Guidance for Connecting Data Products with Amazon DataZone
Summary: This implementation guide details how to deploy Guidance for Connecting Data Products with Amazon DataZone. Customers using Amazon DataZone seek to expand its governance to additional data sources so that they can unify governance of their entire data infrastructure in a single solution. This Guidance provides a solution built on top of AWS serverless services that allows customers to extend Amazon DataZone’s governance coverage to JDBC data sources; including those based on MySQL, PostgreSQL, Oracle, and SQL Server engines. This Guidance also extends the user's capabilities to easily deploy tools that support their tasks as data producers and consumers.
Guidance Overview
AWS customers are actively building their data governance strategy on top of Amazon DataZone, realizing how they can achieve effective governance of their Amazon Simple Storage Service (Amazon S3)-based data lakes and Amazon Redshift clusters. AWS customers often seek a unified solution to govern all of their data assets–those using Amazon DataZone are no exception, as they look to extend data governance specifically to other JDBC data sources such as Amazon Relational Database Service (Amazon RDS), self-managed databases, or third-party solutions.
The purpose of this Guidance is to help customers extend governance with Amazon DataZone and be able to cover common JDBC data sources, so that teams can share and collaborate around data assets hosted in data repositories such as Amazon Aurora, MySQL, PostgreSQL, Oracle, or SQL Server databases, either on top of Amazon RDS or self-managed.
This Guidance is built on top of the AWS Cloud Development Kit (CDK) and is designed to be an add-on for Amazon DataZone that is easy to deploy, extend, and customize for any customer needs. It is a fully automated solution that aims to be seamless from a user experience standpoint and covers the entire subscription lifecycle.
Although it currently supports MySQL, PostgreSQL, SQL Server, and Oracle engine integration, this Guidance can be extended to support other SQL and NoSQL databases in addition to data warehouse solutions.
Features and benefits
This section describes features and benefits specific to this Guidance.
Workflows to extend the Amazon DataZone environment’s capabilities on creation
This Guidance includes workflows orchestrated through AWS Step Functions that will extend Amazon DataZone’s default data lake environment roles to be able to leverage new capabilities provided by this Guidance. Provided workflows will also clean roles on deletion for a seamless experience when deleting environments.
Workflows to grant and revoke subscriptions to published data assets mapping to JDBC sources
The Guidance includes workflows orchestrated through AWS Step Functions that will fulfill grants of approved subscriptions to published data assets, mapping to JDBC sources in a way that can’t be achieved as a native feature of Amazon DataZone. Provided workflows will also fulfill revoke actions on previously granted subscriptions.
Toolkit targeted to producer users that want to easily publish data assets hosted on JDBC sources
The Guidance includes a product portfolio (toolkit) on top of AWS Service Catalog that enables producer users to crawl and infer schema of the data assets in their JDBC sources and store it in AWS Glue Data Catalog, where it can be published from using available Amazon DataZone publishing mechanisms. Products available in the toolkit can be deployed in a self-service manner and are fully governed by a governance team so that security standards are followed.
Toolkit targeted to consumer users that want to easily consume data assets, hosted on JDBC sources to which they are subscribed
The Guidance includes a product portfolio (toolkit) on top of Service Catalog that enables consumer users to query and consume data assets hosted in JDBC sources to which they are subscribed. Products available in the toolkit can be deployed in a self-service manner and are fully governed by a governance team so that security standards are followed.
Workflow metadata and tracking tools
The Guidance includes a metadata layer on top of Amazon DynamoDB, targeted to governance teams, so that they are able to track all outputs performed by subscription-related workflows.
Use cases
This section describes use cases specific to this Guidance.
Extend user capabilities for producer- and consumer-related tasks
Users can leverage the Guidance’s toolkit to deploy and use resources in a self-service manner to perform activities common to producers and consumers. The toolkit offers a governed way to provide custom tools to users that can be extended to the customer’s specific needs.
Effectively govern data assets hosted in JDBC sources using Amazon DataZone without the need to replicate it to Amazon Redshift or to Amazon S3 and AWS Glue-backed data lakes
Customers can map, publish, subscribe, and consume data assets hosted in JDBC sources including MySQL, PostgreSQL, Oracle, and SQL Server databases. Sources can be self-managed or managed on top of Amazon RDS. With this Guidance, customers can have a seamless experience, similar to the one provided by Amazon DataZone, when working and collaborating with data assets hosted by JDBC engines.
Concepts and definitions
This section describes key concepts and defines terminology specific to this Guidance.
Environment
Environments are an Amazon DataZone construct that allow users and teams that belong to the same Amazon DataZone project to publish their owned data assets and to consume other project’s published data assets with a granted subscription. This is the construct that enables users and teams to work with data when using Amazon DataZone.
Data asset
A data asset refers to a dataset that will be used as means of collaboration between users and teams. Normally, it maps to a single table that can be hosted in a data lake, a database, or a data warehouse. A data asset can be classified in Amazon DataZone as “Managed” or “Unmanaged.” Managed data assets can have grants fulfilled automatically on any Amazon DataZone when a subscription to it is approved (including data assets hosted in Amazon S3 and Amazon Redshift). Unmanaged data assets cannot have grants managed automatically by Amazon DataZone, and there will be no attempts to do so.
Producer
The producer is the role that a user or team can assume in the context of data collaboration. The main goal of a data producer is to produce data that other users or teams can use. This translates to “publishing” data assets in Amazon DataZone through an environment available to the user.
Consumer
The consumer is the role that a user or team can assume in the context of data collaboration. The main goal of a data consumer is to consume data that other users or teams are producing. This translates to “subscribing” to data assets in Amazon DataZone through an environment available to the user and to query it through any means.
Subscription
A subscription is an Amazon DataZone construct that represents whether a consumer project has access to a data asset published by a producer. A subscription is created when a consumer submits a “Subscription Request” and is accepted by the producer. When a subscription is established, environments from the consumer project (whose profile is able to consume the data asset) will be added to the subscription as “Subscription Targets.” Note that “Subscription Targets” are associated only for Managed data assets. For Unmanaged data assets, no “Subscription Targets” are associated to the subscription, but still, the subscription is created.
Toolkit
Producers and consumers need to perform common tasks tied to the Amazon DataZone functionality, such as mapping data assets to the AWS Glue Data Catalog or querying data assets after subscriptions are granted. The toolkit is a set of tools, in the form of products of a Service Catalog portfolio, that allows users to deploy resources that they can use to perform these tasks.
Workflow
A workflow is a set of steps that are executed through an orchestrated mechanism and as a result of a specific event that was initiated in Amazon DataZone. Workflows are orchestrated through AWS Step Functions, and each step can be executed through any AWS service. The current implementation frequently leverages AWS Lambda functions as initiators of steps in the workflows.
Secret
A secret is a construct of Amazon Secrets Manager used to store highly confidential variables, such as database credentials. Secrets are the means used in this Guidance to grant access to subscriptions and enable automatic collaboration between producer and consumers (at an environment level) for data assets hosted in JDBC sources.
Architecture Overview
This section provides a reference implementation architecture diagram for the components deployed with this Guidance.
How does this solution work?
To better understand the details of this solution, review the actions that need to be completed before users can collaborate around a data asset hosted in a JDBC source, in a self-service manner, using Amazon DataZone service:
- Process 1: A producer needs to create a project with an environment (based on the default data lake profile) that will host and publish the data asset in Amazon DataZone.
- Process 2: A producer needs to map the data asset into an AWS Glue database. We recommend using the AWS Glue database associated to the producer’s Amazon DataZone environment.
- Process 3: The producer needs to run the Amazon DataZone environment’s data source that publishes the data asset into the Amazon DataZone common business catalog.
- Process 4: A consumer needs to create a project with an environment (based on the default data lake profile) that will be used to subscribe to and consume the published data asset.
- Process 5: A consumer needs to submit a subscription request (with its justification) to get an access grant to the published data asset. This is done from within the consumer’s Amazon DataZone project in the Amazon DataZone portal.
- Process 6: A producer needs to accept the subscription request in the Amazon DataZone portal, so that access to the data asset is granted to the consumer. Depending on whether the data asset is Managed or Unmanaged, Amazon DataZone will attempt to fulfill grants for applicable environments (based on their profile) of the subscribing project and add them as “Subscription Targets”.
- Process 7: A consumer needs establish a mechanism that allows for the consumption of the published data asset.
This Guidance will provide a set of mechanisms that will simplify or automate the high-level processes described above, including:
- A Service Catalog portfolio hosting a complementary toolkit that can be used in a self-service manner, which allow users (producers and consumers) to:
- Map source data asset hosted in a JDBC source into a target AWS Glue database (associated to an Amazon DataZone environment). (Process 2)
- Consume and query a published data asset hosted in a JDBC source after access is granted. This is done through an Athena connector (associated to an Amazon DataZone environment). (Process 7)
- A set of automated workflows that will initiate on specific Amazon DataZone events, such as:
- When a new Amazon DataZone environment is successfully deployed so that default data lake environment capabilities are extended to support this Guidance’s complimentary toolkit, described above. (Processes 1 and 4)
- When a subscription request to a published Unmanaged data asset is accepted so that actual access is granted automatically to the corresponding environments of the consumer project. (Process 6)
- When a subscription to a published data asset is revoked or canceled so that actual access is revoked automatically from the corresponding environments of the consumer project.
- When an existing Amazon DataZone data lake environment deletion starts, so that non-default Amazon DataZone capabilities are removed from environment.
Processes 3 and 5 don’t need any complementary task to be completed (whether automatically or manually).
Architecture diagram
Figures 1a and 1b show this Guidance’s reference architecture, illustrating the workflow for when a subscription request is approved as described above (which is considered the core functionality of this solution). It also illustrates how tools in the Guidance toolkit are leveraged by producers and consumers before and after workflow completion.
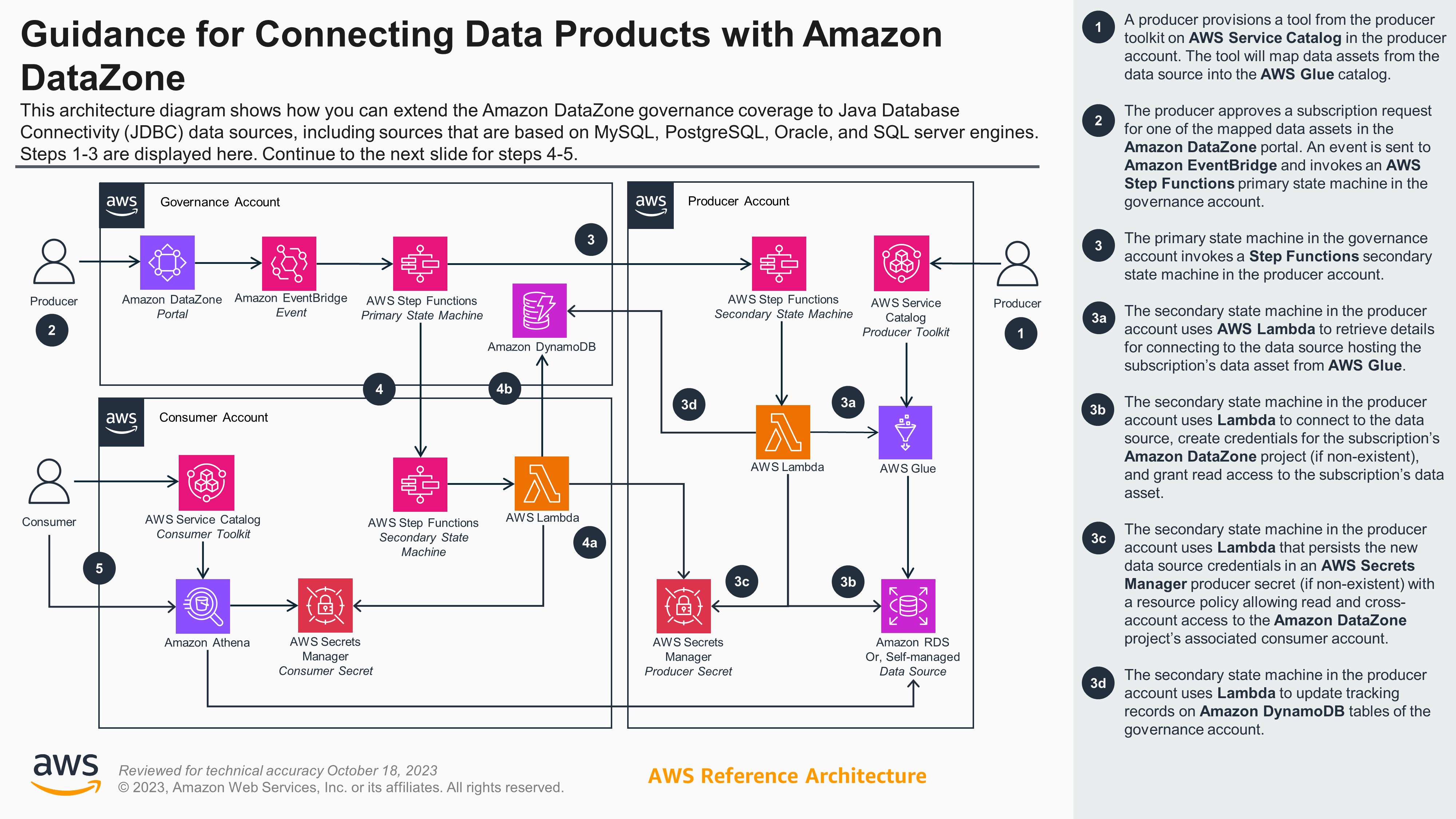
Figure 1a. Guidance for Connecting Data Products with Amazon DataZone reference architecture and steps - Part 1
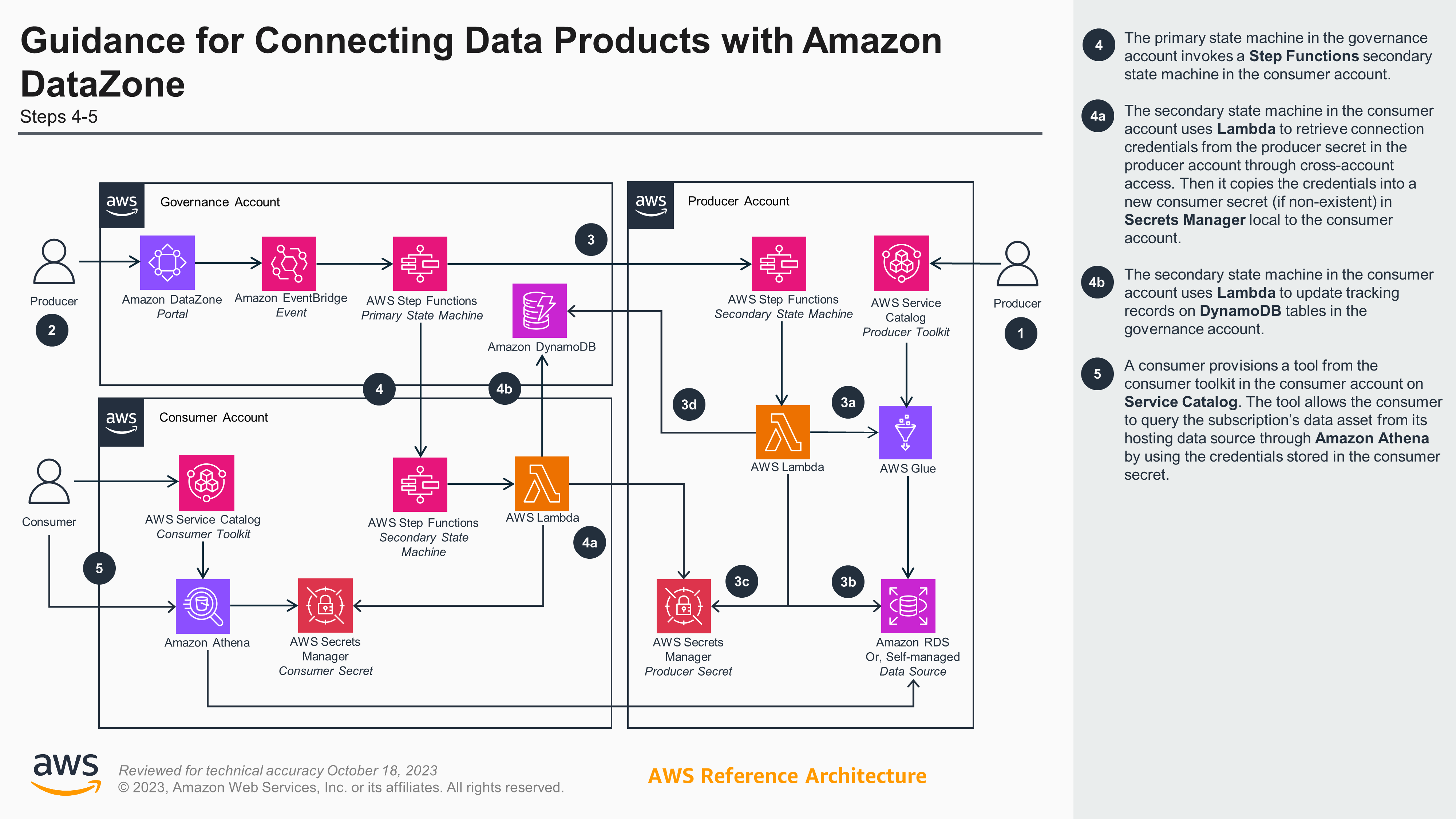
Figure 1b. Guidance for Connecting Data Products with Amazon DataZone reference architecture and steps - Part 2
AWS Well-Architected design considerations
This Guidance uses the best practices from the AWS Well-Architected Framework, which helps customers design and operate workloads in the cloud that align to best practices for operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability.
This section describes how the design principles and best practices of the Well-Architected Framework benefit this solution.
Operational excellence
This section describes how we architected this solution using the principles and best practices of the Operational Excellence pillar.
AWS Cloud Development Kit (AWS CDK), Service Catalog, Lambda, Step Functions, Amazon CloudWatch, and DynamoDB are services that work in tandem to support operational excellence. First, AWS CDK automates and simplifies the configuration of this Guidance at scale, allowing it to be deployed from within any continuous integration and continuous delivery (CI/CD) tooling that you use. Second, Service Catalog automates and simplifies the deployment of user-targeted tools so you can deploy these tools in a way that supports your tasks, with the assurance that all deployed resources are aligned with your governance standards. Third, Lambda and Step Functions are serverless, meaning no infrastructure needs to be managed, thereby reducing your operational complexity. Fourth, DynamoDB is used as a storage layer to track all outputs for each component of this Guidance, providing governance teams visibility to support management activities.
Security
This section describes how we architected this solution using the principles and best practices of the Security pillar.
AWS Identity and Access Management (IAM), AWS Secrets Manager, and AWS Key Management Service (AWS KMS) are services that protect both your information and systems. To start, all inter-service communications use IAM roles, whereas the multi-account option leverages IAM roles with cross-account access. And, all roles follow least-privileged access, that is, they only contain the minimum permissions required so that the service can function properly. Some resources do include tag-based policies to restrict cross-project access to unauthorized resources. In addition, Secrets Manager is used to manage credentials to data sources that are created through the components of this solution, and stored as secrets with highly restrictive access. Finally, AWS KMS is used to leverage customer-managed keys for encrypting secrets in Secrets Manager.
Reliability
This section describes how we architected this solution using the principles and best practices of the Reliability pillar.
Step Functions, Lambda, Amazon EventBridge, and DynamoDB are serverless AWS services, meaning that they ensure high availability at a Region level by default. These services also offer recovery from service failure aligned to service-specific service level agreements (SLAs) to help your workloads perform their intended functions correctly and consistently.
Performance Efficiency
This section describes how we architected this solution using the principles and best practices of the Performance Efficiency pillar.
When configuring this Guidance, Lambda functions are deployed as close as possible to the data source for improved performance. Additionally, execution logic inside every Lambda function is designed to eliminate redundant operations and to reuse previously created resources, like secrets, when applicable. Lambda supports the core functionality when connecting to data sources for this Guidance, as it is optimized to be lightweight and high performing.
Cost Optimization
This section describes how we architected this solution using the principles and best practices of the Cost Optimization pillar.
Step Functions, Lambda, EventBridge, DynamoDB, Secrets Manager, and AWS KMS are all serverless AWS services, so you are only charged for what you use. With AWS Glue, you pay only for the time that your extract, transform, and load (ETL) takes to run. There are no resources to manage or upfront costs, nor are you charged for startup or shutdown time.
Sustainability
This section describes how we architected this solution using the principles and best practices of the Sustainability pillar.
With Step Functions, Lambda, EventBridge, DynamoDB, Secrets Manager, and AWS KMS being serverless AWS services, they can scale up or down as needed, minimizing the environmental impact of the backend services. For example, EventBridge is an event-driven application that provides near real-time access to data in AWS services, your own applications, or other software as a service (SaaS) applications. With this visibility, you can gain a better understanding of the environmental impacts of the services you are using, quantify those impacts through the entire workload lifecycle, and then apply appropriate design principles to reduce those impacts.
Guidance Components
Toolkit product descriptions
As part of this Guidance, we provide a complimentary toolkit to assist users on tasks common to the producer and consumer roles, such as mapping data assets hosted in your source JDBC sources or querying those assets when subscribed.
The provided toolkit is a baseline that can be customized and extended to support any product that may be useful for each customer. It is a governed means to provide mechanisms to producers and consumers so they can execute their role-specific tasks and collaborate around data more effectively.
Producer toolkit
For users or teams assuming the producer role, they are able to deploy and use the following Service Catalog products:
- DataZone Connectors - Producer - Glue JDBC Connector: This product deploys an AWS Glue Connection for JDBC sources. The AWS Glue Connection currently supports MySQL, PostgreSQL, Oracle, and SQL Server engines and connects to the source database through a secret in Secrets Manager.
- DataZone Connectors - Producer - Glue JDBC Connector with Crawler: This product deploys an AWS Glue Connection for JDBC sources. The AWS Glue Connection currently supports MySQL, PostgreSQL, Oracle, and SQL Server engines and connects to source database through a secret in Secrets Manager. Additionally, this product deploys an AWS Glue Crawler that will map all data assets within a path inside the source database and maps the captured metadata as data assets in a target AWS Glue database.
Consumer toolkit
For users or teams assuming the consumer role, they are able to deploy and use the following Service Catalog products:
- DataZone Connectors - Consumer - Athena MySQL JDBC Connector: This product deploys an Athena connector for MySQL engine, based on an Athena data source, an IAM role, and a Lambda function that executes queries on behalf of the end user. The Lambda function uses a secret in Secrets Manager to retrieve connection credentials and is limited by the actions granted from within the source database.
- DataZone Connectors - Consumer - Athena PostgreSQL JDBC Connector: This product deploys an Athena connector for PostgreSQL engine, based on an Athena data source, an IAM role, and an Lambda function that executes queries on behalf of the end user. The Lambda function uses a secret in Secrets Manager to retrieve connection credentials and is limited by the actions granted from within the source database.
- DataZone Connectors - Consumer - Athena SQL Server JDBC Connector: This product deploys an Athena connector for SQL Server engine, based on an Athena data source, an IAM role, and a Lambda function that executes queries on behalf of the end user. The Lambda function uses a secret in Secrets Manager to retrieve connection credentials and is limited by the actions granted from within the source database.
- DataZone Connectors - Consumer - Athena Oracle JDBC Connector: This product deploys an Athena connector for Oracle engine, based on an Athena data source, an IAM role, and a Lambda function that executes queries on behalf of the end user. The Lambda function uses a secret in Secrets Manager to retrieve connection credentials and is limited by the actions granted from within the source database.
Workflow descriptions
As part of this Guidance, we provide a set of workflows that will initiate automatically as a response to specific events in Amazon DataZone. The purpose of these workflows is to support grants of data assets hosted in JDBC sources and governed through Amazon DataZone.
Create a new Amazon DataZone environment workflow
This workflow is key for enabling Amazon DataZone governed users to extend their default capabilities and be able to leverage the solution’s toolkit for both producer and consumer tasks.
The following figure illustrates the workflow execution steps in a multi-account setup.
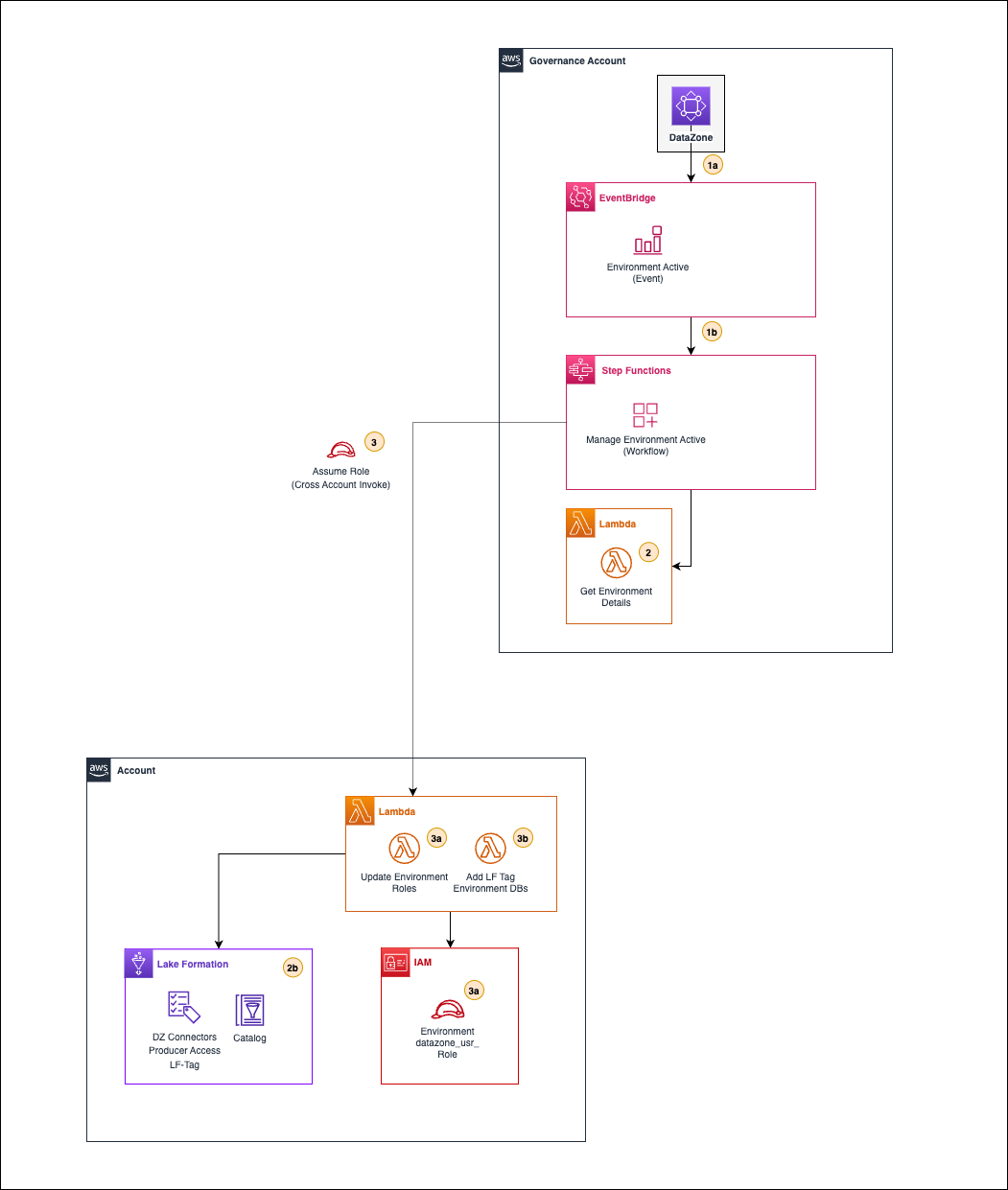
Figure 2. Create a new Amazon DataZone environment workflow
As illustrated in the figure, the workflow follows these steps:
- Amazon DataZone will send an “ACTIVE” event to the default event bus (in EventBridge) in the governance account. A custom rule will capture this event (1a) and start a primary state machine (Step Functions) (1b) to handle a new environment creation.
- The primary state machine will invoke a local Lambda function (2) to retrieve new environment details.
- The primary state machine will invoke a series of Lambda functions (3) in the Amazon DataZone environment associated account by assuming a role that allows it. First, the Lambda function (3a) will update the environment roles by extending their permission boundary and adding an inline policy with new allowed actions. The second Lambda function (3b) will add an LF-Tag to all the environment databases in the AWS Glue Data Catalog, allowing access to resources involved in other workflows from the solution.
Grant access to a published asset for an Amazon DataZone environment workflow
This workflow can be considered the core element of this Guidance, since it is the one that enables automatic grants for JDBC sources, allowing collaboration around these extended data sources.
The following figure illustrates the workflow execution steps in a multi-account setup. Note that it also illustrates how other elements of the solution (complimentary toolkit) plays in the overall workflow.
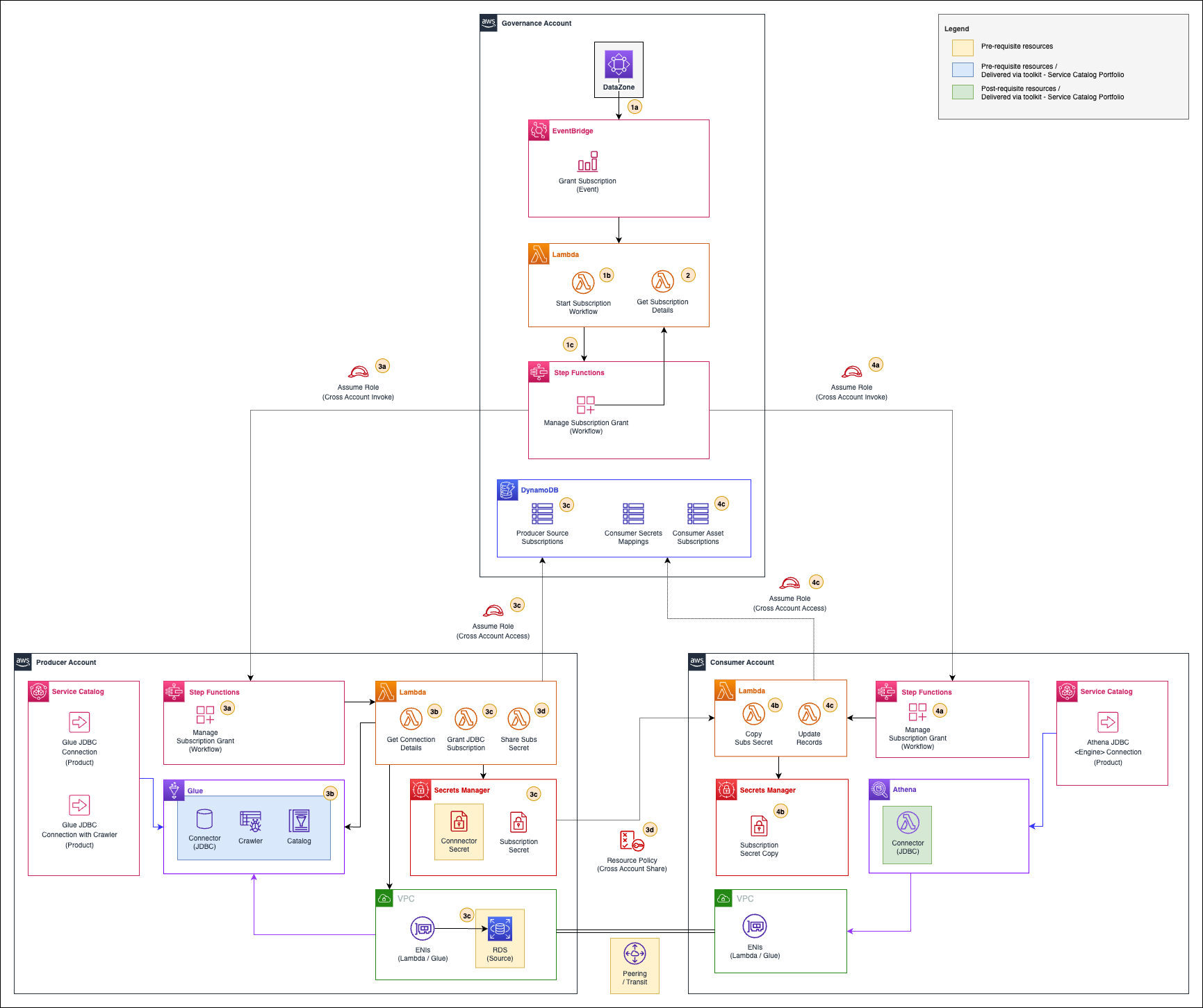
Figure 3. Grant access to a published asset for an Amazon DataZone environment workflow
Note that the figure shows some of the elements of the solution’s toolkit that will support activities in the collaboration lifecycle reviewed above. Using the complimentary toolkit, you will be able to easily deploy resources that will connect and map data assets from your database into the AWS Glue Data Catalog (for producers) and consume published data assets that you are subscribed to (for consumers).
As explained in the figure, the workflow follows the following steps:
- Amazon DataZone will send an “APPROVE” event to default event bus (EventBridge) in the governance account. A custom rule will capture this event (1a) and invoke a local Lambda function (1b), which will retrieve all data lake environments for the consumer project and execute, per each applicable environment, a primary state machine (1c) to grant it access to the subscribed asset.
- The primary state machine will invoke a local Lambda function that will retrieve all subscription details, including the source data asset and consumer environment details.
The primary state machine will invoke a secondary state machine in the producer account (3a) by assuming a role that allows it. The workflow will get source connection details (3b) from the AWS Glue table metadata associated to the subscribed data asset. With the connection details, the workflow will connect to the source database and create a new user for the consumer environment with a random password (if nonexistent) and grant read access to the subscribed data asset. A new secret with the connection credentials will be created, if nonexistent, and a metadata record to track source subscriptions will be updated (3c). Finally, a resource policy that allows cross-account access will be added to the new secret (3d).
Metadata updates will use cross-account role access into the governance account.
- The primary state machine will invoke a secondary state machine in the consumer account (4a) by assuming a role that allows it. The workflow will retrieve the shared secret from the producer account and make a copy of it into a new secret local to the consumer account (4b). Records that track producer-consumer secret mapping and asset subscriptions will be updated (4c) using cross-account role access into governance account.
Revoke access to a published asset from an Amazon DataZone environment workflow
This workflow can be considered the core element counterpart of this Guidance, since it is the one that enables automatic revocations for JDBC sources, allowing collaboration around these extended data sources.
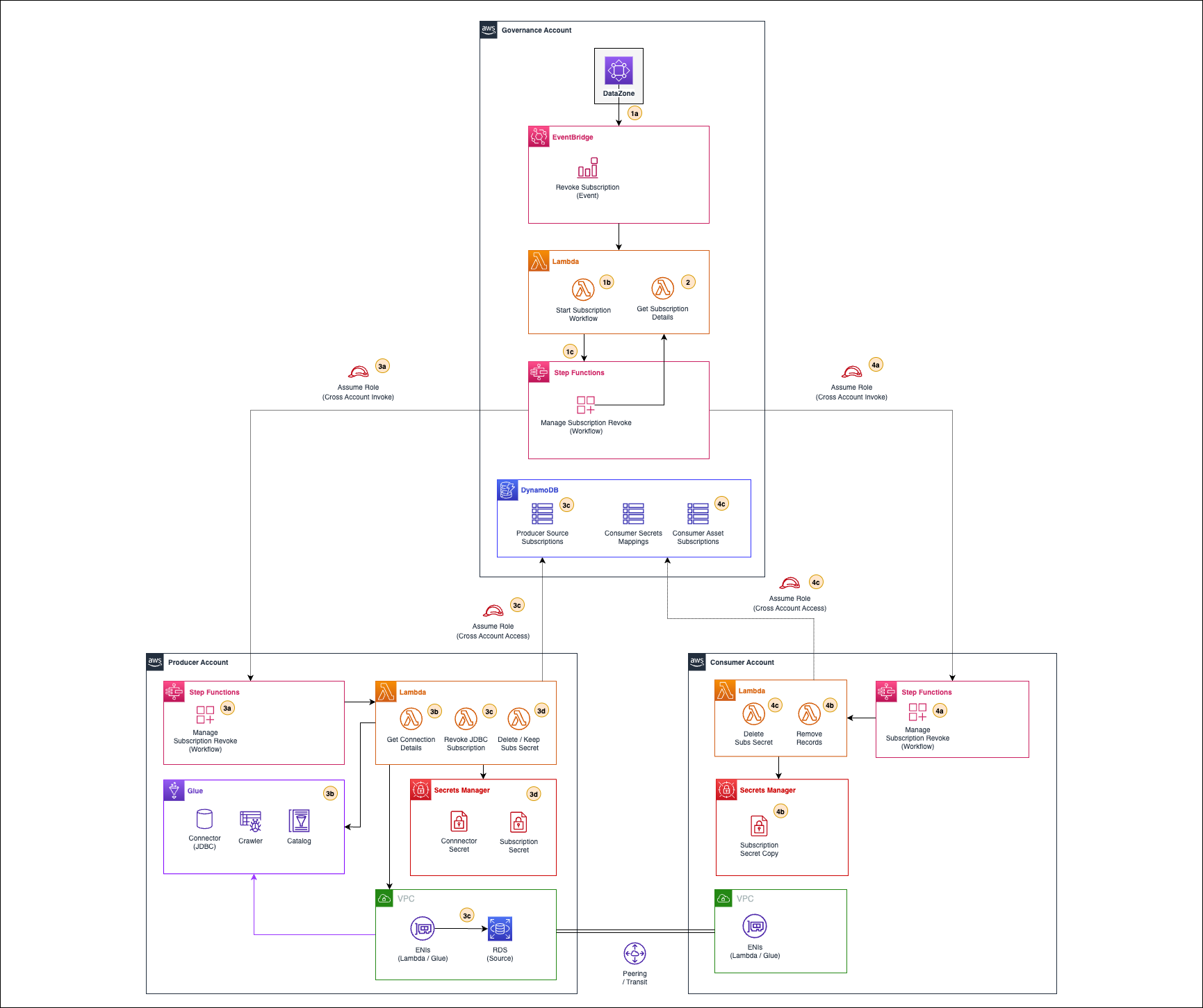
Figure 4. Revoke access to a published asset from an Amazon DataZone environment workflow
The following figure illustrates the workflow execution steps in a multi-account setup.
As explained in the figure, the workflow follows the following steps:
- Amazon DataZone will send a “REVOKE” event to default event bus (EventBridge) in the governance account. A custom rule will capture this event (1a) and invoke a local Lambda function (1b), which will retrieve all data lake environments for the consumer project and execute, per each applicable environment, a primary state machine (1c) to revoke its access to the subscribed asset.
- The primary state machine will invoke a local Lambda function that will retrieve all subscription details, including source data asset and consumer environment details.
The primary state machine invokes a secondary state machine in the producer account (3a) by assuming a role that allows it. The workflow will get source connection details (3b) from the AWS Glue table metadata associated to the subscribed data asset. With the connection details, the workflow will connect to the source and revoke access to the data asset. If no other grant is left for the environment’s user, it will delete the user as well and the subscription metadata record will be updated or removed (3c). Finally, the secret will be deleted if a user was deleted in the source database; otherwise it will be kept unmodified (3d).
Metadata updates will use cross-account role access into governance account.
- The primary state machine will invoke a secondary state machine in the consumer account (4a) by assuming a role in the consumer account that allows it. The workflow will delete the local secret if the user and producer secret were deleted; otherwise, it will be kept (4c). Records that track producer-consumer secret mapping and asset subscription will be updated (4b) using cross-account role access into governance account.
Deleting an existing Amazon DataZone environment workflow
This workflow is the counterpart of the “Create Environment” workflow. It is necessary since it cleans the updated Amazon DataZone environment’s roles before deletion to prevent any error.
The following figure illustrates the workflow execution steps in a multi-account setup.
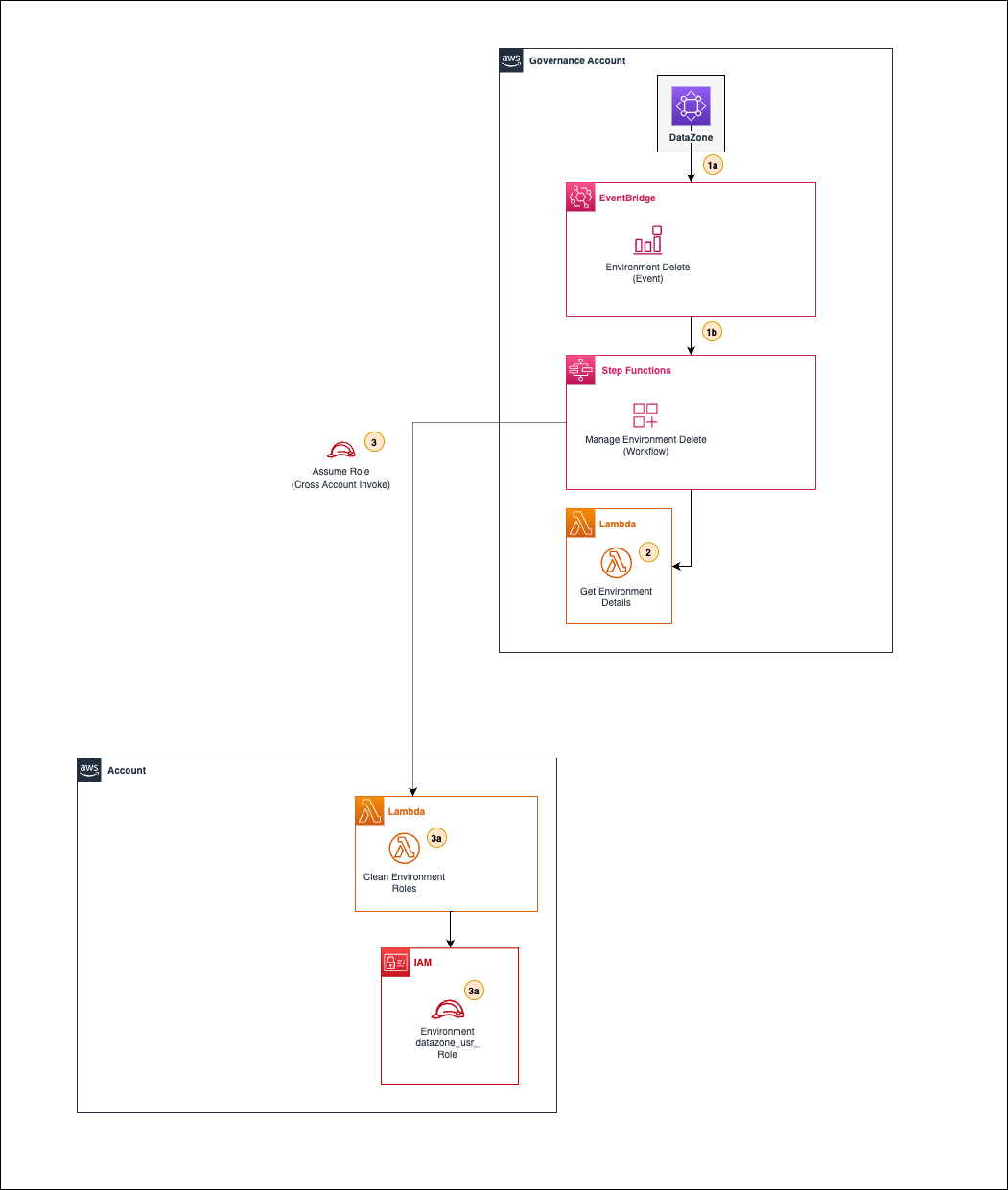
Figure 5. Deleting an existing Amazon DataZone environment workflow
As illustrated in the figure, the workflow follows these steps:
- Amazon DataZone will send a “DELETING” event to the default event bus (EventBridge) in the governance account. A custom rule will capture this event (1a) and start a primary state machine (1b) to handle an existing environment deletion.
- The primary state machine will invoke a local Lambda function (2) to retrieve existing environment details.
- The primary state machine will invoke a Lambda function (3) in the associated account by assuming a role that allows it. The Lambda function (3a) will update the environment roles by rolling back the permission boundary and removing the previously added inline policy.
AWS services in this Guidance
The following AWS services are included in this solution:
| AWS Service | Description |
|---|---|
| Amazon DataZone | Core. Core data governance service whose capabilities are extended when deploying this add-on solution. |
| Amazon EventBridge | Core. Used as mechanism to capture core events and trigger solution’s corresponding workflow. |
| AWS Step Functions | Core. Used as orchestration engine to execute core solution workflows. |
| AWS Lambda | Core. Provides logic for the workflow tasks, such as extending the environment’s capabilities, creating and sharing secrets with environment credentials, and more. |
| AWS CloudFormation | Core. Used to deploy all components of the solution and as a means to deploy products in the complimentary toolkit. |
| AWS Identity and Access Management | Core. Provides required scoped permissions to all components on the solution. |
| AWS Key Management Service | Core. Stores accounts’ encryption keys that will be used to secure secrets with access credentials to JDBC sources. |
| AWS Secrets Manager | Core. Used to store database credentials as secrets. Each consumer environment with granted subscription to one or many data assets in the same JDBC source will have its own individual credentials (secret). |
| Amazon DynamoDB | Core. Used to store workflows’ output metadata. Governance teams are able to track subscription details for JDBC backed data assets. |
| AWS Lake Formation | Core. Used to grant access to AWS Glue resources associated to Amazon DataZone domains. |
| AWS Glue | Core. Multiple components from AWS Glue are leveraged. AWS Glue Data Catalog is used as the direct publishing source for Amazon DataZone business catalog. AWS Glue connectors and crawlers connect on infer schemas from data assets hosted in JDBC sources. |
| AWS Service Catalog | Optional. Used as a means to provide a complimentary toolkit for producers and consumers, so that they can provision products to initiate tasks specific to their roles in a self-service manner. |
| Amazon Athena | Optional. Used as one of the consumption mechanisms that allow users and teams to query data assets that they are subscribed to, either on top of Amazon S3-backed data lakes or JDBC data sources. |
Plan your Deployment
This section describes the cost, security, AWS Regions, and other considerations prior to deploying the solution.
Cost
You are responsible for the cost of the AWS services used while running this solution. As of this revision, the cost for running this solution with the default settings in the US East (N. Virginia) is approximately $78.21 per month. These costs are for the resources shown in the sample cost table.
We recommend creating a budget through AWS Cost Explorer to help manage costs. Prices are subject to change. For full details, see the pricing webpage for each AWS service used in this solution.
Sample cost table
The following table provides a sample cost breakdown for deploying this solution with the default parameters in the US East (N. Virginia) Region for one month.
The estimate presented below assumes the following usage-pattern:
- Number of governed accounts: 10
- Number of secrets (subscriptions to JDBC sources): 100
- Number of environment related workflow (creation / deletion) executions in a month: 20
- Number of subscription related workflow (grant / revoke) executions in a month: 200
- Number of AWS Glue crawlers executions in a month: 1500
- Average execution time of AWS Glue crawlers in minutes: 2
- Number of Amazon Athena queries on top of JDBC sources in a month: 20.000
- Average execution time of an Amazon Athena query in seconds: 7
- Average data volume (in MBs) scanned by Amazon Athena per query: 10
However, each customer has its own specific usage-pattern driven by number of users, teams, and data assets on which they will be collaborating.
The cost estimate will be divided in two sections: Section 1 shows the costs for the Amazon DataZone Connectors Guidance itself and resources supporting its core capabilities. Section 2 shows costs for user activity related to producing and consuming data assets. These costs needs to be assessed individually.
The majority of the monthly cost is dependent on Secrets Manager and AWS KMS.
Section 1
| AWS Service | Dimensions | Cost (USD) |
|---|---|---|
| AWS Step Functions | 220 workflow requests per month with 5 average transitions per request | $0.00 |
| AWS Lambda | 1100 requests per month with average duration of 200 ms and 128 MB memory | $0.00 |
| Amazon DynamoDB | 3 GB of total storage and 600 writes per month of on demand capacity | $0.76 |
| AWS Key Management Service | 10 CMKs serving 400 symmetric requests per month | $10.00 |
| AWS Secrets Manager | 100 secrets serving 21000 API calls per month | $40.10 |
| Amazon EventBridge | 220 custom events per month | $0.00 |
Section 2
The majority of the monthly cost is dependent on AWS Glue crawlers. Note that these services are associated to tasks that users need to perform to operate on top of Amazon DataZone and that are not a requirement for the solution. You have the option to deploy these resources through the toolkit provided in this solution or by any other means they have available.
| AWS Service | Dimensions | Cost (USD) |
|---|---|---|
| AWS Glue | 1500 crawler executions with 2 minutes average execution time | $26.40 |
| Amazon Athena | 20000 queries per month scanning 10 MB of data in average per query | $0.95 |
| AWS Lambda | 20000 requests per month with average duration of 7000 ms and 128 MB memory | $0.76 |
Security
When you build systems on AWS infrastructure, security responsibilities are shared between you and AWS. This shared responsibility model reduces your operational burden because AWS operates, manages, and controls the components, including the host operating system, the virtualization layer, and the physical security of the facilities in which the services operate. For more information about AWS security, visit AWS Cloud Security.
IAM roles
IAM roles allow customers to assign granular access policies and permissions to services and users on the AWS Cloud. This Guidance creates IAM roles that grant the solution’s resources perform actions on other regional resources. Additionally, it uses a resource policy to restrict access to shared resources between accounts.
Cross-account access is done through cross-account roles with limited permissions that allow only intended actions. This pattern is used both ways: 1/ when accessing governed accounts from the governance central account and 2/ when accessing the governance central account from any of the governed accounts.
AWS KMS keys
This Guidance will deploy AWS KMS customer managed keys (one per account) to encrypt secrets used to share credentials. We recommend reviewing Security best practices for AWS Key Management Service to enhance the protection of your encryption keys.
AWS Secrets Manager
Secrets are the core means by which this Guidance enables data sharing and collaboration between producers and consumers on top of JDBC hosted data assets. Access to secrets are protected by resource policies, and contents are encrypted by account specific CMKs in AWS KMS. Secrets are deleted when not needed by the Guidance.
Data Retention
Depending on the business’s requirements and data classification policies, it is advisable to set up Amazon DynamoDB backups to persist metadata long term. You can also set up Amazon S3 Lifecycle Configuration to manage the retention of backed up data or data stored by Athena supporting customer queries.
Networking considerations
This Guidance does not deploy any networking resources. The Guidance is intended to be deployed on top of your current networking setup. Note that cross-account access to JDBC sources (such as RDS database instances or self-managed databases) needs a proper networking setup that allows reachability between consumer and producer accounts. You need to guarantee such connectivity between all accounts that will be collaborating. We suggest looking into VPC peering or setting up AWS Transit Gateway as alternatives to enable such connectivity.
DevOps considerations
This Guidance does not include a DevOps tool selection. It is an AWS CDK solution that can be deployed using any CI/CD tool (AWS native or third-party) that you prefer.
However, it is important to understand the deployment steps, considering that this Guidance does not cover a fixed number of accounts when deployed in a multi-account setup. Each account deployment should be parametrized with account specific resources, such as virtual private cloud (VPC) details.
Supported AWS Regions
This Guidance is dependent on Amazon DataZone, which is not currently available in all AWS Regions. For the most current availability of AWS services by Region, see the AWS Regional Services List.
This Guidance is available in the following AWS Regions:
- US East (N. Virginia)
- US West (Oregon)
Quotas
Service quotas, also referred to as limits, are the maximum number of service resources or operations for your AWS account.
Quotas for AWS services in this Guidance
Make sure you have sufficient quota for each of the services implemented in this Guidance. For more information, see AWS service quotas.
Use the following links to go to the page for that service. To view the service quotas for all AWS services in the documentation without switching pages, view the information in the Service endpoints and quotas page in the PDF instead.
AWS CloudFormation quotas
Your AWS account has AWS CloudFormation quotas that you should be aware of when launching the stack in this Guidance. By understanding these quotas, you can avoid limitation errors that would prevent you from deploying this solution successfully. For more information, review AWS CloudFormation quotas in the AWS CloudFormation User Guide.
Deploy the Guidance
This Guidance uses the AWS CDK CLI to automate its deployment. It contains two applications: the first application is intended to be deployed in the central governance account (where the Amazon DataZone domain is configured), and the second application is intended to be deployed in each of the governed accounts (where data sources are hosted and where producer and consumer project environments will be allocated).
Each application will be parametrized and deployed separately so that it includes account-specific resources, such as networking- and security-related resources.
It will take approximately 15-20 minutes to deploy this Guidance.
You can follow this implementation guide whether you want to deploy the Guidance in a multi-account environment or a single-account environment. For a single-account environment, remember that both governed and governance accounts should point to the same single account.
Prerequisites
Complete the following prerequisites to deploy the Guidance.
Create virtual environment and install requirements
It is assumed that you have python3 installed already with package venv available. To create a virtual environment on MacOS and Linux, run the following command while standing in the root directory:
python3 -m venv .venv
After the virtual environment is created, use the following command to activate it, as it is needed for next steps in the deployment of this Guidance.
source .venv/bin/activate
Once the virtual environment is activated, you can install the required dependencies. Run the following command:
pip install -r requirements.txt
Check that all requirements were successfully installed before moving to the next step.
Bootstrap governance and governed accounts
In order to bootstrap both the governance and all the governed accounts, you need to have an AWS CLI profile for the governance and for each governed account already in place. For more details, review the AWS documentation for configuration and credential file settings.
Run the following AWS CDK command for the governance account and for each of the governed accounts to allocate base AWS CDK resources (known as bootstrapping) in each one of them. Replace <PROFILE_NAME>, <ACCOUNT_ID> and <AWS_REGION> with the corresponding profile name, account id, and region that maps to the account you are going to bootstrap.
cdk bootstrap aws://<ACCOUNT_ID>/<AWS_REGION> --profile <PROFILE_NAME>
As part of the bootstrapping process, AWS CDK will create a set of IAM roles that will be used when deploying resources in your accounts. These can be accessed through the AWS console or using the AWS CLI.
For your governed accounts bootstrap deployments only, take note of the name of the new AWS CDK CloudFormation execution role that was created. The role name should follow the structure cdk-<RANDOM_VALUE>-cfn-exec-role-<ACCOUNT_ID>-<AWS_REGION>. There is no need to take note of the role for your governance account.
Deploy solution’s baseline stack in governed accounts
The baseline stack is a CloudFormation (cfn) stack that extends the capabilities of the AWS CDK CloudFormation execution role so that it is able to perform administrative tasks in AWS Lake Formation.
Follow these steps to deploy the baseline stack in each of your governed accounts:
- First, you need to make a copy of the dz_conn_b_<ACCOUNT_ID>_params.json file in the base/params folder. For each copy of the file, you need to replace the <ACCOUNT_ID> tag in the file name with the account id value that maps to the corresponding governed account.
- Include the AWS CDK CloudFormation execution role name of each governed account as a value of the parameter CdkCloudFormationExecutionRoleName in the governed account’s corresponding file, as shown in the following example:
[
{
"ParameterKey": "CdkCloudFormationExecutionRoleName",
"ParameterValue": "cdk-<RANDOM_VALUE>-cfn-exec-role-<ACCOUNT_ID>-<AWS_REGION>"
}
]
- While standing on the root folder, run the following command, replacing
<PROFILE_NAME>and<ACCOUNT_ID>with the corresponding values of the AWS CLI profile and account id corresponding to the governed account where baseline resources will be deployed:
sh base/deploy.sh -p <PROFILE_NAME> -a <ACCOUNT_ID>
- Wait until completion, and then check the AWS console for a CloudFormation stack named dz-conn-base-env containing the required Lake Formation permissions.
Remember that this process must be done for all governed accounts. Once finished, you can move to the next step. Note that this step is not necessary to be performed in your governance account.
Deploy Guidance’s resources in governance account
First, you need to deploy resources in your central governance account as described in this step.
Setup config file for your central governance account
The json file located in the config/governance/g_config.py path contains the configuration parameters to set up your governance account deployment.
Edit the file and include values for GOVERNANCE_PROPS dictionary with the corresponding values of your governance account. Please follow the file’s documentation for better understanding of each of the keys in the GOVERNANCE_PROPS dictionary:
GOVERNANCE_PROPS = {
'account_id': '',
'region': '',
'a_account_numbers': [],
}
Deploy governance AWS CDK app in your governance account
Run the following command to deploy governance AWS CDK app, replacing <PROFILE_NAME> with the AWS CLI profile name mapping to your governance account:
cdk deploy --app "python app_governance.py" --profile <PROFILE_NAME> --all
The AWS CDK application will retrieve values specified in the configuration file of your governance account, as shown in the step above, and will deploy resources based on them.
Approve IAM resource deployment as required by the AWS CDK deployment process in your terminal.
You will be able to see the progress of the deployment in your terminal and AWS CloudFormation console of your governance account. When finished, check that deployment was successful.
Deploy solution’s resources in all governed accounts
Now, you need to deploy resources in each of your governed accounts. You must repeat the steps described below for each of the governed accounts in your Amazon DataZone setup.
Setup config file for a governed account
First, you need to make a copy of the a_<ACCOUNT_ID>_config.json file in the config/account replacing the <ACCOUNT_ID> tag in the file name with the account id value that maps to the corresponding governed account.
Second, go through each of the dictionaries in the copied python file. Assign a value to each of the keys in all dictionaries based on the file’s documentation and your governed account specific setup.
ACCOUNT_PROPS is a core dictionary that is mapped by other dictionaries in the same file. Remember that even though some of the dictionary values are pre-assigned, this is for illustration purposes only so that you are aware of how you can reference core variables from within your dictionaries.
You need to review and assign each of the values in all dictionaries before you proceed to the next step. All keys in all dictionaries must have non-null values for deployment to be successful (unless specified in the file’s documentation).
Deploy governed AWS CDK app in a governed account
Run the following command to deploy the account (governed) AWS CDK app, replacing <PROFILE_NAME> and <ACCOUNT_ID> with the AWS CLI profile name and account id mapping to your governed account:
cdk deploy --app "python app_account.py" --profile <PROFILE_NAME> -c account=<ACCOUNT_ID> --all
The AWS CDK application will retrieve values specified in the configuration file of your governed account, as shown in the step above, and will deploy resources based on them.
Approve IAM resource deployment as required by the AWS CDK deployment process in your terminal.
You will be able to see the progress of the deployment in your terminal and AWS console for CloudFormation of your governed account. When finished, check that the deployment was successful.
Remember that you need to repeat the last two steps for each of your governed accounts. When finished, you will be done with the deployment of the Guidance.
Deployment validation
In your governance account:
- Open CloudFormation console and verify the status of the templates with the names dz-conn-g-workflows-stack and dz-conn-g-common-stack.
In each of your governed accounts:
- Open CloudFormation console and verify the status of the templates with the names dz-conn-a-common-stack, dz-conn-p-common-stack, dz-conn-p-workflows-stack, dz-conn-p-service-portfolio-stack, dz-conn-c-workflows-stack and dz-conn-c-service-portfolio-stack.
Update the Guidance
If you have previously deployed the Guidance, follow the same procedure to update it. This Guidance is intended to be deployed from within your preferred CI/CD tooling, meaning that updates should be done on your copy of the repository.
It is recommended to always review the potential impact of changes in newer versions, considering that backward compatibility is not ensured. Also, perform deployments in testing environments before proceeding to deploy into production.
Remember that the Guidance is made up of two applications. For updating the application deployed in your governance account, follow the “Deploy governance AWS CDK app in your governance account” section of this guide. For updating the application deployed in any of your governed accounts, follow the “Deploy governed AWS CDK app in a governed account” section of this guide.
Uninstall the Guidance
Follow the steps in this section uninstall the Guidance.
Before uninstalling this solution
Before uninstalling this Guidance, we recommend the following steps:
- Revoke access to all assets hosted by JDBC sources that were granted by this Guidance, because created secrets in Secrets Manager during grant workflow will not be deleted when deleting the solution, nor will created users associated to consumer environments in each of your source databases be removed.
- It is recommended to do this through the Amazon DataZone portal.
- You can verify that all subscription-related assets were removed by checking DynamoDB items, remaining secrets in Secrets Manager, and remaining users in your source database.
- Delete all (both producer and consumer related) provisioned products from this Guidance’s toolkit. This can be done by either using the Amazon DataZone environment roles used to provision them in the first place or using the administrative role(s) specified when provisioning the solution.
- Execute the dz_conn_g_manage_environment_delete state machine in your governance account for each of the environments created after this Guidance’s installation, because environment roles need to be left as they were originally deployed by Amazon DataZone (cleaned); meaning, without the capability or permission extensions that this Guidance added when environments were created.
- If this step is not completed, it can bring unexpected errors later when trying to delete environments using the Amazon DataZone portal.
- To complete the workflow, start a new execution of the dz_conn_g_manage_environment_delete state machine in the Step Functions console of your governance account using the following input and replacing
<AMAZON_DATAZONE_DOMAIN_ID>,<AMAZON_DATAZONE_PROJECT_ID>and<AMAZON_DATAZONE_ENVIRONMENT_ID>with the corresponding values for the environment that you are going to clean:
{
"EventDetails": {
"metadata": {
"domain": "<AMAZON_DATAZONE_DOMAIN_ID>"
},
"data": {
"projectId": "<AMAZON_DATAZONE_PROJECT_ID>",
"environmentId": "<AMAZON_DATAZONE_ENVIRONMENT_ID>",
"delete": true
}
}
}
Uninstall using AWS Management Console
Uninstalling the application in each of the governed accounts
The following steps should be repeated per each governed account in your setup:
- Sign in to the CloudFormation console.
- On the Stacks page, go through the following stacks in the suggested order, and choose Delete for each one of them. It is recommended to wait for deletion of each stack before moving to the next:
- dz-conn-c-service-portfolio-stack
- dz-conn-p-service-portfolio-stack
- dz-conn-c-workflows-stack
- dz-conn-p-workflows-stack
- dz-conn-p-common-stack
- dz-conn-a-common-stack
Uninstalling the application in the governance account
- Sign in to the CloudFormation console.
- On the Stacks page, go through the following stacks in the suggested order, and choose Delete for each one of them. We recommend waiting for deletion of each stack before moving to the next:
- dz-conn-g-workflows-stack
- dz-conn-g-common-stack
Uninstall using the AWS CDK CLI
Uninstalling the application in each of the governed accounts
The following steps should be repeated per each governed account in your setup:
- Execute the following command to destroy account (governed) CDK app, replacing
<PROFILE_NAME>and<ACCOUNT_ID>with the AWS CLI profile name and account id mapping to your governed account:
cdk destroy --app "python app_account.py" --profile <PROFILE_NAME> -c account=<ACCOUNT_ID> --all
Similar to when deploying the Guidance, the AWS CDK application will retrieve values specified in the configuration file of your governed account (filled on deployment) when destroying resources as well.
Even though the AWS CDK CLI will give you live updates on the destroy process, you can always follow along in the CloudFormation console.
Uninstalling the application in the governance account
- Run the following command to deploy governance AWS CDK app, replacing
<PROFILE_NAME>with the AWS CLI profile name mapping to your governance account:
cdk destroy --app "python app_governance.py" --profile <PROFILE_NAME> --all
Similar to when deploying the solution, the AWS CDK application will retrieve values specified in the configuration file of your governance account (filled on deployment) when destroying resources as well.
Even though the CDK CLI will give you live updates on the destroy process, you can also follow along in the CloudFormation console.
Uninstalling Guidance’s prerequisites
Repeat the following step per each governed account in your setup:
- Sign in to the CloudFormation console.
- On the Stacks page, and select the dz-conn-base-env stack.
- Choose Delete.
Developer Guide
Source code
Visit our GitHub repository to download the source files for this Guidance and to share your customizations with others.
Repository structure
When cloning the GitHub repository, you’ll notice that it will contain the following structure:
- An assets folder containing complementary assets like images used in the documentation.
- A base folder containing artifacts associated to the deployment of baseline resources, including:
- A params folder, where multiple parameter json files are expected (one per governed account) to be created. Each file should specify parameter values specific to a governed account’s deployment. Follow the “Deploy the Guidance” section of this guide for further guidance on how to create parameter files when deploying baseline resources.
- A deployment script named deploy.sh that will orchestrate packaging and deployment of resources based on parameters in params folder and AWS CLI profile associated to governed account where baseline resources are going to be deployed. Follow the “Deploy the Guidance” section of this guide for further instruction on how to deploy baseline resources.
- A template.yaml CloudFormation template describing the resource structure that will be deployed as baseline on each governed account.
- A config folder containing configuration files in the form of python files (with dictionary / json variables) to easily configure the deployment of the Guidance in the central governance account and in all governed accounts:
- The account subfolder that stores all files created to specify configuration of the Guidance on top of each of your governed accounts.
- For further details, please read the documentation provided in the reference file named a_<ACCOUNT_ID>_config.py.
- These files will be created as part of the deployment of the Guidance. Refer to the “Deploy the Guidance” section of this guide for further information.
- The governance subfolder will store a single file specifying the configuration of the solution on top of your central governance account.
- For further details, review the documentation provided in the file named g_config.py.
- These files will be created and updated as part of the deployment of the Guidance. Refer to the “Deploy the Guidance” section of this guide for further information.
- The common subfolder contains a single file named global_vars.py that consolidates all static global variables used in the deployment of the Guidance in all accounts (governed and governance).
- Global variables include resource names so that there is resource alignment between accounts. This is useful for policy definition, for example.
- For further details, review the documentation provided in the file named global_vars.py.
- We recommend only updating these values once (if ever) before any deployment to prevent failed deployments or resource misalignment when deploying on different accounts.
- The account subfolder that stores all files created to specify configuration of the Guidance on top of each of your governed accounts.
- A libs folder contains libraries used inside the Guidance, including:
- Lambda layers as zip files that enable Guidance’s workflows to connect to supported source databases and grant or revoke access on Amazon DataZone subscription events.
- A src folder containing the Guidance source code, made by AWS CDK (python) scripts for resource deployment and resource-specific execution code, including Lambda functions’ execution code, IAM policy documents, and Step Functions state machine definitions.
- The account subfolder contains source code for governed account common resources.
- The code subfolder includes execution code for associated Lambda functions and IAM policies.
- The stack subfolder includes application’s AWS CDK stacks for actual deployment of AWS resources.
- The producer subfolder contains source code for governed account producer-related resources.
- The code subfolder includes execution code for associated Lambda functions and Step Functions state machine definitions.
- The constructs folder contains reusable high-level AWS CDK constructs that describe complex architecture patterns that will be deployed as part of the application’s CDK stacks.
- The stack subfolder include the application’s AWS CDK stacks for actual deployment of AWS resources.
- The consumer subfolder contains source code for governed account consumer-related resources.
- The code subfolder includes execution code for associated Lambda functions and Step Functions state machine definitions.
- The constructs folder contains reusable high-level AWS CDK constructs that describe complex architecture patterns that will be deployed as part of the application’s AWS CDK stacks.
- The stack subfolder includes the application’s AWS CDK stacks for actual deployment of AWS resources.
- The governance subfolder contains source code for governance account resources.
- The code subfolder includes execution code for associated Step Functions state machine definitions.
- The constructs folder contains reusable high-level AWS CDK constructs that describe complex architecture patterns that will be deployed as part of the application’s AWS CDK stacks.
- The stack subfolder include the application’s AWS CDK stacks for actual deployment of AWS resources.
- The account subfolder contains source code for governed account common resources.
- Note that there are two CDK application files available:
- The app_account.py file is the master stack to be used to deploy resources in each of the governed accounts. Note how it imports stacks from account, producer, and consumer stacks since all governed accounts require these Guidance’s capabilities. Refer to the “Deploy the Guidance” section of this guide for further information.
- The app_governance.py file is the master stack to deploy resources in the central governance account. Note how it imports the governance stack only since the governance account requires this Guidance’s capability. Refer to the “Deploy the Guidance” section of this guide for further information.
Application stacks
This Guidance includes two applications. The governance application is targeted to the central governance account of your environment (which normally is the one hosting the root domain of your Amazon DataZone setup). The governed application is targeted for each of your governed accounts of your environment (which normally are those where you plan to produce and consume data assets).
Governance application
The governance application includes resources specific for central governance and orchestration that take place in the central governance account of your setup. It is conformed by two AWS CDK stacks.
Governance Common Stack
This stack deploys the following high-level resources:
- Some DynamoDB tables that will store metadata associated to workflow completion outputs.
- Some IAM roles and policies to be used as the:
- Execution role for Lambda functions that are executed in the governance account
- Execution role for primary Step Functions state machines that are executed in the governance account
- Execution role for EventBridge to invoke resources on event occurrence
- Assumed role for governed accounts to be able to read and write into DynamoDB tables.
- Some Lambda functions and layers used to retrieve metadata from Amazon DataZone, including metadata for environments and subscriptions.
Governance Workflows Stack
This stack deploys the following high-level resources:
- A set of workflow constructs with their associated resources including Lambda functions, Step Function state machines, and EventBridge rules. The set includes:
- A workflow to be initiated when a “Environment Created” event is sent by Amazon DataZone. This workflow will extend the environment’s role permissions in an associated governed account. This is to allow environment’s users to leverage new producer and consumer capabilities introduced as part of the Guidance.
- A workflow to be initiated when a “Deleting Environment” event is sent by Amazon DataZone. This workflow will clean environment’s role permissions before deletion in associated governed account.
- A workflow to be initiated (per applicable subscribing environment) when a “Subscription Approved” event is sent by Amazon DataZone. Each workflow will grant access in the data source and deliver a secret that the consumer environment can use to consume the subscribed data asset directly from its hosting data source. The workflow will achieve this task by invoking secondary Step Functions state machines in the subscription’s associated producer and consumer accounts.
- A workflow to be initiated (per applicable subscribing environment) when a “Subscription Revoked” event is sent by Amazon DataZone. This workflow will revoke access in the data source from the consumer environment and delete the associated secret (if not supporting other environment subscriptions). The workflow will achieve this task by invoking secondary Step Functions state machines in the subscription’s associated producer and consumer accounts.
Governed application
The governed application includes resources specific for governed accounts. It is conformed by multiple stacks. Account stacks refer to resources that are common to the account regardless if it is going to act as a producer or a consumer. Producer stacks refer to resources that will be used when the governed account is assuming a producer role. Consumer stacks refer to resources that will be used when the governed account is assuming a consumer role. Governed accounts don’t have a static role. Depending on the collaboration scenario, one single account can work as producer or consumer, which is why all capabilities are deployed per governed account.
Account Common Stack
This stack deploys the following high-level resources:
- An AWS KMS CMK that will be used to encrypt all secrets used by the Guidance on top of the governed account.
- A Service Catalog portfolio where toolkit products for producer and consumer users will be hosted.
- Some IAM roles and policies to be used as:
- Execution role for secondary Step Functions state machines that are executed in the governed account
- Execution role for Lambda functions that are invoked in the governed account
- Execution role for AWS Glue resources (like crawlers) that are invoked in the governed account
- Assumed role for governance account to be able to start the execution of specific AWS Step Functions state machines and AWS Lambda functions.
- Permission set and boundaries to extend role capabilities of account’s new Amazon DataZone projects.
- Two Lambda functions that will be invoked when new Amazon DataZone projects are created so that projects’ associated roles permissions are extended to support the Guidance’s extended capabilities.
Producer Common Stack
This stack deploys the following high-level resources:
- Lambda layers that will be used by workflows to be able to connect to the Guidance’s supported data sources
- Lake Formation tag with associated permissions for principals managing and assigning it. This tag simplifies the Guidance workflows’ interaction with Amazon DataZone managed databases in the AWS Glue Data Catalog.
- A Lambda function that will be invoked when new Amazon DataZone projects are created so that projects’ associated databases are tagged with the Lake Formation tag that simplifies interaction with solution.
Producer Service Portfolio Stack
This stack deploys the following high-level resources:
- An IAM role and policy for deployment of producer-targeted products in the account’s common Service Catalog portfolio (toolkit).
- A Service Catalog product for deploying an AWS Glue connection for a JDBC data source. The product will be associated to the account’s common Service Catalog Portfolio (toolkit). Deployed resources will be tagged with the project id of the Amazon DataZone project deploying the product so that it can be only used by the project’s associated principals.
- A Service Catalog product for deploying an AWS Glue connection for a JDBC data source with an associated crawler to infer schema of a sub-path inside the data source and mapping it to a target database in the AWS Glue Data Catalog. The product will be associated to the account’s common Service Catalog Portfolio (toolkit). Deployed resources will be tagged with the project id of the Amazon DataZone project deploying the product so that it can be only used by the project’s associated principals.
Producer Workflow Stack
This stack deploys the following high-level resources:
- A set of workflow constructs with their associated resources, including Lambda functions and Step Function state machines. The set includes:
- A workflow to be initiated by the primary Step Functions state machine in the governance account after a “Subscription Approved” event is sent by Amazon DataZone. This workflow will grant access in source data source through subscriber-isolated credentials and share them through a secret in Secrets Manager. Th workflow will update output metadata in DynamoDB tables in the governance account for tracking purposes.
- A workflow to be initiated by the primary Step Functions state machine in the governance account after a “Subscription Revoked” event is sent by Amazon DataZone. This workflow will revoke access in source data source to subscriber-isolated credentials and delete them (if not needed anymore) with the associated secret in Secrets Manager. Workflow will update output metadata in DynamoDB tables in the governance account for tracking purposes.
Consumer Service Portfolio Stack
This stack deploys the following high-level resources:
- An IAM role and policy for deployment of consumer-targeted products in the account’s common Service Catalog portfolio (toolkit).
- A Service Catalog product for deploying an Athena connection for a MySQL data source. The product will be associated to the account’s common Service Catalog Portfolio (toolkit). Deployed resources will be tagged with the project id of the Amazon DataZone project deploying the product so that it can be only used by project’s associated principals.
- A Service Catalog product for deploying an Athena connection for a PostgreSQL data source. The product will be associated to the account’s common Service Catalog Portfolio (toolkit). Deployed resources will be tagged with the project id of the Amazon DataZone project deploying the product so that it can be only used by project’s associated principals.
- A Service Catalog product for deploying an Athena connection for a SQL Server data source. The product will be associated to the account’s common Service Catalog Portfolio (toolkit). Deployed resources will be tagged with the project id of the Amazon DataZone project deploying the product so that it can be only used by the project’s associated principals.
- A Service Catalog product for deploying an Athena connection for an Oracle data source. The product will be associated to the account’s common Service Catalog Portfolio (toolkit). Deployed resources will be tagged with the project id of the Amazon DataZone project deploying the product so that it can be only used by the project’s associated principals.
Consumer Workflow Stack
This stack deploys the following high-level resources:
- A set of workflow constructs with their associated resources, including Lambda functions and Step Functions state machines. The set includes:
- A workflow to be initiated by the primary Step Functions state machine in the governance account after a “Subscription Approved” event is sent by Amazon DataZone. This workflow will copy subscriber-isolated credentials, shared by the producer, into a local Secrets Manager secret. The workflow will update output metadata in DynamoDB tables in the governance account for tracking purposes.
- A workflow to be initiated by the primary Step Functions state machine in the governance account after a “Subscription Revoked” event is sent by Amazon DataZone. This workflow will delete the local Secrets Manager secret with the copy of the shared credentials (if not needed anymore). The workflow will update output metadata in DynamoDB tables in the governance account for tracking purposes.
Application workflow’s metadata and inner workings
This Guidance stores metadata on each execution so that management teams are able to track and troubleshoot when needed. The two main metadata elements of the solution are DynamoDB tables (storing execution output metadata), Step Functions execution messages (storing step execution details), and CloudWatch logs (storing execution logs).
Execution outputs metadata
The Guidance deploys three DynamoDB tables in the governance account. Items are put and deleted by secondary workflows in producer and consumer accounts every time there is a subscription-related event in Amazon DataZone. This three tables are:
Producer source subscriptions table
The purpose of this table is for the secondary workflow in the producer account to store which data assets of a data source has a granted subscription to which data consumers through which secret (credentials) in Secrets Manager.
Each item in this table is associated to a data source connection, not a single data asset, meaning that all environment subscriptions to data assets hosted in the same data source will use the same credentials and Secrets Manager secret.
All items in this table follows the schema:
{
"glue_connection_arn": "arn:aws:glue:<REGION>:<PRODUCER_ACCOUNT_ID>:connection/<GLUE_CONNECTION_NAME>",
"datazone_consumer_environment_id": "<AMAZON_DATAZONE_CONSUMER_ENVIRONMENT_ID>",
"datazone_consumer_project_id": "<AMAZON_DATAZONE_CONSUMER_PROJECT_ID>",
"datazone_domain_id": "<AMAZON_DATAZONE_DOMAIN_ID>",
"data_assets": [
...
],
"last_updated": "YYYY-mm-ddTHH:MM:SS",
"owner_account": "<PRODUCER_ACCOUNT_ID>",
"owner_region": "<PRODUCER_REGION>",
"secret_arn": "arn:aws:secretsmanager:<REGION>:<PRODUCER_ACCOUNT_ID>:secret:<SECRET_ARN_SUFFIX>",
"secret_name": "<SECRET_NAME>"
}
- The glue_connection_arn attribute stores the Acquirer Reference Numbers (ARN) of the AWS Glue connection associated to the source database. It is expected that every data asset in the AWS catalog has an associated AWS Glue crawler and connection in its metadata.
- The datazone_consumer_environment_id attribute stores the environment id of the consumer Amazon DataZone environment subscribing to a set of data assets under the same AWS Glue connection (meaning same data source).
- The datazone_consumer_project_id attribute stores the project id of the consumer Amazon DataZone project owning the Amazon DataZone environment that is subscribing to the data assets.
- The datazone_domain_id attribute stores the domain id of the Amazon DataZone domain.
- The data_assets attribute stores a list of paths from within the data source for each data asset to which the Amazon DataZone consumer project has granted access.
- The last_updated attribute stores the date and time in which the record was last updated.
- The owner_account attribute stores the account id of the data asset’s owning account (producer).
- The owner_region attribute stores the Region hosting the data asset’s.
- The secret_arn attribute stores the ARN of the Secrets Manager secret in the producer account with the credentials that grants access to the Amazon DataZone subscribing consumer environment.
- The secret_name attribute stores the name of the Secrets Manager secret in the producer account with the credentials that grants access to the Amazon DataZone subscribing consumer environment.
The partition key for this table is glue_connection_arn and the sort key is datazone_consumer_environment_id.
This table is only updated by the secondary Step Function state machine that is executed inside the producer account on each “Subscription” related event through cross-account access.
Consumer secrets mapping table
The purpose of this table is for the secondary workflow in the consumer account to store which secret in Secrets Manager, local to the consumer account, maps to (or is a copy of) which secret in the producer account.
Note that there is an item per secret pair (producer and consumer’s copy).
All items in this table follow the schema:
{
"shared_secret_arn": "arn:aws:secretsmanager:<REGION>:<PRODUCER_ACCOUNT_ID>:secret:<PRODUCER_SECRET_ARN_SUFFIX>",
"datazone_consumer_environment_id": "<AMAZON_DATAZONE_CONSUMER_ENVIRONMENT_ID>",
"datazone_consumer_project_id": "<AMAZON_DATAZONE_CONSUMER_PROJECT_ID>",
"datazone_domain": "<AMAZON_DATAZONE_DOMAIN_ID>",
"last_updated": "YYYY-mm-ddTHH:MM:SS",
"owner_account": "<CONSUMER_ACCOUNT_ID>",
"owner_region": "<CONSUMER_REGION>",
"secret_arn": "arn:aws:secretsmanager:<REGION>:<CONSUMER_ACCOUNT_ID>:secret:<CONSUMER_SECRET_ARN_SUFFIX>",
"secret_name": "<CONSUMER_SECRET_NAME>"
}
- The shared_secret_arn attribute stores the ARN of the Secrets Manager shared secret in the producer account with the credentials that grants access to the Amazon DataZone subscribing consumer environment.
- The datazone_consumer_environment_id attribute stores the environment id of the consumer Amazon DataZone environment.
- The datazone_consumer_project_id attribute stores the project id of the consumer Amazon DataZone project owning the consumer Amazon DataZone environment.
- The datazone_domain attribute stores the domain id of the Amazon DataZone domain.
- The last_updated attribute stores the date and time in which the record was last updated.
- The owner_account attribute stores the account id of the consumer environment.
- The owner_region attribute stores the Region of the consumer environment.
- The secret_arn attribute stores the ARN of the Secrets Manager secret in the consumer account that is a copy of the associated shared secret with credentials to the data source in the producer account.
- The secret_name attribute stores the name of the Secrets Manager secret in the consumer account that is a copy of the associated shared secret with credentials to the data source in the producer account.
The partition key for this table is shared_secret_arn.
This table is only updated by the secondary Step Functions state machine that is executed inside the consumer account on each “Subscription” related event through cross-account access.
Consumer asset subscription table
The purpose of this table is for secondary workflows in the consumer account to store which Amazon DataZone environment is subscribed to which data asset and through which secret in Secrets Manager it has access to that data asset.
Note that there is an item per data asset subscription.
All items in this table follows the schema:
{
"datazone_consumer_environment_id": "<AMAZON_DATAZONE_CONSUMER_ENVIRONMENT_ID>",
"datazone_asset_id": "<AMAZON_DATAZONE_DATA_ASSET_ID>",
"datazone_asset_revision": "<AMAZON_DATAZONE_DATA_ASSET_REVISION>",
"datazone_asset_type": "<AMAZON_DATAZONE_DATA_ASSET_TYPE>",
"datazone_consumer_project_id": "<AMAZON_DATAZONE_CONSUMER_PROJECT_ID>",
"datazone_domain_id": "<AMAZON_DATAZONE_DOMAIN_ID>",
"datazone_listing_id": "<AMAZON_DATAZONE_LISTING_ID>",
"datazone_listing_name": "<AMAZON_DATAZONE_LISTING_NAME>",
"datazone_listing_revision": "<AMAZON_DATAZONE_LISTING_REVISION>",
"last_updated": "YYYY-mm-ddTHH:MM:SS",
"owner_account": "<CONSUMER_ACCOUNT_ID>",
"owner_region": "<CONSUMER_REGION>",
"secret_arn": "arn:aws:secretsmanager:<REGION>:<CONSUMER_ACCOUNT_ID>:secret:<CONSUMER_SECRET_ARN_SUFFIX>",
"secret_name": "<CONSUMER_SECRET_NAME>"
}
- The datazone_consumer_environment_id attribute stores the environment id of the consumer Amazon DataZone environment subscribing to the data asset.
- The datazone_asset_id attribute stores the id of the Amazon DataZone data asset to which the consumer Amazon DataZone project is subscribed.
- The datazone_asset_revision attribute stores the revision (version) of the Amazon DataZone data asset that the consumer Amazon DataZone project is subscribed to.
- The datazone_asset_type attribute stores the type of Amazon DataZone data asset to which the consumer Amazon DataZone project is subscribed.
- The datazone_consumer_project_id attribute stores the project id of the consumer Amazon DataZone project owning the consumer Amazon DataZone environment.
- The datazone_domain_id attribute stores the domain id of the Amazon DataZone domain.
- The datazone_listing_id attribute stores the id of the Amazon DataZone listing associated to the Amazon DataZone data asset.
- The datazone_listing_name attribute stores the name of the Amazon DataZone listing associated to the Amazon DataZone data asset.
- The datazone_listing_revision attribute stores the revision (version) of the Amazon DataZone listing associated to the Amazon DataZone data asset.
- The last_updated attribute stores the date and time in which the record was last updated.
- The owner_account attribute stores the account id of the consumer environment.
- The owner_region attribute stores the Region of the consumer environment.
- The secret_arn attribute stores the ARN of Secrets Manager secret in the consumer account that can be used by the consumer Amazon DataZone environment to access the subscribed data asset.
- The secret_name attribute stores the name of the Secrets Manager secret in the consumer account that can be used by the consumer Amazon DataZone environment to access the subscribed data asset.
The partition key for this table is datazone_consumer_environment_id and the sort key is datazone_asset_id.
This table is only updated by the secondary Step Functions state machine that is executed inside the consumer account on each “Subscription” related event through cross-account access.
Execution step details metadata
This Guidance’s automation is supported by Step Functions. Each state machine represents a workflow that is initiated whenever an event in EventBridge is sent by Amazon DataZone. Each step in every state machine will get inputs and return outputs from a json message that consolidates all details from a single execution.
All workflows are initiated in the governance account, and some of them will invoke other resources in the governed accounts including Lambda functions and other Step Functions state machines.
Manage environment active workflow
This workflow will be initiated whenever Amazon DataZone service sends an “Environment Active” event to EventBridge in the governance account. The “Environment Active” event is sent after the Amazon DataZone environment’s resources are deployed in the corresponding governed account.
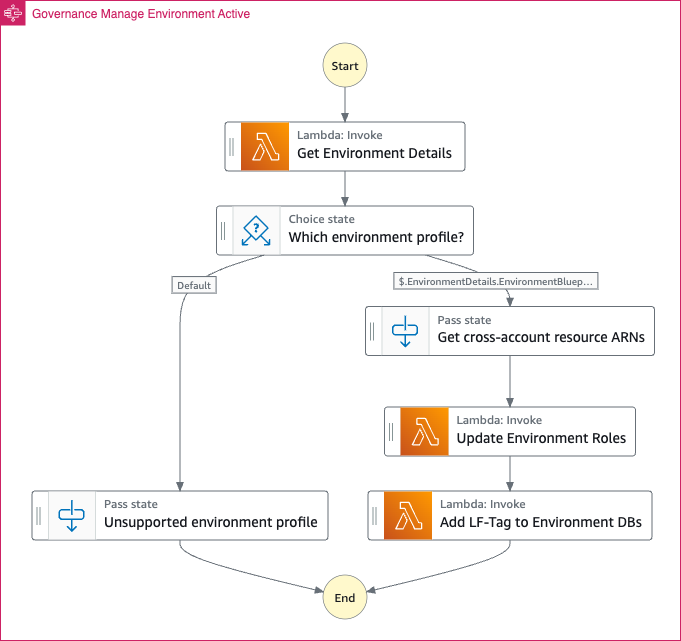
Figure 6. Manage environment active workflow
The purpose of this workflow is to:
- Extend Amazon DataZone environment’s roles so that they are able to leverage new capabilities introduced by the Guidance’s toolkit.
- Using Lake Formation, tag all Amazon DataZone environment’s associated databases in the AWS Glue Data Catalog.
Remember that Lambda functions will be executed inside the governed account where Amazon DataZone environment’s resources were deployed. This is done through cross-account access.
The message that is assembled on each execution will follow the JSON structure:
{
"EventDetails": {
"version": "...",
"internal": null,
"metadata": {
"id": "...",
"version": "...",
"typeName": "EnvironmentDeploymentEntityType",
"domain": "<DOMAIN_ID>",
"user": "SYSTEM",
"awsAccountId": "<GOVERNANCE_ACCOUNT_ID>",
"owningProjectId": "<PROJECT_ID>"
},
"data": {
"projectId": "<PROJECT_ID>",
"environmentId": "<ENVIRONMENT_ID>",
"environmentDeploymentId": "<ENVIRONMENT_DEPLOYMENT_ID>"
}
},
"EnvironmentDetails": {
"EnvironmentId": "<ENVIRONMENT_ID>",
"ProjectId": "<PROJECT_ID>",
"DomainId": "<DOMAIN_ID>",
"AccountId": "<ENVIRONMENT_ACCOUNT_ID>",
"Region": "<ENVIRONMENT_REGION>",
"EnvironmentStatus": "ACTIVE",
"EnvironmentName": "<ENVIRONMENT_NAME>",
"EnvironmentBlueprintId": "<ENVIRONMENT_BLUEPRINT_ID>",
"EnvironmentBlueprintName": "<ENVIRONMENT_BLUEPRINT_NAME>",
"EnvironmentResources": {
...
}
},
"CrossAccountResources": {
"AddLFTagEnvironmentDBsLambdaArn": "arn:aws:lambda:<ENVIRONMENT_REGION>:<ENVIRONMENT_ACCOUNT_ID>:function:<LF_TAG_ENVIRONMENT_DBS_LAMBDA_NAME>",
"UpdateEnvironmentRolesLambdaArn": "arn:aws:lambda:<ENVIRONMENT_REGION>:<ENVIRONMENT_ACCOUNT_ID>:function:<UPDATE_ENVIRONMENT_ROLES_LAMBDA_NAME>",
"AccountAssumeRoleArn": "arn:aws:iam::<ENVIRONMENT_ACCOUNT_ID>:role/<CROSS_ACCOUNT_ASSUME_ROLE_NAME>"
},
"AccountUpdateEnvironmentRolesDetails": {
"EnvironmentRoleArn": "arn:aws:iam::<ENVIRONMENT_ACCOUNT_ID>:role/datazone_usr_<ENVIRONMENT_ID>"
},
"AccountAddLFTagEnvironmentDBsDetails": {
"LFTagKey": "<LAKE_FORMATION_TAG_KEY>",
"EnvironmentDBNames": [
...
],
"LFTagValue": "<LAKE_FORMATION_TAG_VALUE>"
}
}
- The EventDetails key includes keys from the original message sent by Amazon DataZone to EventBridge on an “Environment Active” event. As it can be appreciated in the template above, it contains the id of the Amazon DataZone environment that was created and its owning project.
- The EnvironmentDetails key includes all of the relevant details of the newly created Amazon DataZone environment, including its name, status, associated blueprint and resources created on deployment.
- The CrossAccountResources key includes ARN values of the Lambda functions that need to be invoked in the governed account where Amazon DataZone environment’s resources were deployed. It also includes a value for the ARN of the role in the governed account that can be assumed for cross-account access so that Lambda functions can be invoked from the governance account.
- The AccountUpdateEnvironmentRolesDetails key includes the ARN value of the IAM role associated to the Amazon DataZone environment in the governed account that was updated or extended to be able to use new capabilities introduced by this Guidance’s toolkit.
- The AccountAddLFTagEnvironmentDBsDetails key includes the Lake Formation tag key and value that was applied to the Amazon DataZone environment’s databases in the AWS Glue Data Catalog (also listed).
Manage environment deleting workflow
This workflow will be initiated whenever Amazon DataZone service sends a “Deleting Environment” event to EventBridge in the governance account. The “Deleting Environment” event is sent as soon as an environment deletion request is submitted in the Amazon DataZone portal. Note that this event is sent prior to the actual deletion of the Amazon DataZone environment’s resources.
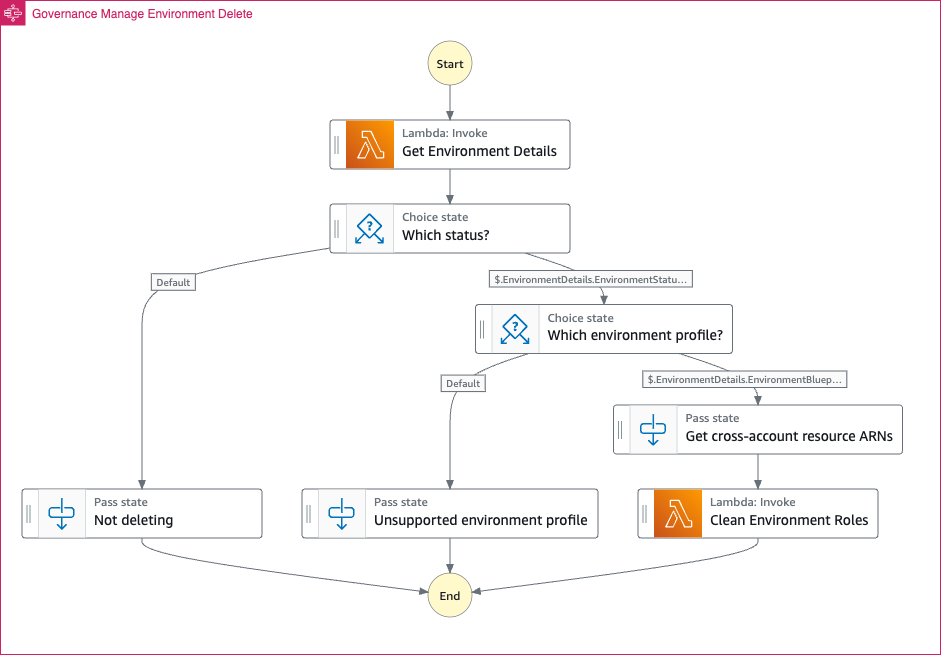
Figure 7. Manage environment deleting workflow
The purpose of this workflow is to clean Amazon DataZone environment’s role so that it is left with original permission structure before actual deletion is performed.
Remember that a Lambda function will be invoked inside the governed account where Amazon DataZone environment’s resources were deployed. This is done through cross-account access.
The message that is assembled on each execution will follow the JSON structure:
{
"EventDetails": {
"metadata": {
"domain": "<DOMAIN_ID>"
},
"data": {
"projectId": "<PROJECT_ID>",
"environmentId": "<ENVIRONMENT_ID>",
"delete": true
}
},
"EnvironmentDetails": {
"EnvironmentId": "<ENVIRONMENT_ID>",
"ProjectId": "<PROJECT_ID>",
"DomainId": "<DOMAIN_ID>",
"AccountId": "<ENVIRONMENT_ACCOUNT_ID>",
"Region": "<ENVIRONMENT_REGION>",
"EnvironmentStatus": "ACTIVE",
"EnvironmentName": "<ENVIRONMENT_NAME>",
"EnvironmentBlueprintId": "<ENVIRONMENT_BLUEPRINT_ID>",
"EnvironmentBlueprintName": "<ENVIRONMENT_BLUEPRINT_NAME>",
"EnvironmentResources": {
...
}
},
"CrossAccountResources": {
"CleanEnvironmentRolesLambdaArn": "arn:aws:lambda:<ENVIRONMENT_REGION>:<ENVIRONMENT_ACCOUNT_ID>:function:<CLEAN_ENVIRONMENT_ROLES_LAMBDA_NAME>",
"AccountAssumeRoleArn": "arn:aws:iam::<ENVIRONMENT_ACCOUNT_ID>:role/<CROSS_ACCOUNT_ASSUME_ROLE_NAME>"
},
"AccountCleanEnvironmentRolesDetails": {
"EnvironmentRoleArn": "arn:aws:iam::<ENVIRONMENT_ACCOUNT_ID>:role/datazone_usr_<ENVIRONMENT_ID>"
}
}
- The EventDetails key includes keys from the original message sent by Amazon DataZone to EventBridge on the “Deleting Environment” event. As it can be appreciated in the template above, it contains the id, name, and account of the Amazon DataZone environment that is going to be deleted.
- The EnvironmentDetails key includes all of the relevant details of the existing Amazon DataZone environment, including its name, status, associated blueprint, and resources created on deployment.
- The CrossAccountResources key includes ARN values of the Lambda function that needs to be invoked in the governed account where Amazon DataZone environment’s resources were deployed. It also includes a value for the ARN of the role in the governed account that can be assumed for cross-account access so that the Lambda function can be invoked from the governance account.
- The AccountCleanEnvironmentRolesDetails key includes the ARN value of the IAM role associated to the Amazon DataZone environment in the governed account that was cleaned before deletion.
Manage subscription grant workflow
This workflow will be initiated whenever Amazon DataZone service sends a “Subscription Grant” event to EventBridge in the governance account. The “Subscription Grant” event is sent as soon as a subscription request is accepted in the Amazon DataZone portal.
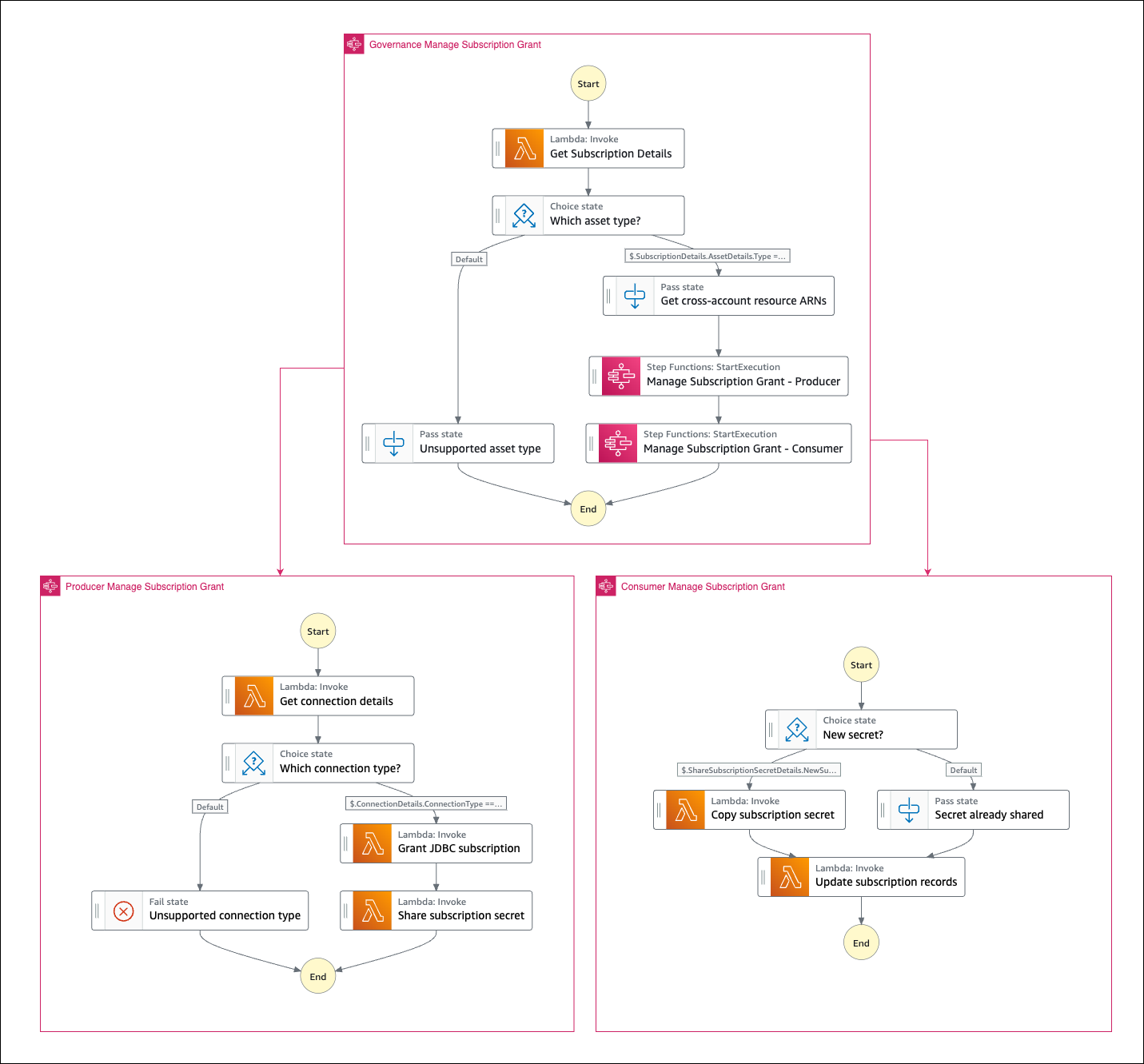
Figure 8. Manage subscription grant workflow
The purpose of this workflow is explained in the following steps:
- In the producer governed account, identify and connect to the data source hosting the subscription’s data asset. Additionally, create credentials (if nonexistent) to the subscribing Amazon DataZone environment and grant read access to the subscribing data asset. Finally, credentials will be stored as a secret in Secrets Manager and shared to the environment’s associated account through a resource policy that allows read access to the secret.
- In the consumer governed account, copy the secret that was shared by the producer governed account into a new secret in Secrets Manager, local to the consumer governed account.
- Output metadata of both producer and consumer steps will be persisted in DynamoDB in the governance account.
Remember that secondary Step Functions state machines and conforming Lambda functions will be executed inside the governed accounts where Amazon DataZone environment’s resources, associated to the producer and consumer side of the subscription, were deployed. This is done through cross-account access.
The message that is assembled on each execution will follow the JSON structure:
{
"EventDetails": {
"version": "...",
"internal": null,
"metadata": {
"id": "...",
"version": "...",
"typeName": "SubscriptionGrantEntityType",
"domain": "<DOMAIN_ID>",
"user": "SYSTEM",
"awsAccountId": "<GOVERNANCE_ACCOUNT_ID>"
},
"data": {
"asset": {
"id": "<ASSET_ID>",
"listingId": "<LISTING_ID>",
"listingVersion": "<LISTING_VERSION>",
"typeName": "<ASSET_TYPE>",
"version": "<ASSET_VERSION>"
},
"environmentProvider": "Amazon DataZone",
"projectId": "<CONSUMER_PROJECT_ID>",
"status": "GRANTED",
"subscriptionTarget": {
"environmentId": "<CONSUMER_ENVIRONMENT_ID>",
"id": "<SUBSCRIPTION_TARGET_ID>",
"provider": "Amazon DataZone",
"typeName": "<SUBSCRIPTION_TARGET_TYPE>"
}
}
},
"SubscriptionDetails": {
"DomainId": "<DOMAIN_ID>",
"ProducerProjectDetails": {
"ProjectId": "<PRODUCER_PROJECT_ID>",
"ProjectName": "<PRODUCER_PROJECT_NAME>"
},
"ConsumerProjectDetails": {
"ProjectId": "<CONSUMER_PROJECT_ID>",
"ProjectName": "<CONSUMER_PROJECT_NAME>",
"AccountId": "<CONSUMER_ACCOUNT_ID>",
"Region": "<CONSUMER_REGION>",
"EnvironmentId": "<CONSUMER_ENVIRONMENT_ID>",
"EnvironmentName": "<CONSUMER_ENVIRONMENT_NAME>",
"EnvironmentProfileId": "<CONSUMER_ENVIRONMENT_PROFILE_ID>",
"EnvironmentProfileName": "<CONSUMER_ENVIRONMENT_PROFILE_NAME>"
},
"AssetDetails": {
"Type": "<ASSET_TYPE>",
"Id": "<ASSET_ID>",
"Revision": "<ASSET_REVISION>",
"GlueTableDetails": {
...
}
},
"ListingDetails": {
"Id": "<LISTING_ID>",
"Name": "<LISTING_NAME>",
"Revision": "<LISTING_REVISION>"
}
},
"CrossAccountResources": {
"ProducerStateMachineArn": "arn:aws:states:<ASSET_REGION>:<ASSET_ACCOUNT_ID>:stateMachine:<PRODUCER_MANAGE_SUBSCRIPTION_GRANT_STATE_MACHINE_NAME>",
"ProducerAssumeRoleArn": "arn:aws:iam::<ASSET_ACCOUNT_ID>:role/<CROSS_ACCOUNT_ASSUME_ROLE_NAME>",
"ConsumerStateMachineArn": "arn:aws:states:<CONSUMER_REGION>:<CONSUMER_ACCOUNT_ID>:<CONSUMER_MANAGE_SUBSCRIPTION_GRANT_STATE_MACHINE_NAME>",
"ConsumerAssumeRoleArn": "arn:aws:iam::<CONSUMER_ACCOUNT_ID>:role/<CROSS_ACCOUNT_ASSUME_ROLE_NAME>"
},
"ProducerGrantDetails": {
"SecretArn": "arn:aws:secretsmanager:<ASSET_REGION>:<ASSET_ACCOUNT_ID>:secret:<PRODUCER_SECRET_ARN_SUFFIX>",
"SecretName": "<PRODUCER_SECRET_NAME>",
"SubscriptionConsumerRoles": [
"arn:aws:iam::<CONSUMER_ACCOUNT_ID>:role/<CONSUMER_WORKFLOWS_LAMBDA_ROLE_NAME>"
],
"NewSubscriptionSecret": "<true / false>"
},
"ConsumerGrantDetails": {
"SecretArn": "arn:aws:secretsmanager:<CONSUMER_REGION>:<CONSUMER_ACCOUNT_ID>:secret:<CONSUMER_SECRET_ARN_SUFFIX>",
"SecretName": "<CONSUMER_SECRET_NAME>",
"DataZoneAssetId": "<ASSET_ID>",
"DataZoneConsumerEnvironmentId": "<CONSUMER_ENVIRONMENT_ID>"
}
}
Note that the presented structure is for the primary Step Functions state machine, executed in the governance account, since it consolidates the most important details of the entire execution. We encourage you to check message structures of secondary Step Functions state machines executed in the producer and consumer governed accounts.
- The EventDetails key includes keys from original message sent by Amazon DataZone to EventBridge on the “Subscription Grant” event. As it can be appreciated in the template above, it contains id and some details of the data asset as well as the consumer environment (subscription target).
- The SubscriptionDetails key includes all of the relevant details of the approved subscription, including producer and consumer details in addition to data asset and listing details. Note that if the data asset is an AWS Glue table, additional details will be added associated to the AWS Glue table metadata.
- The CrossAccountResources key includes ARN values of the Step Functions state machines that need to be invoked in the governed accounts (producer and consumer) where resources of Amazon DataZone environments, involved in subscription, were deployed. It also includes a value for the ARN of the roles in the governed accounts that can be assumed for cross-account access so that Step Functions state machines can be invoked from the governance account.
- The ProducerGrantDetails key includes main keys from the message assembled by the Step Functions state machine executed in the producer account. It includes ARN and name of the secret in Secrets Manager that contains credentials with the grants supporting the subscription. It also includes the ARN of the IAM role that has cross-account access enabled to retrieve the secret’s value (note that it is not the Amazon DataZone environment’s role, but the role assumed by the Lambda functions of the workflow in the consumer account). Finally, it includes a key to confirm if the secret was newly created in a current execution or not. If the secret was not newly created, it is because the workflow is reusing credentials from a previous execution that granted access to data assets in the same data source as current execution.
- The ConsumerGrantDetails key includes main keys from the message assembled by the Step Functions state machine executed in the consumer account. It includes the ARN and name of the copied secret in Secrets Manager that contains a copy of the credentials supporting the subscription. It also includes the name of the subscription data asset and the Amazon DataZone environment id of the environment subscribing to the data asset.
Manage subscription revoke workflow
This workflow will be triggered whenever Amazon DataZone sends a “Subscription Revoke” event to EventBridge in the governance account. The “Subscription Revoke” event is sent as soon as a subscription request is revoked in the Amazon DataZone portal.
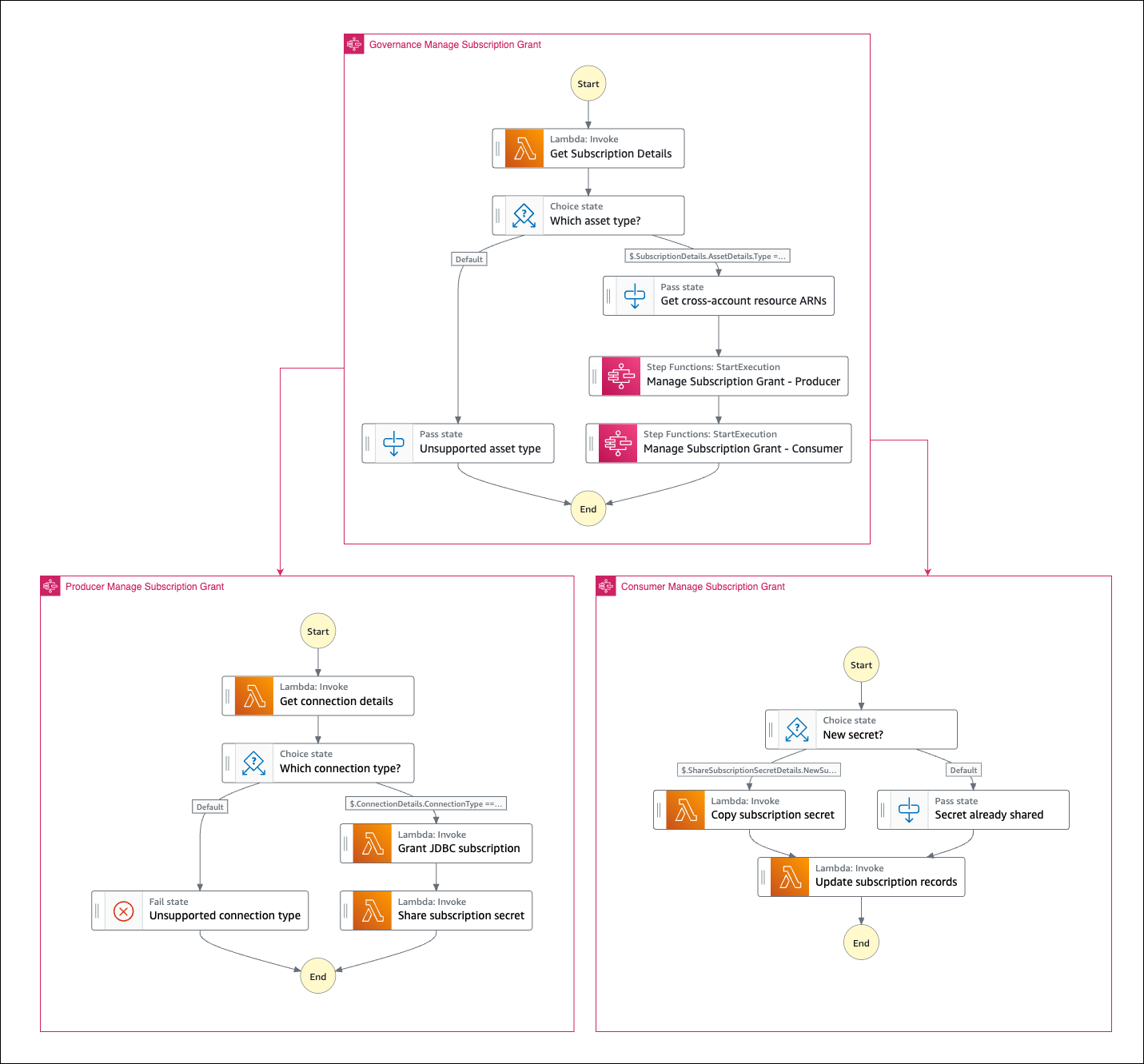
Figure 9: Manage subscription revoke workflow
The purpose of this workflow is explained in the following steps:
- In the producer governed account, identify and connect to the data source hosting the subscription’s data asset. Additionally, revoke read access to the subscribing data asset from the Amazon DataZone environment’s associated credentials. If no additional data asset grants are supported with current credentials, they will be deleted as well as the associated secret in Secrets Manager.
- In the consumer governed account, delete the copied secret in Secrets Manager, local to the consumer governed account, only if the producer secret was deleted first.
- Output metadata of both, producer and consumer steps will be updated in DynamoDB in the governance account.
The message that is assembled on each execution will follow the JSON structure:
{
"EventDetails": {
"version": "...",
"internal": null,
"metadata": {
"id": "...",
"version": "...",
"typeName": "SubscriptionGrantEntityType",
"domain": "<DOMAIN_ID>",
"user": "SYSTEM",
"awsAccountId": "<GOVERNANCE_ACCOUNT_ID>"
},
"data": {
"asset": {
"id": "<ASSET_ID>",
"listingId": "<LISTING_ID>",
"listingVersion": "<LISTING_VERSION>",
"typeName": "<ASSET_TYPE>",
"version": "<ASSET_VERSION>"
},
"environmentProvider": "Amazon DataZone",
"projectId": "<CONSUMER_PROJECT_ID>",
"status": "REVOKED",
"subscriptionTarget": {
"environmentId": "<CONSUMER_ENVIRONMENT_ID>",
"id": "<SUBSCRIPTION_TARGET_ID>",
"provider": "Amazon DataZone",
"typeName": "<SUBSCRIPTION_TARGET_TYPE>"
}
}
},
"SubscriptionDetails": {
"DomainId": "<DOMAIN_ID>",
"ProducerProjectDetails": {
"ProjectId": "<PRODUCER_PROJECT_ID>",
"ProjectName": "<PRODUCER_PROJECT_NAME>"
},
"ConsumerProjectDetails": {
"ProjectId": "<CONSUMER_PROJECT_ID>",
"ProjectName": "<CONSUMER_PROJECT_NAME>",
"AccountId": "<CONSUMER_ACCOUNT_ID>",
"Region": "<CONSUMER_REGION>",
"EnvironmentId": "<CONSUMER_ENVIRONMENT_ID>",
"EnvironmentName": "<CONSUMER_ENVIRONMENT_NAME>",
"EnvironmentProfileId": "<CONSUMER_ENVIRONMENT_PROFILE_ID>",
"EnvironmentProfileName": "<CONSUMER_ENVIRONMENT_PROFILE_NAME>"
},
"AssetDetails": {
"Type": "<ASSET_TYPE>",
"Id": "<ASSET_ID>",
"Revision": "<ASSET_REVISION>",
"GlueTableDetails": {
...
}
},
"ListingDetails": {
"Id": "<LISTING_ID>",
"Name": "<LISTING_NAME>",
"Revision": "<LISTING_REVISION>"
}
},
"CrossAccountResources": {
"ProducerStateMachineArn": "arn:aws:states:<ASSET_REGION>:<ASSET_ACCOUNT_ID>:stateMachine:<PRODUCER_MANAGE_SUBSCRIPTION_REVOKE_STATE_MACHINE_NAME>",
"ProducerAssumeRoleArn": "arn:aws:iam::<ASSET_ACCOUNT_ID>:role/<CROSS_ACCOUNT_ASSUME_ROLE_NAME>",
"ConsumerStateMachineArn": "arn:aws:states:<CONSUMER_REGION>:<CONSUMER_ACCOUNT_ID>:<CONSUMER_MANAGE_SUBSCRIPTION_REVOKE_STATE_MACHINE_NAME>",
"ConsumerAssumeRoleArn": "arn:aws:iam::<CONSUMER_ACCOUNT_ID>:role/<CROSS_ACCOUNT_ASSUME_ROLE_NAME>"
},
"ProducerRevokeDetails": {
"SecretArn": "arn:aws:secretsmanager:<ASSET_REGION>:<ASSET_ACCOUNT_ID>:secret:<PRODUCER_SECRET_ARN_SUFFIX>",
"SecretName": "<PRODUCER_SECRET_NAME>",
"SecretRecoveryWindowInDays": "<PRODUCER_SECRET_RECOVERY_WINDOW>",
"SecretDeleted": "<true / false>",
"SecretDeletionDate": "YYYY-mm-ddTHH:MM:SS"
},
"ConsumerRevokeDetails": {
"SecretArn": "arn:aws:secretsmanager:<CONSUMER_REGION>:<CONSUMER_ACCOUNT_ID>:secret:<CONSUMER_SECRET_ARN_SUFFIX>",
"SecretName": "<CONSUMER_SECRET_NAME>",
"SecretRecoveryWindowInDays": "<CONSUMER_SECRET_RECOVERY_WINDOW>",
"SecretDeleted": "<true / false>",
"SecretDeletionDate": "YYYY-mm-ddTHH:MM:SS",
"DataZoneAssetID": "<ASSET_ID>",
"DataZoneConsumerEnvironmentId": "<CONSUMER_ENVIRONMENT_ID>"
}
}
Note that the presented structure is for the primary Step Functions state machine, executed in the governance account, since it consolidates the most important details of the entire execution. We encourage you to check message structures of secondary Step Functions state machines executed in the producer and consumer governed accounts.
- The EventDetails key includes keys from original message sent by Amazon DataZone to EventBridge on “Subscription Revoke” event. As it can be appreciated in the template above, it contains id and some details of the data asset as well as the consumer environment (subscription target).
- The SubscriptionDetails key includes all of the relevant details of the revoked subscription, including producer and consumer details in addition to data asset and listing details. Note that if the data asset is an AWS Glue table, additional details will be added associated to the AWS Glue table metadata.
- The CrossAccountResources key includes ARN values of the Step Functions state machines that need to be invoked in the governed accounts (producer and consumer) where resources of Amazon DataZone environments, involved in subscription, were deployed. It also includes a value for the ARN of the roles in the governed accounts that can be assumed for cross-account access so that Step Functions state machines can be invoked from the governance account.
- The ProducerRevokeDetails key includes main keys from the message assembled by the Step Functions state machine executed in the producer account. It includes the ARN and name of the producer secret in Secrets Manager that supported the subscription before revoked. If the secret was deleted, it will include a key confirming it in addition to the deletion date and time, detailing its recovery time window.
- The ConsumerRevokeDetails key includes main keys from the message assembled by the Step Functions state machine executed in the consumer account. It includes the id of the subscription data asset and the Amazon DataZone environment id of the project whose subscription to the data asset was revoked. It also includes the ARN and name of the consumer secret in Secrets Manager that supported the subscription before revoked. If the secret was deleted, it will include a key confirming it in addition to the deletion date time, detailing its recovery time window.
Related resources
- This Guidance leverages the open source project AWS SDK for pandas to support key workflow tasks including connecting to data sources for credential management. We recommend you review this information.
- This Guidance is an add-on to core functionalities of Amazon DataZone. We recommend you review the Amazon DataZone User Guide to better understand how Amazon DataZone works and how this Guidance complements its default features.
Contributors and Revisions
Contributors
- Jose Romero
Revisions
| Date | Change |
|---|---|
| April 2024 | Initial Release |
Notices
Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents AWS current product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. AWS responsibilities and liabilities to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers.
This solution is licensed under the terms of the of the Apache License Version 2.0 available at The Apache Software Foundation