Guidance for Low Latency, High Throughput Inference using Efficient Compute on Amazon EKS
Summary: This implementation guide provides an overview of the Guidance for Low Latency, High Throughput Inference using Efficient Compute on Amazon EKS, its reference architecture and components, considerations for planning the deployment, and configuration and automation steps for using the Guidance with Amazon Web Services (AWS). This guide is intended for Solution Architects, Business decision makers, DevOps engineers, Data scientists, and other Cloud professionals who want to implement Machine Learning Inference into their Amazon EKS environments.
Overview
In this Guidance, we describe a Machine Learning (ML) Inference architecture, developed in collaboration with the Commerce Einstein Team at Salesforce, and deployed on Amazon Elastic Kubernetes Service(Amazon EKS). It addresses the basic ML prerequisites, but also shows how to pack thousands of unique PyTorch deep learning (DL) models into a scalable container architecture. We explore a mix of Amazon Elastic Compute Cloud (Amazon EC2) Efficient Compute instance families (such as C5, C6i, C7g, and Inf2) for Amazon EKS Compute nodes to implement an optimal design from performance and cost aspects.
To optimize performance and cost, we build and deploy the DL inferencing service on Amazon EKS using FastAPI, a lightweight and efficient Python-based API server, and develop a model bin packing strategy to efficiently utilize compute and memory resources between models. To load test the architecture, we use a natural language processing (NLP) open-source PyTorch based model from Hugging Face (bert-base-cased, approximately 800 MB size) and simulate thousands of clients sending concurrent requests to the model’s service pool. You can use AWS Graviton Processor (an ARM based CPU chip) based Amazon EC2 C7g Instance or a “general purpose” X86_64 CPU on Amazon EC2 C5 Instance, or Amazon EC2 C6i Instance, or an Amazon Inferentia Inf2 Instance to package and serve a large number of unique PyTorch models to maximize utilization and cost efficiency.
With this architecture, you can scale ML inference across 3,000 PyTorch models, achieving a target latency of under 10 milliseconds, while simultaneously keeping costs under $60/hour (based on On-Demand pricing for Graviton based EKS nodes). You can match other model types with different instance types (including x86_64 based CPU, GPU, and Inferentia) and bin pack models accordingly by using the methodology described below.
Features and benefits
The Guidance for Low Latency, High Throughput Inference using Efficient Compute on Amazon EKS provides the following features:
Machine Learning inference workload deployment sample with optional bin packing.
This Guidance includes a code repository with an end-to-end example for running model inference locally on Docker, or at scale on Amazon EKS Kubernetes clusters. It supports compute nodes based on CPU (including x86_64 and Graviton), GPU, and Inferentia processors, and can pack multiple models in a single processor core for improved cost efficiency. While this example focuses on one processor architecture at a time, iterating over the steps described in the Deployment section below for CPU, GPU, and Inferentia enables “hybrid deployments,” where the optimal processor or accelerator is used to serve each model on different compute nodes, depending on its resource consumption profile. In this sample repository, we use a bert-base NLP model from Hugging Face, however, the project structure and workflow are generic and can be configured for use with other models.
Use Cases
More customers are finding the need to build larger, highly scalable, and more cost-effective machine learning (ML) inference pipelines in the cloud. Outside of these base prerequisites, the requirements of ML inference pipelines in production vary based on the business use case. A typical inference architecture for applications like recommendation engines, sentiment analysis, and ad ranking need to serve a large number of models, with a mix of classical ML and deep learning (DL) models.
Each model has to be accessible through an application programing interface (API) endpoint, and be able to respond within a predefined latency budget from the time it receives a request. Consequently, this Guidance demonstrates how we can serve thousands of models for different applications while satisfying performance requirements and being cost effective at the same time.
Architecture overview
This section provides an architecture diagram and describes the components deployed with this Guidance.
Architecture diagram
Below is the architecture diagram showing an Amazon EKS cluster with different processor types for compute nodes to which ML models can be deployed:
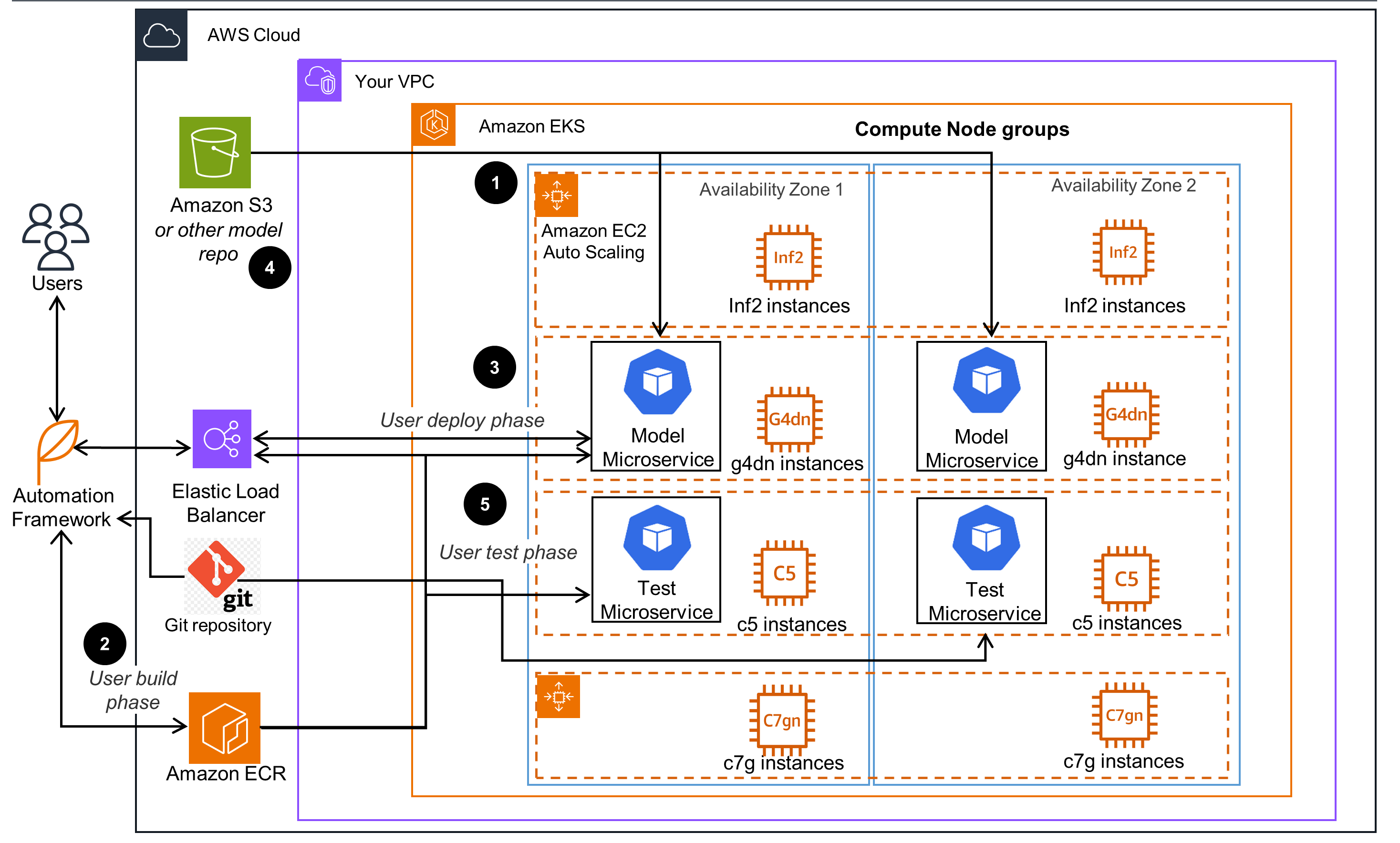
Figure 1: Sample Amazon EKS cluster infrastructure for deploying and running ML inference workloads
Please also refer to an accelerated video walkthrough (7 min) and follow the instructions in the section Deploying the Guidance to build and run your own ML inference solution.
Architecture Components and steps
- The Amazon EKS cluster has several node groups, with one Amazon EC2 instance family for each node group. Each node group can support different instance types, such as CPU (C5,C6i, C7g), AWS GPU (G5), AWS Inferentia (inf1, inf2) and can pack multiple models for each EKS node to maximize the number of served ML models that are running in a node group. Model bin packing is used to maximize compute and memory utilization of the Amazon EC2 instances in the cluster node groups.
- The natural language processing (NLP) open-source PyTorch model from Hugging Face, serving application and ML framework dependenciesz, are built by users as container images use an automation framework. These images are uploaded to Amazon Elastic Container Registry - Amazon ECR.
- Using the pproject Automation framework, the previously built model container images are obtained from Amazon ECR and deployed to an Amazon EKS cluster using generated deployment and service manifests through the Kubernetes API exposed through Elastic Load Balancing (ELB). Model deployments are customized for each deployment target EKS compute node instance type through settings in the central configuration file.
- Following the best practices of the separation of model data from containers that run it, the ML model microservice design allows it to scale out to a large number of models. In the sample project, model containers are pulling data from Amazon Simple Storage Service (Amazon S3) and other public model data sources each time they are initialized.
- Using the automation framework, the test container images are deployed to an Amazon EKS cluster using generated deployment and service manifests through the Kubernetes API. Test deployments are customized for each deployment target EKS compute node instance type through settings in the central configuration file. Load or scale testing is performed by sending simultaneous requests to the model service pool. Performance test results and metrics are obtained, recorded, and aggregated.
AWS Services in this Guidance
The following AWS Services are used in this Guidance:
- Amazon Elastic Compute Cloud - EC2
- Amazon Virtual Private Cloud - VPC
- Amazon Elastic Kubernetes Service - EKS
- Amazon Elastic Container Registry - ECR
- Amazon Elastic Load Balancer - ELB
- (Optional)Amazon Simple Storage Service -S3
Plan your deployment
Cost
You are responsible for the cost of the AWS services used while running this Guidance. As of September, 2023, the cost for running this Guidance with the default settings in the US East (N. Virginia) Region is approximately $21,273.36 monthly or $58 hourly, assuming maximum of 100 c7g.4xlarge compute nodes deployed with on-demand option.
Please refer to the sample pricing webpage for each AWS Service used in this Guidance. Please note that monthly costs calculated for maximum of 100 instances of both c7g.4xlarge and c5.4xlarge compute nodes (required for running and load testing thousands of ML models at scale from separate compute nodes, per our test results) are included into the estimate. For running a smaller number of ML models (and tests respectively), the required number of compute nodes are decreased along with overall cost. Prices are subject to change. For full details, refer to the pricing webpage for each AWS Service used in this Guidance.
Sample cost table
The following table provides a sample cost breakdown for deploying this Guidance for a requirement of running 3000 ML models (which in our tests required around 100 EKS Compute nodes) in the US East (N. Virginia) Region for different types of processors per hour:
| Node Processor Type | On Demand Cost/hr | Number of Nodes (3K ML models) | Cost, all Nodes/hr | EKS cluster/hr | Total EKS cost/hr |
|---|---|---|---|---|---|
| c7g.4xlarge (ARM) | $0.58 | 100 | $58 | $0.1 | $58.10 |
| c5.4xlarge (X86) | $0.68 | 100 | $68 | $0.1 | $68.10 |
| c6i.4xlarge (X86) | $0.68 | 100 | $68 | $0.1 | $68.10 |
| inf2.8xlarge (NPU) | $1.97 | 72 | $141.84 | $0.1 | $141.94 |
| g5.4xlarge (GPU) | $1.62 | 70. | $113.4 | $0.1 | $113.4 |
* This guidance has not conducted large scale testing of ML inference running on g5.4xlarge GPU compute nodes, so there may be less of that compute node instances needed to run up to 3000 ML models concurrently, therefore total costs may differ.
Security
When you build systems on AWS infrastructure, security responsibilities are shared between you and AWS. This Shared Responsibility Model reduces your operational burden because AWS operates, manages, and controls the components, including the host operating system, the virtualization layer, and the physical security of the facilities in which the services operate. For more information about AWS security, visit AWS Cloud Security.
The following Services are used to enhance the security of this Guidance: Amazon EKS, Amazon Virtual Private Cloud (Amazon VPC), Amazon Identity and Access Management (IAM) roles and policies, and Amazon ECR.
- The EKS cluster resources are deployed within Virtual Private Clouds (VPCs).
- Amazon VPC provides a logical isolation of its resources from the public internet. Amazon VPC supports a variety of security features, such as security groups, network access control lists (ACLs), which are used to control inbound and outbound traffic to resources, and IAM roles or policies for authorizating limited access to protected resources.
- The Amazon ECR image registry provides additional container level security features such as CVE vulnerability scanning etc.
Amazon ECR and Amazon EKS follow the Open Container Initiative and the Kubernetes API industry security standards respectively.
Supported AWS Regions
This Guidance uses c7g.4xlarge (Graviton) and Inf2.2xlarge (ML Inference optimized) EC2 service Instance types for EKS compute nodes, which may not currently available in all AWS Regions. You should launch this Guidance in an AWS Region where the EC2 instances intended to run the models are available. For the most current availability of AWS services by Region, please refer to the AWS Regional Services List.
This Guidance is currently supported in the following AWS Regions:
| Region Name | Supported |
|---|---|
| US East 2 (Ohio) | Y |
| US East 1 (N. Virginia) | Y |
| US West 1 (N. California) | N * |
| US West 2 (Oregon) | Y |
* As of Q3 2024 Inf2 instances are not available in us-west-1 (N. California) region, per EC2 Instance Pricing.
Quotas
Service quotas, also referred to as limits, are the maximum number of service resources or operations for your AWS account.
Quotas for AWS services in this Guidance
Make sure you have sufficient quota for each of the services implemented in this solution, specifically for the EC2 instance of the target processor architecture (C5,C7g,GPU and Inf2 ), if you plan on scaling the solution to support thousands of ML models. For more information, see AWS service quotas.
To view the service quotas for all AWS services in the documentation without switching pages, view the information in the Service endpoints and quotas page of the PDF document instead.
Deploying the Guidance
Deployment process overview
Before you launch the Guidance, review the cost, architecture, security, and other considerations discussed above. Follow the step-by-step instructions in this section to configure and deploy the Guidance into your AWS account.
Time to deploy: Approximately 30-45 minutes (70 -85+ minutes with optional EKS cluster provisioning)
Prerequisites
It is assumed that an Amazon EKS cluster exists to deploy this guidance on. If you would like to provision a dedicated EKS cluster for running this guidance, please follow the Optional Amazon EKS Cluster provisioning section below or use one of the EKS Blueprints for Terraform examples.
In addition, it is assumed that the following basic tools are installed:
You have to be authenticated to an environment with access to a target ECR registry and EKS cluster where you plan to deploy the Guidance code as an AWS user that has sufficient rights to create container images and push them to ECR registries, and create Compute Nodes in an EKS cluster (EKS admin level access). Please follow details in cluster authentication for reference.
Optional Amazon EKS Cluster provisioning
We highly recomend provisioning a dedicated EKS cluster with “opinionated” node group configurations for easy deployment of this guidance. You can initiate provisioning of dedicated EKS cluster by running the following script:
git clone https://github.com/aws-solutions-library-samples/guidance-for-machine-learning-inference-on-aws.git
cd guidance-for-machine-learning-inference-on-aws
./provision.sh
This will execute a script that creates a CloudFormation stack that deploys an EC2 “management” instance in your default AWS region (that can be changed in your local code). That instance also will execute a userData script which provisions an EKS cluster in us-west-2 region per specification from the following template which is a part of another GitHub project. After an EKS cluster is provisoned, it should be fully acessible from the EC2 “management” instance and this Guidance code repository will be copied there as well, ready to proceed to next steps.
It is highly recommended to connect to the EC2 “management” instance as shown in the fugures below and run the rest of commands from its CLI against the eksctl-eks-inference-workshop-cluster EKS cluster. Management EC2 Instance should be located in the Security group named like ManagementInstance-ManagementInstanceSecurityGroup-…
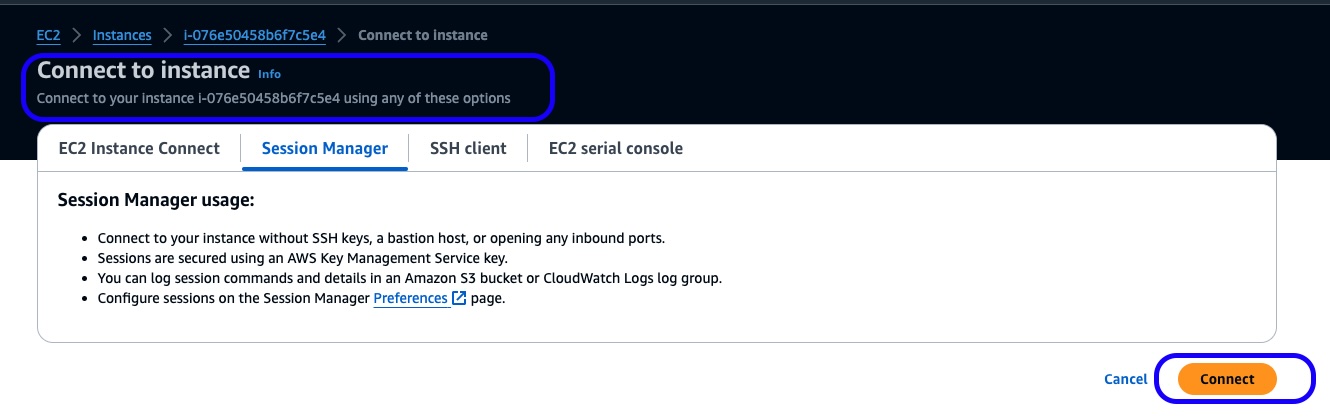
Figure 2: Connection to provisoned EC2 “management” instance via SSM
Once connected, run the following commands to confirm that dedicated EKS cluster provisoning has completed successfully, user ‘ec2-user’ can connect to Kubernetes API and specified compute nodes are available:
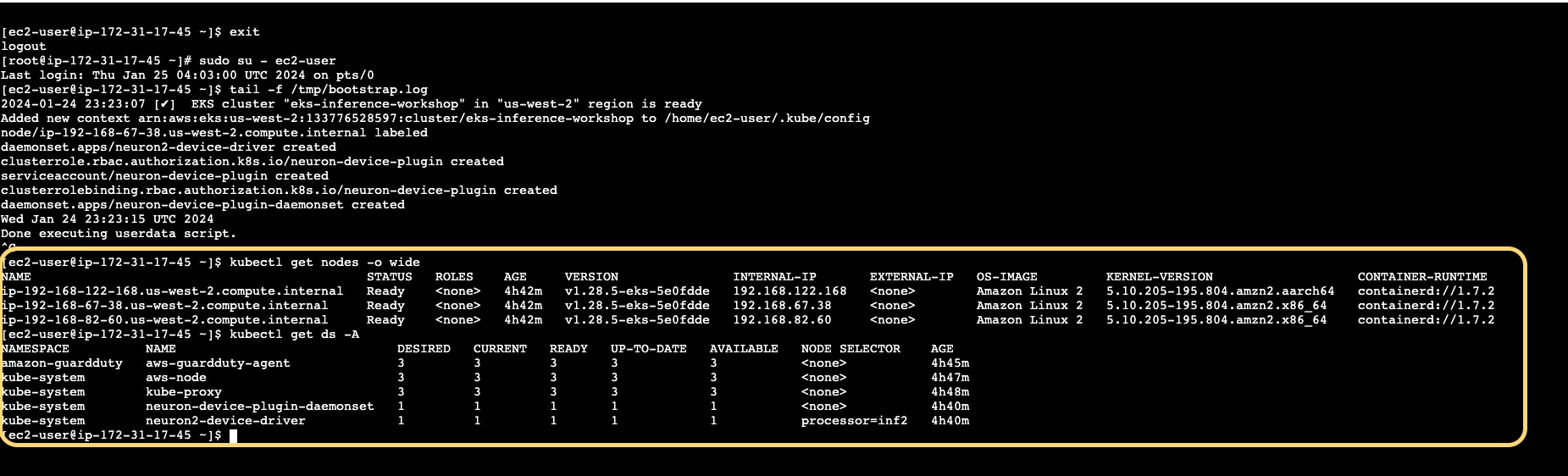
Figure 3: Validate provisioning status and connection to dedicated EKS cluster via CLI
Also, you can verify status of newly provisoned EKS cluster from the AWS console in us-west-2 region (or another region where you deploy the EKS cluster) as shown below:
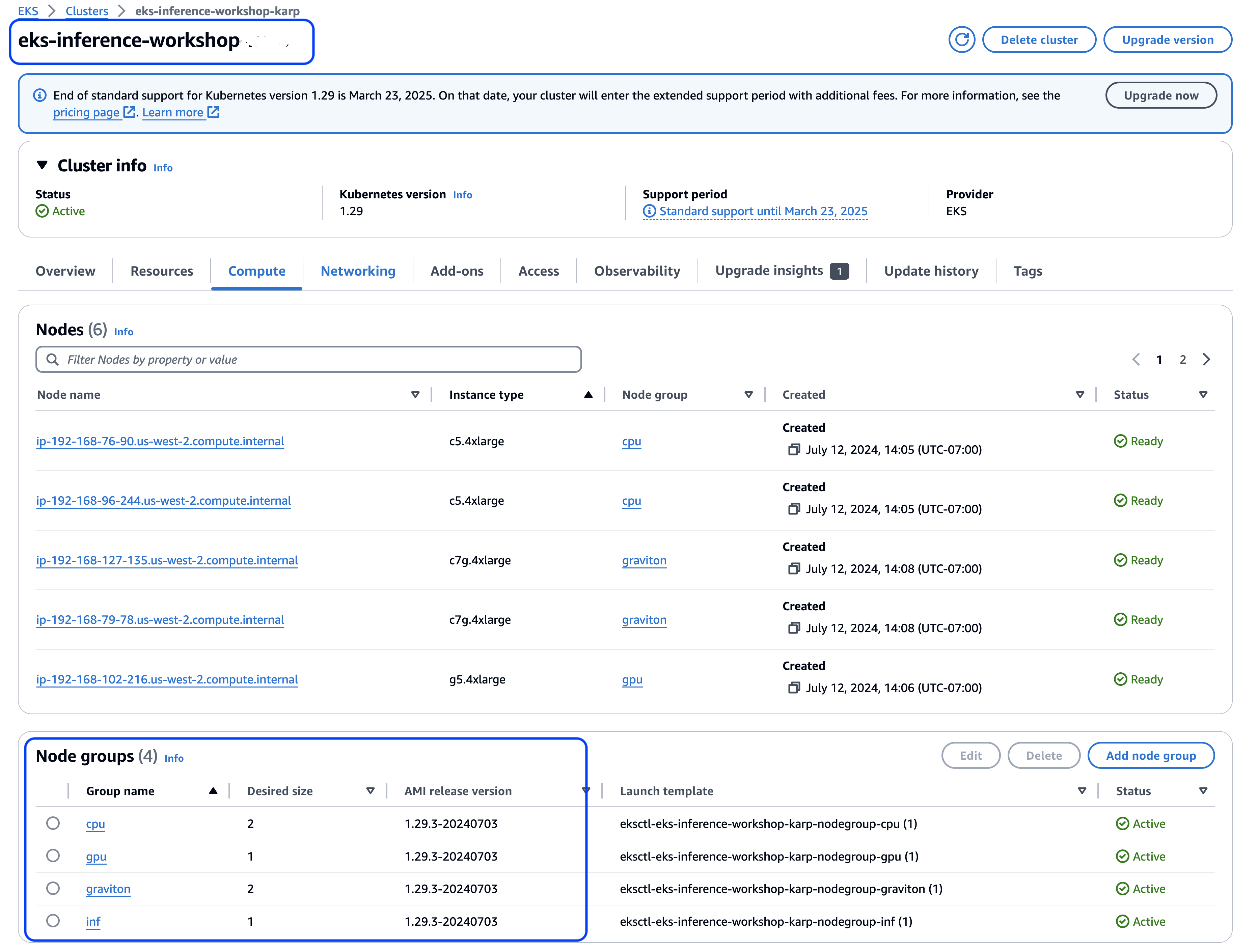
Figure 4: Status and Compute Node Groups of provisioned EKS cluster on AWS Console
Operations and Automation
This Guidance operates through a set of automation action scripts as described below. To complete a full cycle from beginning to end, first clone and configure the project code to your local environment:
git clone https://github.com/aws-solutions-library-samples/guidance-for-machine-learning-inference-on-aws.git
cd guidance-for-machine-learning-inference-on-aws
If running from EC2 “management” instance session, the guidance source code will be automatically copied into the ec2-user home directory to the folder called guidance-for-machine-learning-inference-on-aws
Follow steps 1 through 6 below invoking the corresponding action scripts. Please note that each of the action scripts has a help section, which can be displayed by passing “help” as argument:
<script>.sh help
Example:
./deploy.sh help
Usage: ./deploy.sh [arg]
This script deploys and manages the model servers on the configured runtime.
Both Docker for single host deployments and Kubernetes for cluster deployments are supported container runtimes.
If no arguments are specified, the default action (run) will be executed.
Available optional arguments:
run - deploy the model servers to the configured runtime.
stop - remove the model servers from the configured runtime.
status [id] - show current status of deployed model servers, optionally just for the specified server id.
logs [id] - show model server logs for all servers, or only the specified server id.
exec <id> - open bash shell into the container of the server with the specified id. Note that container id is required.
Configure
./config.sh
A centralized configuration file [config.properties][config.properties'](https://github.com/aws-solutions-library-samples/guidance-for-machine-learning-inference-on-aws/blob/main/config.properties){:target="_blank"} contains all settings that are customizable for this project. This file comes pre-configured with reasonable defaults that should work out of the box. To set the processor target, or any other setting, edit the config file, or run the config.sh` script to open a local text editor program. Configuration changes take effect immediately upon the processing of the next action script. Below is an explanation of its customization parameters:
Most of the project and configuration settings in this file have clear in-line comments explanations and examples of usage. Below are some of most important ones:
- verbose=true/false - project level setting, controls display verbose version of command run by the the framework
- processor=cpu/gpu/inf1/inf2/graviton - set a value according to target Compute Node architecture for building ML container images and related Deployment configurations
- registry=${account}.dkr.ecr.${region}.amazonaws.com/ - or a URL of a public registry (public.ecr.aws/XXXXXX/) like where Model and test images would be stored and available from
- base_image_name=aws-do-inference-base, base_image_tag=:v15-${processor}, model_image_name=${huggingface_model_name}, model_image_tag=;v15-${processor} - names and tags for base (before tracing and packing models) and model images
- num_models - number of models per a single model pod. That value along with num_servers settings determines “bin packing ratio” of total ML models per compute node and should be determined based on available node resources
- instance_type - very important setting that should match an EC2 instance type of computeNodes where Model pods will be deployed,
- num_servers - total number of model pods that will be deployed. Should be set according to number of available compute nodes and their resources, together with `num_models” determines “bin packing ratio”
- namespace - Kubernetes namespace where Model will be deployed
- app_name=${huggingface_model_name}-${processor} - Model application name for generating Kubernetes deploymet descriptors,
- app_dir=app-${app_name}-${instance_type} - file system directory where Model pod/service deployment manifests are generated and stored
- test_image_name=test-${huggingface_model_name}, test_image_tag=:v15-cpu - names and tags for Test service model images which also have to be built specifically for target compute Node types
- num_requests=30 - total number of requests to be issued by test microservices for random request testing
- num_test_containers - total number of test containers to launch (default=1), use > 1 for scale testing
- test_instance_type - very important setting that should match an EC2 instance type of computeNodes where Test service pods will be deployed,
- test_namespace - Kubernetes namespace where test pods will be created and run
- test_dir=app-${test_image_name}-${instance_type} - file system directory where Test job/pod deployment manifests are generated and stored
1. Pre-pull images from external ECR registries
To save time during the workshop, ML Inference model images for X86_64, Inferentia (inf2) and GPU (g5) processor architectures and Test service images for X86_64 architecture have been pre-built and available from a public ECR Registry with a URL like ‘public.ecr.aws/XXXXXXX/bert-base-workshop:’ (see ‘config.properties’ file for details).
Sample code include a command line script that pre-pulls those images based on the settings in the configuration file above. To run this command manually, perform the following:
cd ./0-provision
./prepull-workshop.sh
cd ..
This command calls another script (prepull.sh) to create Kubernetes daemonsets named like prepull-daemonset-model-inf2 (based on generated deployment descriptor called like prepull-daemonset-model-inf2.yaml) that will start and pull container images for specified entities (‘model’, ‘test’) and processor architectures (‘cpu’, ‘inf2’, ‘gpu’ etc.) set in the `config.properties’ file from public registry. Upon initialization of corresponding model or test deployments into EKS cluster additional time will not be spent on pulling those images on-demand.
The script above normally is executed upon cluster creation automatically, but may not work so running it again as shown above can be helpful.
2. Build
./build.sh
This step builds a base container image for the selected processor that is required for any of the subsequent steps. This step can be processed on any EC2 instance type, regardless of the processor target.
Optionally, if you’d like to push the base image to a container registry (such as Amazon ECR), run ./build.sh push. Pushing the base image to a container registry is required if you are planning to run the test activities against models deployed to Kubernetes. If you are using a private registry and you need to login before pushing, run ./login.sh. This script will login to Amazon ECR and other private registry implementations can be added to the script as needed.
3. Trace
./trace.sh
This step compiles a model into a TorchScript serialized graph file (.pt). This step requires the model to run on the target processor. Therefore, it is necessary to run this step on an EC2 instance that based on a target processor (like “management” instance that is based on Graviton CPU).
Upon successful compilation, the model will be saved in a local folder named trace-{model_name}.
It is generally recommended to use the AWS Deep Learning AMI to launch the instance where your model will be traced.
To trace a model for GPU, run the trace step on a AWS GPU instance launched with the AWS DLAMI.
- To trace a model for Inferentia, run the trace step on an AWS Inferentia instance launched with AWS Deep Learning AMI with Neuron and activate the Neuron compiler conda environment.
- To trace a model for Graviton, run the trace step on a Graviton c7g instance.
4. Pack
./pack.sh
This script packs the model in a container with FastAPI, allowing for multiple models to be packed within the same container. FastAPI is used as an example here for simplicity and performance, however it can be interchanged with any other model server. For the purpose of this project, we pack several instances of the same model into a single container, however, a natural extension of the same concept is to pack different models into a single container.
To push the model container image to a container registry, run ./pack.sh push (it must be pushed to a registry if you are deploying your models to Kubernetes unless you are using previously built images available from a public ECR registry for specified compute Node architecture).
5. Deploy
./deploy.sh run
This script helps to deploy and run your models on the configured runtime platform. The project has built-in support for both local Docker runtimes and Kubernetes orchestration, including an option to schedule pods on EKS compute nodes of specific instance type. These instance types can be specified in the `config.properties’ configuration file through an ‘instance_type’ configuration parameter like: ‘instance_type=c7g.4xlarge’ (for “c7g.4xlarge” instance)
Other model run-time configuration parameters include:
- ‘num_models’ - how many models can be included into a model pod (such as 10),
- ‘quet’ - whether model services should print logs (True/False),
- ‘service_port’ - port on which service will be exposed (such as 8000),
- ‘num_servers’ - total number of model pods that will be deployed across compute nodes. That number along with ‘num_models’ impacts node resource utilization
- ‘namespace’ - Kubernetes namespace where model pods will be deployed
- ‘app_name’ - Kubernetes application name used for deployment manifests
- ‘app_dir’ - file directory where model deployment manifests will be stored
The deploy, the script also has several sub-commands that facilitate a full lifecycle management of your model server containers or pods.
./deploy.sh run- (default) deploys and runs Model server containers./deploy.sh status [number]- show container / pod / service status. Optionally, show only specified instance [number]./deploy.sh logs [number]- tail container logs. Optionally, tail only specified instance [number]./deploy.sh exec <number>- open bash into model server container with the specified instance./deploy.sh stop- stop and un-deploy model contaniers from runtime (e.g. Kubernetes namespace)
The deployment step relies on Kubernetes’ deployment descriptors generated from templates located in the project repository folder - with a .template extension. You may customize compute node resource utilization using the resources YAML element of those templates to specify the amount of RAM and other resources that should be reserved by each model pod. Such setting effectively controls how many model pods can be scheduled by EKS per compute node, based on its total RAM resources.
The example below shows a fragment of the graviton-yaml.template file that is used to ensure that exactly one model pod gets scheduled onto the c7g.4xlarge compute node with 32 GB RAM:
.....
containers:
- name: main
image: "${registry}${model_image_name}${model_image_tag}"
imagePullPolicy: Always
env:
- name: NUM_MODELS
value: "${num_models}"
- name: POSTPROCESS
value: "${postprocess}"
- name: QUIET
value: "${quiet}"
ports:
- name: pod-port
containerPort: 8080
resources:
limits:
memory: "27000Mi"
requests:
#Total node memory resource is about 32 GB for c7g.4xlarge insance
memory: "27000Mi"
With this configuration, a Kubernetes scheduler should deploy exactly one model pod onto each c7g.4xlarge EKS compute node. You can adjust those parameters to achieve a similar “model packing” effect for your specific EKS compute nodes, based on their resources with more models per node, if desired. We advise against reserving CPU resources in the resources section as it essentially causes CPU throttling.
6. Test
./test.sh
This automation script helps deploy and run a number of tests against the model servers deployed in your runtime environment. It has the following command options:
./test.sh build- build test container image./test.sh push- push test image to container registry./test.sh pull- pull the current test image from the container registry if one exists./test.sh run- run a test client container instance for advanced testing and exploration./test.sh exec- open shell in test container./test.sh status- show status of test container./test.sh stop- stop test container./test.sh help- list the available test commands./test.sh run seq- run sequential test. One request at a time submitted to each model server and model in sequential order../test.sh run rnd- run random test. One request at a time submitted to a randomly selected server and model at a preset frequency../test.sh run bmk- run benchmark test client to measure throughput and latency under load with random requests./test.sh run bma- run benchmark analysis - aggregate and average stats from logs of all completed benchmark containers
Test pods also have options to be scheduled on specific Instance type EKS compute nodes that can be specified in the ‘config.properties’ file on a ‘test_instance_type’ parameter, like: test_instance_type=m5.large
Other settings related to testing scenarios are:
- ‘request_frequency’ - time to sleep between two consecutive HTTP requests
- ‘num_requests’ - max number of random requests if that test mode is selcted
- ‘num_test_containers’ - total number of test pods or containers to launch conurrently, for scaling test requests
- ‘test_namespace’ - Kubernetes namespace where test pods will be deployed
- ‘test_dir’ - file directory where test pod deployment manifests will be stored
Sample configuration properties and commands to run scale tests
Below is an example of config.properties configuration file with settings for a CPU type, and compute node instance types, for deploy and test tasks:
#!/bin/bash
# This file contains all customizable configuration items for the project
# core version to be used at re:Invent 23 builder sessions
######################################################################
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved. #
# SPDX-License-Identifier: MIT-0 #
######################################################################
# Project settings
# display verbose output of commands executed by framework scripts
verbose=true
# Model settings
huggingface_model_name=bert-base-multilingual-cased
huggingface_tokenizer_class=BertTokenizer
huggingface_model_class=BertForQuestionAnswering
# Compiler settings
# processor = cpu|gpu|inf1|inf2|graviton
processor=graviton
pipeline_cores=1
sequence_length=128
batch_size=1
test=True
# account is the current AWS user account. This setting is determined automatically.
account=$(aws sts get-caller-identity --query Account --output text)
# region is used to login if the registry is ecr
region=us-west-2
# Container settings
# Default is the private ECR registry in the current AWS account.
# If registry is set, include the registry uri up to the image name, end the registry setting with /
# registry setting for locally built images uploaded to local ECR
registry=${account}.dkr.ecr.${region}.amazonaws.com/
# registry_type=ecr
registry_type=ecr
base_image_name=aws-do-inference-base
base_image_tag=:v15-${processor}
model_image_name=${huggingface_model_name}
model_image_tag=:v15-${processor}
# if using pre-built public ECR registry Model image (may require authentication) use the following settings:
#registry=public.ecr.aws/a2u7h5w3/
#model_image_name=bert-base-workshop
#model_image_tag=:v15-${processor}
# Trace settings
# trace_opts_$processor is a processor-specific setting used by the docker run command in the trace.sh script
# This setting will be automatically assigned based on your processor value
trace_opts_cpu=""
trace_opts_gpu="--gpus 0"
trace_opts_inf1="-e AWS_NEURON_VISIBLE_DEVICES=ALL --privileged"
trace_opts_inf2="-e AWS_NEURON_VISIBLE_DEVICES=ALL --privileged"
trace_opts_graviton=""
# Deployment settings
# some of these settings apply only when the runtime is kubernetes
# runtime = docker | kubernetes
runtime=kubernetes
# number of models per model server
num_models=16
# quiet = False | True - sets whether the model server should print logs
quiet=False
# postprocess = True | False - sets whether tensors returned from model should be translated back to text or just returned
postprocess=True
# service_port=8080 - port on which model service will be exposed
service_port=8080
# Kubernetes-specific deployment settings
# instance_type = c5.xxx | g4dn.xlarge | g4dn.12xlarge | inf1.xlarge | inf2.8xlarge | c7g.4xlarge...
# A node group with the specified instance_type must exist in the cluster
# The instance type must have the processor configured above
# Example: processor=graviton, instance_type=c7g.4xlarge
instance_type=c7g.4xlarge
# num_servers - number of model servers to deploy
# note that more than one model server can run on a node with multiple cpu/gpu/inferentia chips.
# example: 4 model servers fit on one inf1.6xlarge instance as it has 4 inferentia chips.
num_servers=1
# Kubernetes namespace
namespace=mpi
# Kubernetes app name
app_name=${huggingface_model_name}-${processor}
app_dir=app-${app_name}-${instance_type}
# Test image settings - using locally built images
#test_image_name=test-${huggingface_model_name}
#test_image_tag=:v15-cpu
#Test settings - using pre-built test image available in public ECR registry (may require authentication):
test_image_name=bert-base-workshop
test_image_tag=:test-v15-cpu
# request_frequency - time to sleep between two consecutive requests in curl tests
request_frequency=0.01
# Stop random request test after num_requests number of requests
num_requests=30
# Number of test containers to launch (default=1), use > 1 for scale testing
num_test_containers=5
# test_instance_type - when runtime is kubernetes, node instance type on which test pods will run
test_instance_type=c5.4xlarge
# test_namespace - when runtime is kubernetes, namespace where test pods will be created
test_namespace=mpi
# test_dir - when runtime is kubernetes, directory where test job/pod manifests are stored
test_dir=app-${test_image_name}-${instance_type}
Assuming that both Model and Test container images have been built and pushed to local ECR registry (or pre-built and uploaded to a public ECR repository and correspinding settings updated in the config.properties file), the following command should deploy Model services into an EKS cluster compute nodes that would match the condition instance_type=c5.4xlarge:
./deploy.sh run
STARTING MODEL DEPLOYMENT
--------------------------
Runtime: kubernetes
Processor: cpu
namespace/mpi configured
Generating ./app-bert-base-multilingual-cased-cpu-c5.4xlarge/bert-base-multilingual-cased-cpu-0.yaml ...
Generating ./app-bert-base-multilingual-cased-cpu-c5.4xlarge/bert-base-multilingual-cased-cpu-1.yaml ...
Generating ./app-bert-base-multilingual-cased-cpu-c5.4xlarge/bert-base-multilingual-cased-cpu-2.yaml ...
Generating ./app-bert-base-multilingual-cased-cpu-c5.4xlarge/bert-base-multilingual-cased-cpu-3.yaml ...
service/bert-base-multilingual-cased-cpu-0 created
deployment.apps/bert-base-multilingual-cased-cpu-0 created
service/bert-base-multilingual-cased-cpu-1 created
deployment.apps/bert-base-multilingual-cased-cpu-1 created
service/bert-base-multilingual-cased-cpu-2 created
deployment.apps/bert-base-multilingual-cased-cpu-2 created
service/bert-base-multilingual-cased-cpu-3 created
deployment.apps/bert-base-multilingual-cased-cpu-3 created
To verify that Kubernetes (K8s) deployments and pods are indeed running in the designated K8s namespace, run the following command:
kubectl get deploy,po -n mpi
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/bert-base-multilingual-cased-cpu-0 1/1 1 1 3m37s
deployment.apps/bert-base-multilingual-cased-cpu-1 1/1 1 1 3m37s
deployment.apps/bert-base-multilingual-cased-cpu-2 1/1 1 1 3m36s
deployment.apps/bert-base-multilingual-cased-cpu-3 1/1 1 1 3m36s
NAME READY STATUS RESTARTS AGE
pod/bert-base-multilingual-cased-cpu-0-79bcf7b9f9-8whcx 1/1 Running 0 3m37s
pod/bert-base-multilingual-cased-cpu-1-6f8d86d499-w7h62 1/1 Running 0 3m37s
pod/bert-base-multilingual-cased-cpu-2-679c46b459-ftmfc 1/1 Running 0 3m36s
pod/bert-base-multilingual-cased-cpu-3-778dc66687-w5zwp 1/1 Running 0 3m36s
To verify that model pods are deployed onto designated compute nodes specified by an instance_type parameter, you can run the following command:
kubectl describe po bert-base-multilingual-cased-cpu-0-79bcf7b9f9-8whcx -n mpi | grep Node
Node: ip-10-11-15-232.ec2.internal/10.11.15.232
Node-Selectors: node.kubernetes.io/instance-type=c5.4xlarge
To deploy test pods onto designated compute nodes and run a Benchmarking test (other options are available as well), run the following command:
./test.sh run bmk
Runtime: kubernetes
namespace/mpi configured
cmd_pod=pushd /app/tests && ./benchmark.sh
template=./job-yaml.template
Generating ./app-test-bert-base-multilingual-cased-c5.4xlarge/test-bert-base-multilingual-cased-0.yaml ...
job.batch/test-bert-base-multilingual-cased-0 created
To verify that test requests are being issued to Model services, you may run the following commands to identify corresponding pods and review its container logs:
kubectl get po -n mpi | grep test
NAME READY STATUS RESTARTS AGE
test-bert-base-multilingual-cased-0-XXXXX 1/1 Running 0 3m21s
kubectl logs -f test-bert-base-multilingual-cased-0-XXXXX -n mpi
/app/tests /
Number of model servers (4) configured from environment ...
Namespace(url='http://bert-base-multilingual-cased-cpu-[INSTANCE_IDX].mpi.svc.cluster.local:8080/predictions/model[MODEL_IDX]', num_thread=2, latency_window_size=1000, throughput_time=180, throughput_interval=10, is_multi_instance=True, n_instance=4, is_multi_model_per_instance=True, n_model_per_instance=15, post=False, verbose=False, cache_dns=True)
caching dns
http://bert-base-multilingual-cased-cpu-2.mpi.svc.cluster.local:8080/predictions/model2
<Response [200]>
{'pid': 7, 'throughput': 0.0, 'p50': '0.000', 'p90': '0.000', 'p95': '0.000', 'errors': '0'}
{'pid': 7, 'throughput': 30.1, 'p50': '0.056', 'p90': '0.092', 'p95': '0.100', 'errors': '0'}
{'pid': 7, 'throughput': 28.9, 'p50': '0.061', 'p90': '0.093', 'p95': '0.102', 'errors': '0'}
{'pid': 7, 'throughput': 30.4, 'p50': '0.057', 'p90': '0.093', 'p95': '0.101', 'errors': '0'}
..........
{'pid': 7, 'throughput': 29.5, 'p50': '0.058', 'p90': '0.094', 'p95': '0.111', 'errors': '0'}
{'pid': 7, 'throughput': 29.7, 'p50': '0.054', 'p90': '0.095', 'p95': '0.108', 'errors': '0'}
Each entry shows a set of metrics that are obtained for the request throughput and average response times (seconds) for 50%,90% and 95% of all requests. Once all test jobs have completed, to display aggregated metrics values, run the following command:
./test.sh run bma
Runtime: kubernetes
kubectl -n mpi get pods | grep test-bert-base-multilingual-cased- | cut -d ' ' -f 1 | xargs -L 1 kubectl -n mpi logs | grep { | grep -v 0.0, | tee ./bmk-all.log
{'pid': 7, 'throughput': 30.1, 'p50': '0.056', 'p90': '0.092', 'p95': '0.100', 'errors': '0'}
{'pid': 7, 'throughput': 28.9, 'p50': '0.061', 'p90': '0.093', 'p95': '0.102', 'errors': '0'}
{'pid': 7, 'throughput': 30.4, 'p50': '0.057', 'p90': '0.093', 'p95': '0.101', 'errors': '0'}
{'pid': 7, 'throughput': 30.3, 'p50': '0.057', 'p90': '0.093', 'p95': '0.101', 'errors': '0'}
{'pid': 7, 'throughput': 29.6, 'p50': '0.055', 'p90': '0.094', 'p95': '0.102', 'errors': '0'}
{'pid': 7, 'throughput': 30.5, 'p50': '0.056', 'p90': '0.094', 'p95': '0.101', 'errors': '0'}
{'pid': 7, 'throughput': 29.9, 'p50': '0.055', 'p90': '0.093', 'p95': '0.101', 'errors': '0'}
.............
{'pid': 7, 'throughput': 29.5, 'p50': '0.058', 'p90': '0.094', 'p95': '0.111', 'errors': '0'}
{'pid': 7, 'throughput': 29.7, 'p50': '0.054', 'p90': '0.095', 'p95': '0.108', 'errors': '0'}
**Aggregated statistics ...
{ 'throughput_total': 29.4, 'p50_avg': 0.060, 'p90_avg': 0.094, 'p95_avg': 0.105, 'errors_total': 0 }**
The aggregated statitcs for the Benchmarking test is displayed in the last Line.
Uninstall the Guidance
You can uninstall the sample code for this Guidance using the AWS Command Line Interface. You must also delete the EKS cluster if it was deployed using references from this Guidance, since removal of the scale testing framework does not automatically delete Cluster and its resources.
To stop or uninstall scale Inferencetest job(s), run the following command:
./test.sh stop
It should delete all scale Test pods and jobs that intialized them from the specified EKS K8s namespace.
To stop or uninstall Inference model services, run the following command:
./deploy.sh stop
It should delete all Model deployments, pods, and services from the specified EKS K8s namespace.
If you provisioned a dedicated EKS cluster as described above in the part of Optional - Provision an EKS Cluster section above, you can delete that cluster and all resources associated with it by running this script from your computer:
cd guidance-for-machine-learning-inference-on-aws
./remove.sh
It should delete EKS cluster compute node groups first, then IAM service account used by that cluster, then cluster itself and, finally, ManagementInstance EC2 instance by deletion of corresponding Cloud Formations. Sometimes you may need to run that command a few times as individual stack deletion commands may time out - that should not create any problem.
Sample ML Inference Scale Testing Results
Below are sample ML Inference Scale Testing results obtained for running Model Inference services on various EKS Compute Nodes processor architectures.
The purple color is data for AWS Graviton based c7g.4xlarge compute node instances, green and blue - for x86_64 CPU based c5.4xlarge, and c6i.4xlarge instances, and brown and black - for inf2.8xlarge and inf2.24xlarge processor based instances respectively:
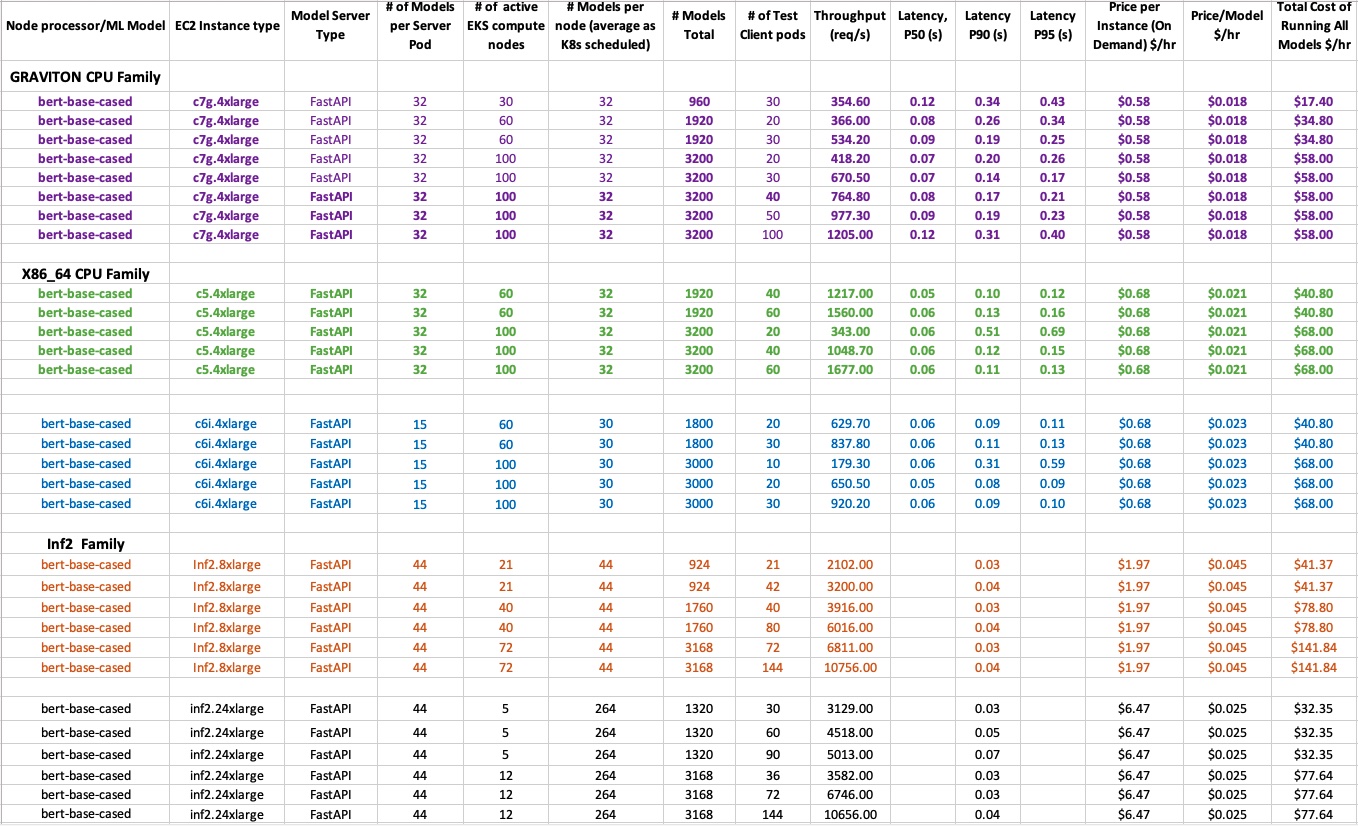
Figure 5: Sample Benchmark Test results and costs of running ML Inference services on Graviton ARM 64, x86_64 and Inferentia based compute EKS nodes of various architectures
Support and Troubleshooting
Support & Feedback
‘Guidance for Low Latency High Throughput Machine Learning Inference using Amazon EKS’ is an Open-Source project maintained by AWS Solution Architects. It is not an AWS service and support is provided on a best-effort basis by AWS Solution Architects and the user community. To post feedback, submit feature ideas, or report bugs, you can use the Issues section of the project GitHub repo.
If you are interested in contributing to the Sample code, you can follow the Contribution guide.
Component Version Requirements
This version of guidance the following version of core tools/services:
| Name | Version |
|---|---|
| aws | >= 2.11.2 |
| http | >= 2.4.1 |
| kubernetes | >= 1.26 |
| kubectl | >= 1.26 |
| docker | >= 21.0.0 |
Customization
Please keep in mind that all scripts and configuration files provided in this Guidance are customizable, mostly via settings in the config.properties central configuration file and related shell scripts in various steps of the project workflow. For example, ML service K8s Deployment file.
This Guidance has been successfully tested with values of those parameters used in the sample code in the repository project, with an exception of # Model settings and #Trace options parameters that did not have to be modified. Also, while the scale tests were performed against EKS clusters with X86_64 and Graviton ARM64 based Compute nodes, other node processor types (GPU, Inferentia) are definitely supported and may demonstrate good performance as well.
While you may specify different values for customization parameters through config.properties, you should be aware of your Amazon EKS cluster and resources, and use values that make sense for your environment. We provide sample configuration settings for that file with poperties related to Model and Test phase based on pre-built container images available from a public ECR directory: this one for Models running on Graviton c7g.4xlarge compute nodes and Test - on c5.4xlarge nodes and this one - for Models running on Inferentia inf2.2xlarge compute nodes and Test - on c5.4xlarge nodes. You can back up existing version of config.properties file under a different name/extension, rename those file(s) to config.properties and continue running commands using that new config file version.
Troubleshooting
The Automation Framework used in this project is implemented through shell scripts that call Docker or Kubernetes API as well as AWS API commands that generate extensive logs when those commands are executed. If deployment of this Guidance fails for some reason (usually during execution of shell script command), you can find error messages in the CLI command output and/or by reviewing Kubernetes object logs and event records.
- In many cases, errors are caused by invalid configuration settings specified in the config.properties configuration file. For example, target EKS compute node type mismatch and/or incorrectly estimated number of models/pods or total number of model servers (pods):
...
# number of models per model server
num_models=16
...
# The instance type must have the processor configured above
# Example: processor=graviton, instance_type=c7g.4xlarge
instance_type=c5.4xlarge
# num_servers - number of model servers to deploy
# note that more than one model server can run on a node with multiple cpu/gpu/inferentia chips.
# example: 4 model servers fit on one inf1.6xlarge instance as it has 4 inferentia chips.
# 2 model pods with 15 models or one pod with 32 models tend to fit onto c7g.4xlarge or c5.4xlarge node - double value for pushing servers to deploy on all 4 nodes
num_servers=50
If instance_type value does not match actual compute Node type, model services will not deploy to any nodes and a test will fail to run. To list the node instance types available in your cluster, run the following command:
kubectl get nodes --show-labels | grep -i instance-type
----
ip-10-11-15-232.ec2.internal Ready <none> 22d v1.24.13-eks-0a21954 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/instance-type=c5.4xlarge,beta.kubernetes.io/os=linux,eks.amazonaws.com/capacityType=ON_DEMAND,eks.amazonaws.com/nodegroup-image=ami-08c95f33fc51670df,eks.amazonaws.com/nodegroup=cpu-x86-man,failure-domain.beta.kubernetes.io/region=us-east-1,failure-domain.beta.kubernetes.io/zone=us-east-1a,k8s.io/cloud-provider-aws=51d0ed1b12453098a108c272e71e962f,kubernetes.io/arch=amd64,kubernetes.io/hostname=ip-10-11-15-232.ec2.internal,kubernetes.io/os=linux,node.kubernetes.io/instance-type=c5.4xlarge,node_arch=x86_64,node_role=compute,scale_model=bert,topology.kubernetes.io/region=us-east-1,topology.kubernetes.io/zone=us-east-1a
....
Note the value of the node.kubernetes.io/instance-type label and use it for the instance_type configuration parameter in the config.properties file above. You can find detailed error messages displayed on your CLI console, or by reviewing K8s events as shown below for the scenario when instance_type nodes are not available in the EKS Cluster:
kubectl get events -n mpi
LAST SEEN TYPE REASON OBJECT MESSAGE
--------------------------------------------------------------------------------------------------------------
30s Warning FailedScheduling pod/bert-base-multilingual-cased-graviton-0-XXXXXXX-mlrds 0/4 nodes are available: 4 node(s) didn't match Pod's node affinity/selector. preemption: 0/4 nodes are available: 4 Preemption is not helpful for scheduling.
30s Normal SuccessfulCreate replicaset/bert-base-multilingual-cased-graviton-0-XXXXXXX Created pod: bert-base-multilingual-cased-graviton-0-XXXXXXXX-mlrds
30s Normal ScalingReplicaSet deployment/bert-base-multilingual-cased-graviton-0 Scaled up replica set bert-base-multilingual-cased-graviton-0-XXXXXXXX to 1
...
mpi is the default value of K8s namespace defined in the namespace parameter, if you specified another value, the above command would use that value for the *..-n
Similarly, the value of the test_instance_type configuration parameter should match the value of the node.kubernetes.io/instance-type of those nodes where Test pods (simulating concurrent client requests at scale) and incorrect value specified can cause failure to schedule Test pods on compute nodes. Also, please note that container images built in the Build and Pack steps above, and uploaded to ECR, should match the processor architecture of the compute nodes’ instance types in the config.properties configuration file for both model and test containers. These settings are the following:
...
#for model pods
model_image_name=${huggingface_model_name}
model_image_tag=:v15-${processor}
...
test_image_name=test-${huggingface_model_name}
test_image_tag=:v15-cpu
...
For example, for model images built to run on Graviton CPU based nodes, the framework will use image tagged like:
image: "13377652XXXX.dkr.ecr.us-east-1.amazonaws.com/bert-base-multilingual-cased:v15-graviton"
and for test images built to run on X86_64 CPU based nodes:
image: "13377652XXXX.dkr.ecr.us-east-1.amazonaws.com/test-bert-base-multilingual-cased:v15-cpu"
- If the num_servers value exceeds the total workload that EKS compute Nodes can actually run (assuming relatively even distribution of model pods across nodes which can be achieved using ‘requests’ fields in K8s deployment templates), some model pods will fail to get scheduled on designated nodes and (partts of) the scale test would fail.
The project team is adding compute node auto-scaling capabilities using Karpenter add-on and KEDA horizontal pod auto-scaler across specified node types, so you using that options you will be able to rely on workload resource utilization metrics to automatically scale compute nodes**
Contributors
- Alex Iankoulski, Principal SA, ML Frameworks
- Daniel Zilberman, Sr SA AWS Tech Solutions Team
- Judith Joseph, Sr SA AWS Tech Solutions Team
- Modestus Idoko, SA, ML Frameworks
Security
See CONTRIBUTING for more information.
License
This library is licensed under the MIT-0 License. See the LICENSE file.
References
- Huggingface
- EKS
- aws-do-eks
- FastAPI
- AWS GPU
- AWS Inferentia
- AWS Graviton
- Instance Selector
- kubetail
- envsubst
- AWS Machine Learning blog post
Notices
Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents AWS current product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. AWS responsibilities and liabilities to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers.