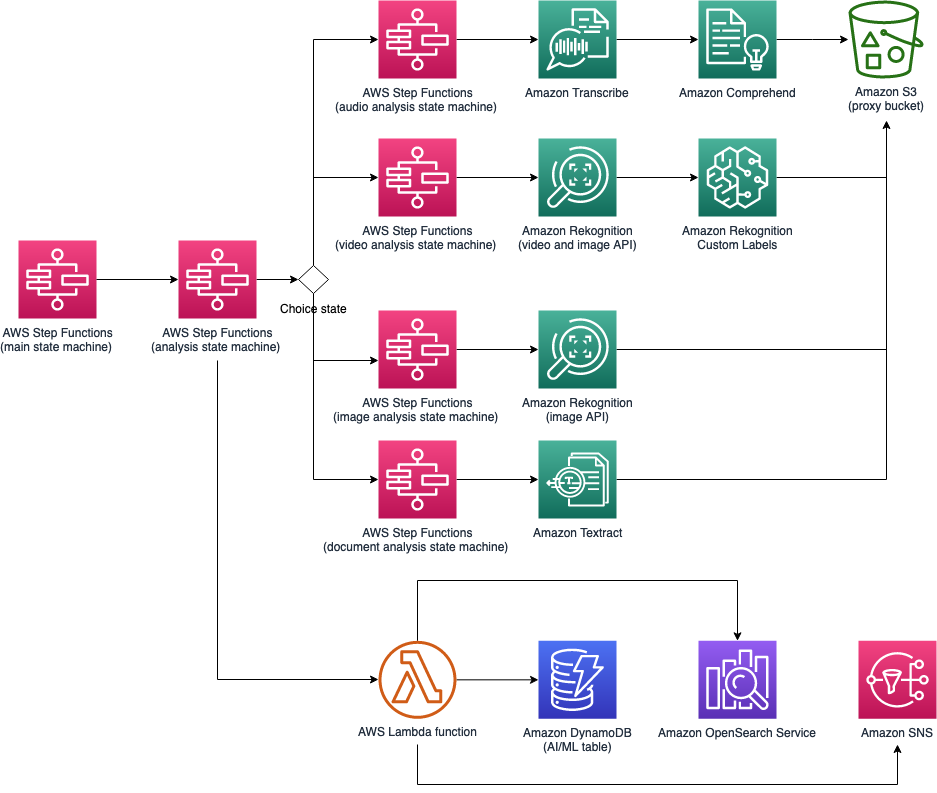
Guidance for Media2Cloud on AWS analysis workflow
Integration with AWS Service Catalog AppRegistry and AWS Systems Manager Application Manager
This Guidance includes a Service Catalog AppRegistry resource to register the Guidance’s CloudFormation template and its underlying resources as an application in both Service Catalog AppRegistry and Systems Manager Application Manager. With this integration, you can centrally manage the Guidance’s resources.
AWS services in this Guidance
- Amazon API Gateway Core. Provides the RESTful API endpoint, which is configured to use IAM authentication.
- Amazon CloudFront Core. Hosts the web application artifacts such as minimized JavaScript files and graphics stored in the web bucket.
- Amazon Cognito Core. Provides user directory and access management.
- Amazon DynamoDB Core. Provides the storage for artifacts generated during the ingestion and analysis processes, such as overall status, pointers to where intermediate files are stored, and state machine run tokens.
- AWS Lambda Core. Supports orchestration of ingestion and analysis workflows.
- Amazon OpenSearch Service Core. Stores ingestion attributes and machine learning metadata, and facilitates customers’ search and discovery needs.
- Amazon S3 Core. Provides storage for the uploaded content, file proxies that the Guidance generates during ingestion, static web application artifacts, and access logs for services used.
- AWS Step Functions Core. Provides main state machine which serves as the entry point to the Guidance’s backend ingestion and analysis workflows.
- AWS Elemental MediaConvert Supporting. Can be integrated into workflows to transcode input video into mpeg4 format and generate proxies for ingested media.
- Amazon EventBridge Supporting. Used by an internal queue management system where the backlog system notifies workflows (state machines) when a queued AI/ML request has been processed.
- AWS IoT Core Supporting. Allows the ingestion and analysis workflows to communicate with the front-end web application asynchronously through publish/subscribe MQTT messaging.
- Amazon SNS Supporting. Allows Amazon Rekognition to publish job status in the video analysis workflow. In addition, Amazon SNS allows Amazon Rekognition to support custom integrations with customers’ systems by allowing the Guidance to publish ingest_completed and analysis_completed events.
- AWS Systems Manager Supporting. Provides application-level resource monitoring and visualization of resource operations and cost data.
- Amazon Comprehend Optional. Can be integrated into workflows to find key phrases in text and references to real-world objects, dates, and quantities in text.
- Amazon Rekognition Optional. Can be integrated into workflows for celebrity recognition, content moderation, face detection, face search, label detection, person tracking, shot, text, and technical cue detection.
- Amazon Textract Optional. Can be integrated into workflows to extract tabular metdata from documents using Optical Character Recognition (OCR).
- Amazon Transcribe Optional. Can be integrated into workflows to create SRT or VTT captions files from video transcripts. It can also convert input audio to text.
Plan Your Deployment
This section describes the cost, security, Regions, and other considerations prior to deploying the Guidance.
Cost
You are responsible for the cost of the AWS services used while running this Guidance. The total cost for running this Guidance depends on the amount of data being ingested and analyzed, running the Guidance’s OpenSearch Service cluster, and the size and length of media files analyzed with Amazon Rekognition, Amazon Transcribe, and Amazon Comprehend.
As of this revision, the cost for running this Guidance on 100 hours of videos totaling one terabyte with the default settings in the US East (N. Virginia) Region is $2,149.95 (one time processing) with $104.60/month (recurring) for Amazon S3 data storage and OpenSearch Service search engine.
We recommend creating a budget through AWS Cost Explorer to help manage costs. Prices are subject to change. For full details, see the pricing webpage for each AWS service used in this Guidance. For customers who want to process large-scale video archives, we recommend that you contact your AWS account representative for at-scale pricing.
Example monthly cost
The following example is for a total file size of one terabyte, which equates to one hundred total hours of video content where each video is one hour in duration. The cost is broken down to the following categories:
Migration cost – When the video files are uploaded and stored in Amazon S3 Glacier Deep Archive storage. The cost is estimated based on the total size of the video files.
Ingestion cost – When the uploaded video files are transcoded with AWS Elemental MediaConvert to create low reGuidance proxy video files []{.underline}plus the ingestion workflow cost composed of AWS Step Functions state transitions and AWS Lambda compute runtime, and Amazon DynamoDB Read/Write request units.
Analysis cost – When proxy files are analyzed with Amazon Rekognition, Amazon Transcribe, and Amazon Comprehend plus the analysis workflow cost composed of AWS Step Functions state transitions and AWS Lambda Compute runtime, and Amazon DynamoDB Read/Write request units.
Search engine cost – When the generated metadata are indexed to an OpenSearch Service cluster. The cost depends on the number of dedicated nodes, the number of instance nodes, and the amount of Amazon EBS volume.
| AWS service | Dimensions | Cost (USD) | |
|---|---|---|---|
| Migration cost (one terabyte) | |||
| S3 Glacier Deep Archive | $0.00099 per GB/Month * 1024 GB | $1.01 | |
| Ingestion cost (100hours) | |||
| AWS Elemental MediaConvert (SD, AVC with Professional Tier) | $0.012 per minutes * 100 hours | $72.00 | |
| AWS Elemental MediaConvert (Audio only) | $0.003 per minutes * 100 hours | $18.00 | |
| AWS Step Fuctions State transitions, AWS Lambda Compute unite (MB per 1ms), and Amazon DynamoDB- Read Write Request Units | Varies depending on number of state transitions, the Lambda function memory size and runtime duration, and read write request to DynamoDB tables. | ~$1.05 | |
| Analysis cost (100 hours) | |||
| Amazon Rekognition Celebrity Recognition | $0.10 per minute * 100 hours | $600.00 | |
| Amazon Rekognition Label Detection | $0.10 per miniute * 100 hours | $600.00 | |
| Amazon Rekognition Segment Detection (Shot and Technical Cues detections) | ($0.05 + $0.05 per minute) * 100 hours | $600.00 | |
| Amazon Transcribe | $0.024 per minute * 100 hours | $144.00 | |
| Amazon Comprehend Key Phrase Extraction | $0.0001 per unit Varies; depends on number of characters extraced from audio dialogue of the video files | $5.00 | |
| Amazon Comprehend Entity Recognition | $0.0001 per unit Varies; depends on number of characters extracted from audtio dialogue of the video files | $5.00 | |
| AWS Step Functions State transitions, AWS Lambda Compute unit (MB per 1ms), and Amazon DynamoDB Read Write Request Units | Varies depending on number of state transitions, the Lambda function memory size and runtime duration, and read write request to DynamoDB tables. | ~$ 0.30 | |
| Search engine cost | |||
| Amazon OpenSearch Service dedicated node (t3.small.search) | $0.036 per hour * 0 node | $0.00 | |
| Amazon OpenSearch Service instance node (m5.large.search) | $0.142 per hour * 1 node | $102.24 | |
| Amazon OpenSearch Service EBS Volume (GP2) | $0.135 per GB / month * 10 GB | $1.35 | |
| Total cost (based on one terabyte with 100 hours of videos) | |||
| Monthly recurring cost (S3 storage and Amazon OpenSearch Service cluster) | $1.01 + $102.24 + 1.35 | $104.60 | |
| One-time processing cost (AWS Elemental MediaConvert, Amazon Rekognition, Transcribe, Comprehend, AWS Step Functions, AWS Lambda) | ($72 + $18) + $1.05 + ($600 + $600 + $600) + $144 + ($5 + $5) + $0.30 | $2,045.35 | |
| Total: | $2,149.95 |
Security
When you build systems on AWS infrastructure, security responsibilities are shared between you and AWS. This shared responsibility model reduces your operational burden because AWS operates, manages, and controls the components including the host operating system, the virtualization layer, and the physical security of the facilities in which the services operate. For more information about AWS security, visit AWS Cloud Security.
Server-side encryption
AWS highly recommends that customers encrypt sensitive data in transit and at rest. This Guidance automatically encrypts media files and metadata at rest with Amazon Simple Storage Service (Amazon S3) Server-Side Encryption (SSE). The Guidance’s Amazon Simple Notification Service (Amazon SNS) topics and Amazon DynamoDB tables are also encrypted at rest using SSE.
Amazon CloudFront
This Guidance deploys a static website hosted in an Amazon S3 bucket. To help reduce latency and improve security, this Guidance includes an Amazon CloudFront distribution with an origin access identity, which is a special CloudFront user that helps restrict access to the Guidance’s website bucket contents. For more information, refer to Restricting Access to Amazon S3 Content by Using an Origin Access Identity.
Amazon OpenSearch Service
Documents indexed to the Amazon OpenSearch Service cluster are encrypted at rest. Node-to-node communication within the cluster is also encrypted.
Search engine sizing
The CloudFormation template provides presets for the end user to configure different Amazon OpenSearch Service clusters: Development and Testing, Suitable for Production Workload, Recommended for Production Workload, and Recommended for Large Production Workload.
Development and Testing – This preset creates an Amazon OpenSearch Service cluster in a single Availability Zone with a single m5.large.search data node, 10GB storage, and without dedicated primary node.
Suitable for Production Workflow – This preset creates an Amazon OpenSearch Service cluster in two Availability Zones with two m5.large.search data nodes, 20GB storage, and three dedicated t3.small.search primary nodes.
Recommended for Production Workload – This preset creates an Amazon OpenSearch Service cluster in two Availability Zones with four m5.large.search data nodes, 20GB storage, and three dedicated t3.small.search primary nodes.
Recommended for Large Production Workload – This preset creates an Amazon OpenSearch Service cluster in three Availability Zones with six m5.large.search data nodes, 40GB storage, and three dedicated t3.small.search primary nodes.
Supported AWS Regions
This Guidance can be deployed to any AWS Region. If a service, such as Amazon Rekognition, is not currently available in the Region, the Guidance reduces its functionality. Analysis features such as celebrity recognition, label detection, and face detection will be turned off.
We recommend for you to launch the Guidance in an AWS Region where Amazon Rekognition, Amazon Transcribe, Amazon Textract, and Amazon Comprehend are available. For the most current availability of AWS services by Region, refer to the AWS Regional Services List.
As of the latest revision, this Guidance is fully supported in the following Regions:
| Region name | |
|---|---|
| US East (Ohio) | Asia Pacific (Sydney) |
| US East (N. Virginia) | Canada (Central) |
| US West (Oregon) | Europe (Frankfurt) |
| Asia Pacific (Mumbai) | Europe (Ireland) |
| Asia Pacific (Seoul) | Europe (London) |
| Asia Pacific (Singapore) | AWS GovCloud (US-West) |
Quotas
Service quotas, also referred to as limits, are the maximum number of service resources or operations for your AWS account.
Quotas for AWS services in this Guidance
Make sure you have sufficient quota for each of the services implemented in this Guidance. For more information, see AWS service quotas.
Use the following links to go to the page for that service. To view the service quotas for all AWS services in the documentation without switching pages, view the information in the Service endpoints and quotas page in the PDF instead.
AWS CloudFormation quota
Your AWS account has AWS CloudFormation quotas that you should be aware of when launching the stack in this Guidance. By understanding these quotas, you can avoid limitation errors that would prevent you from deploying this Guidance successfully. For more information, see AWS CloudFormation quotas in the in the AWS CloudFormation User’s Guide.
Amazon Transcribe
Amazon Transcribe can process files up to four hours in length, this is the Maximum media duration. For more information, refer to Amazon Transcribe endpoints and quotas.
Amazon Recognition
The Amazon Rekognition Custom Labels setting is currently limited to running up to two models. For more information, refer to Guidelines and quotas in Amazon Rekognition Custom Labels in the Amazon Rekognition Custom Labels Guide.
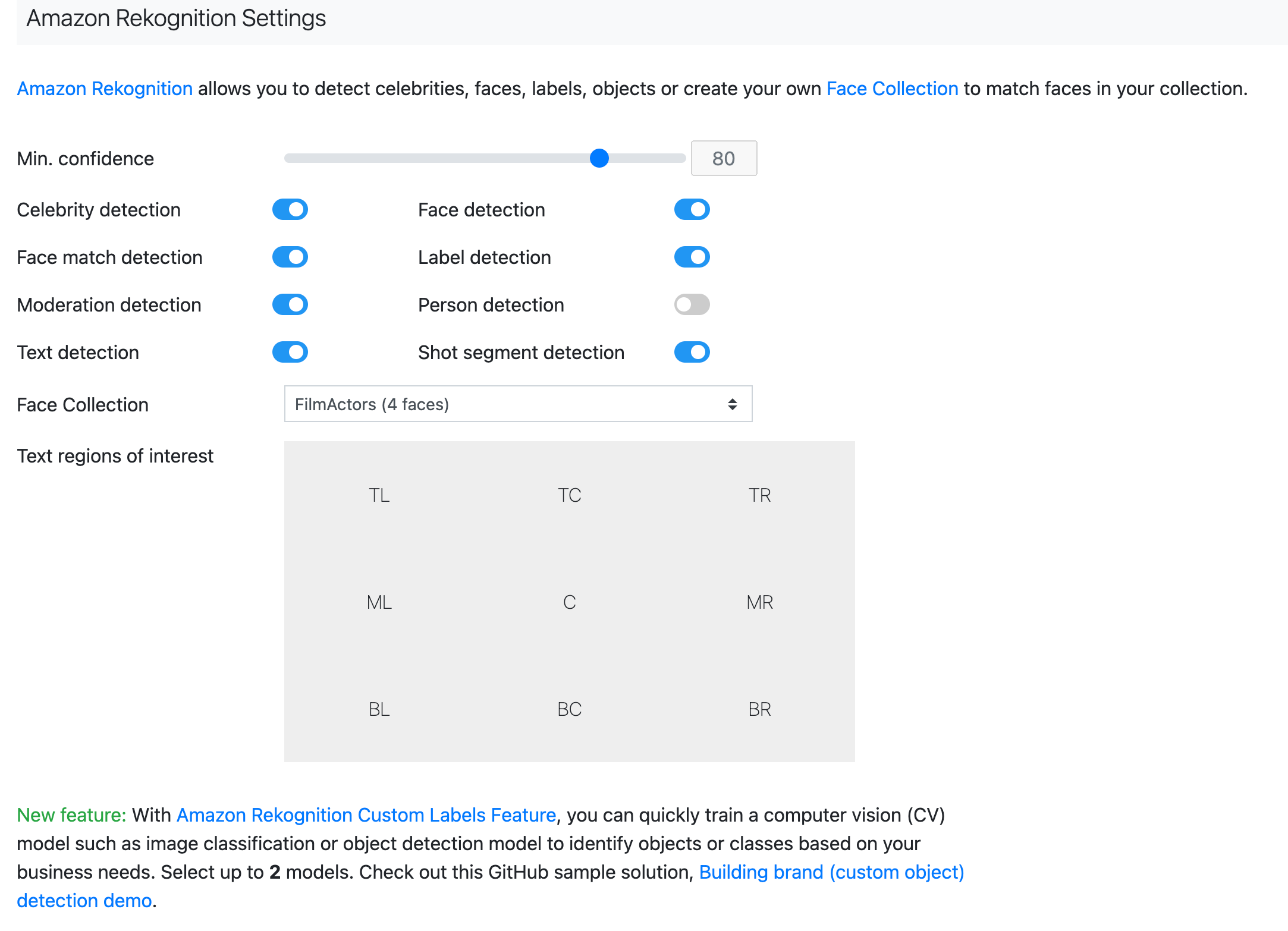
Amazon Rekognition default detection settings
Deploy the Guidance
This Guidance uses AWS CloudFormation templates and stacks to automate its deployment. The CloudFormation template specifies the AWS resources included in this Guidance and their properties. The CloudFormation stack provisions the resources that are described in the template.
Deployment process overview
Follow the step-by-step instructions in this section to configure and deploy the Guidance into your account.
Before you launch the Guidance, review the cost, architecture, network security, and other considerations discussed earlier in this guide.
Time to deploy: Approximately 25 minutes
Launch the AWS CloudFormation template into your AWS account.
Enter values for required parameters.
Review the other template parameters, and adjust if necessary.
Step 2: Upload a video or image file
- Upload a file using the web interface to begin the ingestion and analysis workflows.
Step 3: Create your face collection
- Index faces to create your face collection to improve face analysis results.
- Find the specific moment you are looking for.
Step 5: Customizing AI/ML settings
- Configure the AI/ML services that you want to use in your analysis.
- A summary of all content in your collection.
Important: This Guidance includes an option to send anonymized operational metrics to AWS. We use this data to better understand how customers use this Guidance and related services and products. AWS owns the data gathered though this survey. Data collection is subject to the AWS Privacy Notice.
To opt out of this feature, download the template, modify the AWS CloudFormation mapping section, and then use the AWS CloudFormation console to upload your updated template and deploy the Guidance. For more information, see the Anonymized data collection section of this guide.
AWS CloudFormation template
You can download the CloudFormation template for this Guidance before deploying it.
media2cloud.template - Use this template to launch the Guidance and all associated components. The default configuration deploys the core and supporting services, but you can customize the template to meet your specific needs.
Note: If you have previously deployed this Guidance, see Update the Guidance for update instructions.
Step 1: Launch the stack
Follow the step-by-step instructions in this section to configure and deploy the Guidance into your account.
Time to deploy: Approximately 25 minutes
Sign in to the AWS Management Console and select the button to launch the media2cloud AWS CloudFormation template.
The template launches in the US East (N. Virginia) Region by default. To launch the Guidance in a different AWS Region, use the Region selector in the console navigation bar.
On the Create stack page, verify that the correct template URL is in the Amazon S3 URL text box and choose Next.
On the Specify stack details page, assign a name to your Guidance stack. For information about naming character limitations, see IAM and AWS STS quotas, name requirements, and character limits in the AWS Identity and Access Management User Guide.
Under Parameters, review the parameters for this Guidance template and modify them as necessary. This Guidance uses the following default values.
| Parameter | Default | Description |
|---|---|---|
| <Requires input> | Email address of the user that will be created in the Amazon Cognito identity pool and subscribed to the Amazon SNS topic. Subscribed users will receive ingestion, analysis, labeling, and error notifications. After launch, two emails will be sent to this address: one with instructions for logging in to the web interface and one confirming the Amazon SNS subscription. | |
| Price Class | Use Only U.S., Canada and Europe | A dropdown box with price classes for the edge location from which Amazon CloudFront serves your requests. Choose Use Only U.S., Canada and Europe; Use U.S., Canada, Europe, Asia and Africa; or Use All Edge Locations. For more information, refer to Choosing the price class. |
| Amazon OpenSearch Cluster Size | Development and Testing | A drop-down box with four Amazon OpenSearch Service cluster sizes: Development and Testing, Suitable for Production Workloads, Recommended for Production Workloads, and Recommended for Large Production Workloads. |
| Analysis Feature(s) | Default | A drop-down box with nine presets: Default, All, Video analysis, Audio analysis, Image analysis, Document analysis, Celebrity recognition only, Video segment detection only, and Speech to text only. For more information about the presets, refer to Analysis workflow. |
| (Optional) User Defined Amazon S3 Bucket for ingest | <Optional input> | If you have an existing bucket that you would like to store uploaded contents, specify the bucket name. Otherwise, leave it blank to auto create a new bucket. |
| (Optional) Allow autostart on ingest S3 bucket | NO | A drop-down box to specify if you would like to automatically start workflow when directly upload assets to Amazon S3 ingestion bucket. |
Select Next.
On the Configure stack options page, choose Next.
On the Review page, review and confirm the settings. Select the box acknowledging that the template will create AWS Identity and Access Management (IAM) resources.
Choose Create stack to deploy the stack.
You can view the status of the stack in the AWS CloudFormation console in the Status column. You should receive a CREATE_COMPLETE status in approximately 25 minutes.
Step 2: Upload a video or image file
After the Guidance successfully launches, you can start uploading video or image files for processing. The Guidance sends two emails: one with the subscription confirmation for the Amazon SNS topic to send ingestion, analysis, labeling, and error notifications, and one with instructions for signing into the Guidance’s provided web interface.
In the M2CStatus email, select Confirm subscription to subscribe to the Amazon SNS topic.
In the second email, follow the instructions to sign in to the website.
You will be prompted to change the password the first time you sign in.Choose Sign in on the upper right corner of the page and sign in using your recently created password.
Navigate to the Upload tab.
Drag and drop your files to the Upload Video box, or choose the Browse Files button to upload a video or image file. Once the files are uploaded, choose Quick upload, or select Next to Start Upload.
Once the ingestion process is completed, a thumbnail image of the video or image is created. You can hover over the thumbnail image and select Play now to view the media file.
Step 3: Create your face collection
The web interface allows you to create your own Amazon Rekognition face collection and index and store faces in the collection to improve the analysis results.
In the web interface select FaceCollection in the top navigation.
Type in the name of the face collection in the blank field and choose Create New Collection.
In the web interface, hover over a created video or image and choose Play.
Choose the Play button again and then choose Pause once you find a face in the content.
Move the toggle by Snapshot Mode to the right to display a bounding box.
Adjust the size of the bounding to fit tightly over the face.
Type the name of the person in the Name box and select your Face Collection from the dropdown menu.
Once finished, choose the Index Face button.
Repeat steps 4-8 until you have identified all of the faces.
After the faces are indexed, choose Re-analyze to analyze the video or image using the newly indexed faces in your face collection so that all unidentified faces are recognized and indexed.
Step 4: Advanced search
Included in the web interface is the ability to search for specific moments across the analyzed content. A user has the ability to put in specific search terms and have timestamped results returned.
In the web interface select Collection in the top navigation bar.
On the collection page, there is a search bar in the top right-hand corner of the page. Deselect any of the attributes that you want excluded from your search and then type a term or phrase in the Search box and hit submit.
Assets matching the search term will be presented under the Search Results section of the page and highlight where there was a match to your search term.
Choose the file thumbnail in the search results to be taken to that asset.
Step 5: Customizing AI/ML settings
In this version of Media2Cloud on AWS, users have a lot of flexibility on the AI/ML services that are used. They also have the ability to configure those services for their use cases.
In the web interface select Settings from the top navigation bar.
In the Amazon Rekognition Settings section:
You can set the minimum confidence level that you want results from.
Toggle on or off specific detection types.
Select the face collection that you want to use when analyzing assets.
When using Amazon Rekognition to detect text on screen, you can select the specific regions of the screen for analysis.
If you have created a custom AI/ML model using Amazon Rekognition Custom Labels, you can use that model when analyzing assets.
The Frame Based Analysis section give the flexibility to switch from the Amazon Rekognition Video API to the Amazon Rekognition Image API. When you toggle the Frame Based Analysis button on, you can determine the frequency that frames are analyzed.
In the Amazon Transcribe settings section:
Select the language that you want Amazon Transcribe to create a transcript of the video in. For a complete list of supported languages, refer to Amazon Transcribe Supported Languages.
If you have created a Custom Vocabulary to improve the accuracy of Amazon Transcribe, you can select that model for the analysis of your assets.
If you have created a Custom Language Model you can activate that model for the analysis of your assets.
In the Amazon Comprehend settings section:
Activate Entity Detection, Sentiment Analysis, and Key phrase Detection.
If you have built a Custom Entity Recognizer to identify custom entities for your business needs, you can activate that as well.
In the Amazon Textract settings section, you can activate the service to extract text from documents that you are analyzing.
Step 6: Viewing statistics
Once content has been analyzed, the web interface has a way to show an aggregation of the metadata generated by the AI/ML Services. This helps to answer the question of what the most popular or frequent tags and detections are in the library.
In the web interface select Stats from the top navigation bar.
Pie charts show the overall and categorized statistics of your content collection.
Monitoring the Guidance with AWS Service Catalog AppRegistry
The Guidance includes a Service Catalog AppRegistry resource to register the CloudFormation template and underlying resources as an application in both Service Catalog AppRegistry and Systems Manager Application Manager.
AWS Systems Manager Application Manager gives you an application-level view into this Guidance and its resources so that you can:
Monitor its resources, costs for the deployed resources across stacks and AWS accounts, and logs associated with this Guidance from a central location.
View operations data for the Guidance’s AWS resources (such as deployment status, Amazon CloudWatch alarms, resource configurations, and operational issues) in the context of an application.
The following figure depicts an example of the application view for the Media2Cloud on AWS stack in Application Manager.
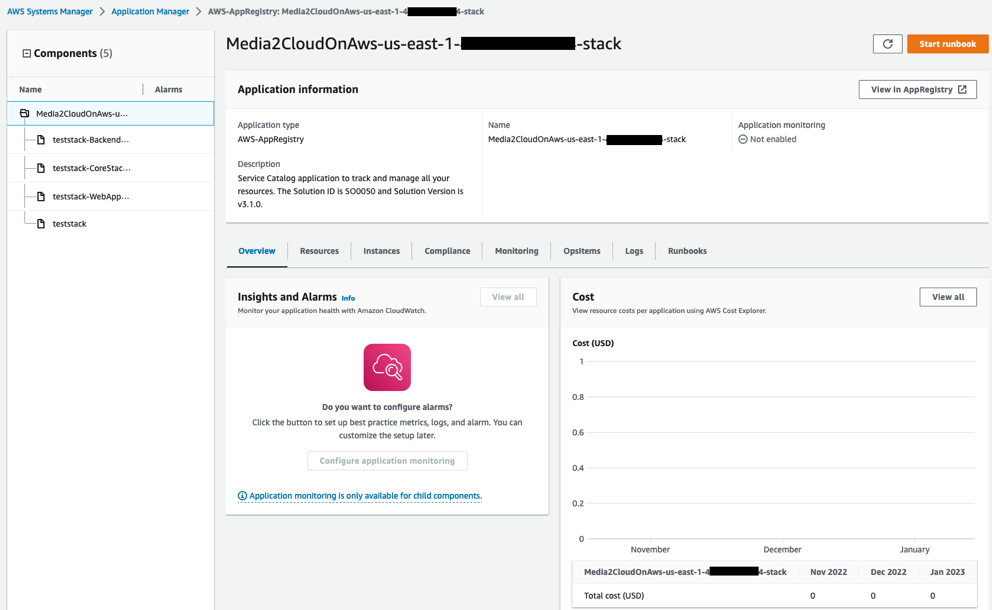
Media2Cloud on AWS stack in Application Manager
Note: You must activate CloudWatch Application Insights, AWS Cost Explorer, and cost allocation tags associated with this Guidance. They are not activated by default.
Activate CloudWatch Application Insights
Sign in to the Systems Manager console.
In the navigation pane, choose Application Manager.
In Applications, choose AppRegistry applications.
In AppRegistry applications, search for the application name for this Guidance and select it.
The next time you open Application Manager, you can find the new application for your Guidance in the AppRegistry application category.
In the Components tree, choose the application stack you want to activate.
In the Monitoring tab, in Application Insights, select Auto-configure Application Monitoring.
Monitoring for your applications is now activated and the following status box appears:
Activate AWS Cost Explorer
You can see the overview of the costs associated with the application and application components within the Application Manager console through integration with AWS Cost Explorer which must be first activated. Cost Explorer helps you manage costs by providing a view of your AWS resource costs and usage over time. To activate Cost Explorer for the Guidance:
Sign in to the AWS Cost Management console.
In the navigation pane, select Cost Explorer.
On the Welcome to Cost Explorer page, choose Launch Cost Explorer.
The activation process can take up to 24 hours to complete. Once activated, you can open the Cost Explorer user interface to further analyze cost data for the Guidance.
Activate cost allocation tags associated with the Guidance
After you activate Cost Explorer, you must activate the cost allocation tags associated with this Guidance to see the costs for this Guidance. The cost allocation tags can only be activated from the management account for the organization. To activate cost allocation tags:
Sign in to the AWS Billing and Cost Management console.
In the navigation pane, select Cost Allocation Tags.
On the Cost allocation tags page, filter for the AppManagerCFNStackKey tag, then select the tag from the results shown.
Choose Activate.
The activation process can take up to 24 hours to complete and the tag data to appear.
Update the Guidance
Media2Cloud on AWS Version 3 can be deployed side-by-side with your previously deployed Media2Cloud on AWS versions (Version 2 and Version 1). However, this version is incompatible with previous versions due to changes of the Amazon DynamoDB tables and Amazon OpenSearch Service indices used by the Guidance.
To migrate from your existing Media2Cloud on AWS version (Version 2 or Version 1) to this version, contact your AWS account representative for assistance.
Uninstall the Guidance
You can uninstall the Media2Cloud on AWS Guidance from the AWS Management Console or by using the AWS Command Line Interface. You must manually delete the S3 buckets, DynamoDB table, and CloudWatch Logs created by this Guidance. AWS Guidances do not automatically delete these resources in case you have stored data to retain.
Using the AWS Management Console
Sign in to the CloudFormation console.
On the Stacks page, select this Guidance’s installation stack.
Choose Delete.
Using AWS Command Line Interface
Determine whether the AWS Command Line Interface (AWS CLI) is available in your environment. For installation instructions, see What Is the AWS Command Line Interface in the AWS CLI User Guide. After confirming that the AWS CLI is available, run the following command.
$ aws cloudformation delete-stack --stack-namec <*installation-stack-name*>
Replace <installation-stack-name> with the name of your CloudFormation stack.
Deleting the Amazon S3 buckets
This Guidance is configured to retain the Guidance-created Amazon S3 bucket (for deploying in an opt-in Region) if you decide to delete the AWS CloudFormation stack to prevent accidental data loss. After uninstalling the Guidance, you can manually delete this S3 bucket if you do not need to retain the data. Follow these steps to delete the Amazon S3 bucket.
Sign in to the Amazon S3 console.
Choose Buckets from the left navigation pane.
Locate the <stack-name> S3 buckets.
Select the S3 bucket and choose Delete.
Repeat the steps until you have deleted all the <stack-name> S3 buckets.
To delete the S3 bucket using AWS CLI, run the following command:
$ aws s3 rb s3://<bucket-name> --force
Alternatively, you can configure the AWS CloudFormation template to delete the S3 buckets automatically. Prior to deleting the stack, change the deletion behavior in the AWS CloudFormation DeletionPolicy attribute.
Deleting the Amazon DynamoDB tables
This Guidance is configured to retain the DynamoDB tables if you decide to delete the AWS CloudFormation stack to prevent accidental data loss. After uninstalling the Guidance, you can manually delete the DynamoDB tables if you do not need to retain the data. Follow these steps:
Sign in to the Amazon DynamoDB console.
Choose Tables from the left navigation pane.
Select the <stack-name> table and choose Delete.
To delete the DynamoDB tables using AWS CLI, run the following command:
$ aws dynamodb delete-table <table-name>
Deleting the CloudWatch Logs
This Guidance retains the CloudWatch Logs if you decide to delete the AWS CloudFormation stack to prevent against accidental data loss. After uninstalling the Guidance, you can manually delete the logs if you do not need to retain the data. Follow these steps to delete the CloudWatch Logs.
Sign in to the Amazon CloudWatch console.
Choose Log Groups from the left navigation pane.
Locate the log groups created by the Guidance.
Select one of the log groups.
Choose Actions and then choose Delete.
Repeat the steps until you have deleted all the Guidance log groups.
Reference
This section includes information about an optional feature for collecting unique metrics for this Guidance, pointers to related resources, and a list of builders who contributed to this Guidance.
Anonymized data collection
This Guidance includes an option to send anonymized operational metrics to AWS. We use this data to better understand how customers use this Guidance and related services and products. When invoked, the following information is collected and sent to AWS:
Guidance ID - The AWS Guidance identifier
Unique ID (UUID) - Randomly generated, unique identifier for each deployment
Timestamp – Media file upload timestamp
Format – The format of the uploaded media file
Size – The size of the file the Guidance processes
Duration – The length of the uploaded video file
AWS owns the data gathered though this survey. Data collection is subject to the Privacy Notice. To opt out of this feature, complete the following steps before launching the AWS CloudFormation template.
Download the AWS CloudFormation template to your local hard drive.
Open the AWS CloudFormation template with a text editor.
Modify the AWS CloudFormation template mapping section from:
Send:
AnonymizedUsage:
Data: "Yes"
to:
Send:
AnonymizedUsage:
Data: "No"
Sign in to the AWS CloudFormation console.
Select Create stack.
On the Create stack page, Specify template section, select Upload a template file.
Under Upload a template file, choose Choose file and select the edited template from your local drive.
Choose Next and follow the steps in Launch the stack in the Deploy the Guidance section of this guide.
Contributors
Ken Shek
Liam Morrison
Adam Sutherland
Aramide Kehinde
Jason Dvorkin
Noor Hassan
San Dim Ciin
Eddie Goynes
Raul Marquez
Revisions
| Date | Change |
|---|---|
| January 2019 | Initial release |
| March 2019 | Modified JSON file descriptions. |
| November 2019 | Updated the analysis workflow engine and added support for ingesting and analyzing images. |
| February 2022 | Release v3.0.0: New web user interface enhancing the user experience. New analysis features included Amazon Rekognition Custom Labels model, Amazon Rekognition Segment Detection, Amazon Transcribe Custom Vocabulary and Custom Language Model, Amazon Comprehend Custom Entity Recognizer. New Amazon OpenSearch Service provided deeper search results that allow customers to find search terms with the timestamps from the archived files. Frame based analysis feature allowing customers to define the time interval (rate) of running the detections on the video content by using Amazon Rekognition Image based API instead of Video based API. For more information, refer to the CHANGELOG.md |
| {:target=”_blank”} file in the GitHub repository. | |
| February 2023 | Release v3.1.0: Added a Service Catalog AppRegistry resource to register the CloudFormation template and underlying resources as an application in both AWS Service Catalog AppRegistry and AWS Systems Manager Application Manager. You can now manage costs, view logs, implement patching, and run automation runbooks for this solution from a central location. For more information, refer to the CHANGELOG.md file in the GitHub repository. |
| April 2023 | Release v3.1.1: Added package-lock.json files to all Lambda state machine functions to snapshot the dependency tree used. For more information, refer to the CHANGELOG.md file in the GitHub repository. |
| April 2023 | Release v3.1.2: Mitigated impact caused by new default settings for S3 Object Ownership (ACLs disabled) for all new S3 buckets. Updated object ownership configuration on the S3 buckets. Updated security patching. For more information, refer to the CHANGELOG.md file in the GitHub repository. |
| August 2023 | Release v3.1.3: Fixed an issue where media analysis result is not visible in the web application. For more information, refer to the CHANGELOG.md file in the GitHub repository. |
| September 2023 | Release v3.1.4: Updated Lambda nodes to Node.js 16. Added unit tests for document ingestion, information about stack update support, and default values to stack parameters. Updated parameter names for consistency. Added fix to allow PDF conversion to PNG files for previously unsupported font types and other bug fixes. For more information, refer to the CHANGELOG.md file in the GitHub repository. |
Notices
Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents AWS current product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. AWS responsibilities and liabilities to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers.
Media2Cloud on AWS is licensed under the terms of the of the Apache License Version 2.0 available at The Apache Software Foundation.