Loading Data with InsuranceLake
This page explains best practices for loading data using InsuranceLake.
Contents
- Landing Source Data
- Bucket Layout
- Configuration Recommendations
- Data Profile
- File Format Identification
- Corrupt Data
- Building Dependent Workflows
- Execute Pipeline without Upload
- Override Partition Values
Landing Source Data
The InsuranceLake ETL process is triggered when data is landed in the Collect S3 bucket.
We recommend starting your data preparation process by loading your data right away, without any configuration, so you can begin exploring your data using Athena SQL and Spark-based notebooks. This section will provide the information needed to get the best results from this process.
You can land your data in the Collect S3 bucket through:
- The S3 Console, which can be used to create folders and drag and drop files.
- AWS SDKs or REST APIs, which can be used to embed file copying into workflows and applications.
- AWS CLI, which can copy objects from local machines or through scripts with a full path.
- AWS Transfer Family, which can receive data through an SFTP endpoint.
- AWS Database Migration Service (DMS), which can use S3 as a target.
- Amazon AppFlow, which can be used to transfer data from a SaaS source (for example, SalesForce) to Amazon S3.
For walkthroughs, examples, and details refer to the AWS Documentation Uploading objects to S3.
When you load data with no configuration, the ETL will automatically clean all column names so that they can be saved successfully in Parquet format.
Bucket Layout
To enable transform specifications to be matched with source system data and organized in groups, each of the three ETL stage buckets (Collect, Cleanse, Consume) have similar directory layouts. The first level represents the source system name or the database that will group the underlying tables. The second layer represents the data set or table containing the uploaded data. In the Collect bucket, the source files are stored at the second layer. In the Cleanse bucket, data is converted to compressed Parquet files and stored in partitions at the second layer.
When you create the folder structure for storing source files in the Collect bucket, you are defining the folder layout for the Cleanse and Consume bucket, as well as defining the database and table organization in the Data Catalog.
S3 objects landed with less than two levels of folder depth will be ignored by the state-machine-trigger Lambda function; no ETL workflow will be triggered. S3 objects landed with more than two levels of folder depth will be processed with Partition Value Override.
Data pipeline maintainers can configure the Cleanse-to-Consume AWS Glue job to create multiple tables in the Consume layer and to override the table name provided in the folder structure. Therefore, the Consume layer will not always match the Collect bucket layout.
An example bucket layout follows:
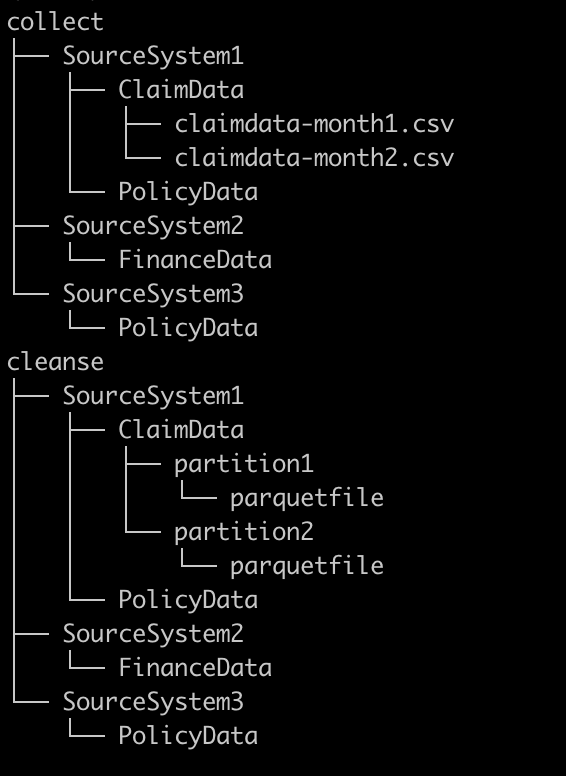
The files for the transformation and input configuration, schema mapping, data quality rules, Athena and Spark SQL, and entity matching configuration will also follow a naming convention that matches the bucket layout.
This matching is case sensitive (Data Catalog database and table names will lose case sensitivity when created and always appear in all lowercase).
Naming convention and location of configuration files
| Purpose | ETL Scripts Bucket Location | Naming Convention |
|---|---|---|
| Schema Mapping | /etl/transformation-spec | <database name>-<table name>.csv |
| Transformation/Input Config | /etl/transformation-spec | <database name>-<table name>.json |
| Data Quality Rules | /etl/dq-rules | dq-<database name>-<table name>.json |
| Spark SQL | /etl/transformation-sql | spark-<database name>-<table name>.sql |
| Athena SQL | /etl/transformation-sql | athena-<database name>-<table name>.sql |
| Entity Match Config | /etl/transformation-spec | <database name>-entitymatch.json |
Configuration Recommendations
When the ETL loads source data with no schema mapping or transformation configuration files, it will create recommended configurations. These recommendations are saved to the AWS Glue job Temp S3 bucket, which follows the naming convention <environment>-insurancelake-<account>-<region>-glue-temp, in the folder /etl/collect_to_cleanse, in a file which follows the naming convention <database>-<table> (extension csv for schema mapping and json for transformations). Simply copy the files to your development environment, edit them as needed, and upload them to the ETL Scripts S3 bucket in the appropriate location.
Using these recommendations helps accelerate your creation of configuration files with a syntactically correct template and a complete list of fields in the schema.
More details are available on how the ETL generates these recommendations:
To get started quickly building a set of data quality rules with recommendations, use Glue Data Quality Recommendations.
Data Profile
AWS Glue DataBrew is a visual data preparation tool that allows business analysts, data scientists, and data engineers to more easily collaborate to get insights from data. Profile jobs in DataBrew run a series of evaluations on a dataset and output the results to Amazon S3. The information that data profiling gathers helps you understand your dataset and decide what kind of data preparation steps you might want to run in your recipe jobs. For more details, refer to the AWS documentation on creating and working with AWS Glue Databrew profile jobs.
Follow these instructions for quickly creating a data profile for the Data Catalog tables you’ve created with InsuranceLake:
- Open the AWS Glue DataBrew service in the AWS Console.
- Select
Datasetsfrom the navigation menu on the left. - Select
Connect new dataset. - Under Connect to new dataset, select
Data Catalog S3 tables. Under AWS Glue databases, select the name of the database for the Cleanse or Consume bucket.
Data Catalog databases in the Cleanse layer will follow the naming convention of the Collect bucket layout. Databases in the Consume layer will follow the same convention but have the
_consumesuffix appended.- Select the radio button to the left of the table you want to profile.
- Check the dataset name to make sure it complies with the allowed characters.
- Scroll to the bottom of the page and choose
Create dataset. - You will now return to the Datasets screen; select the checkbox to the left of the dataset you just created.
- Select
Run data profile. - Select
Create a profile job. - Customize the Data Sample selection (choose full dataset or adjust the sample size).
- In the Job output settings section, use the Browse button to select the Glue Temp bucket following the naming convention
s3://dev-insurancelake-<AWS account ID>-<region>-glue-temp. - Append a suffix: profile-output/
- This will create a folder inside the bucket and save results in the folder.
- Expand Data profile configurations and select
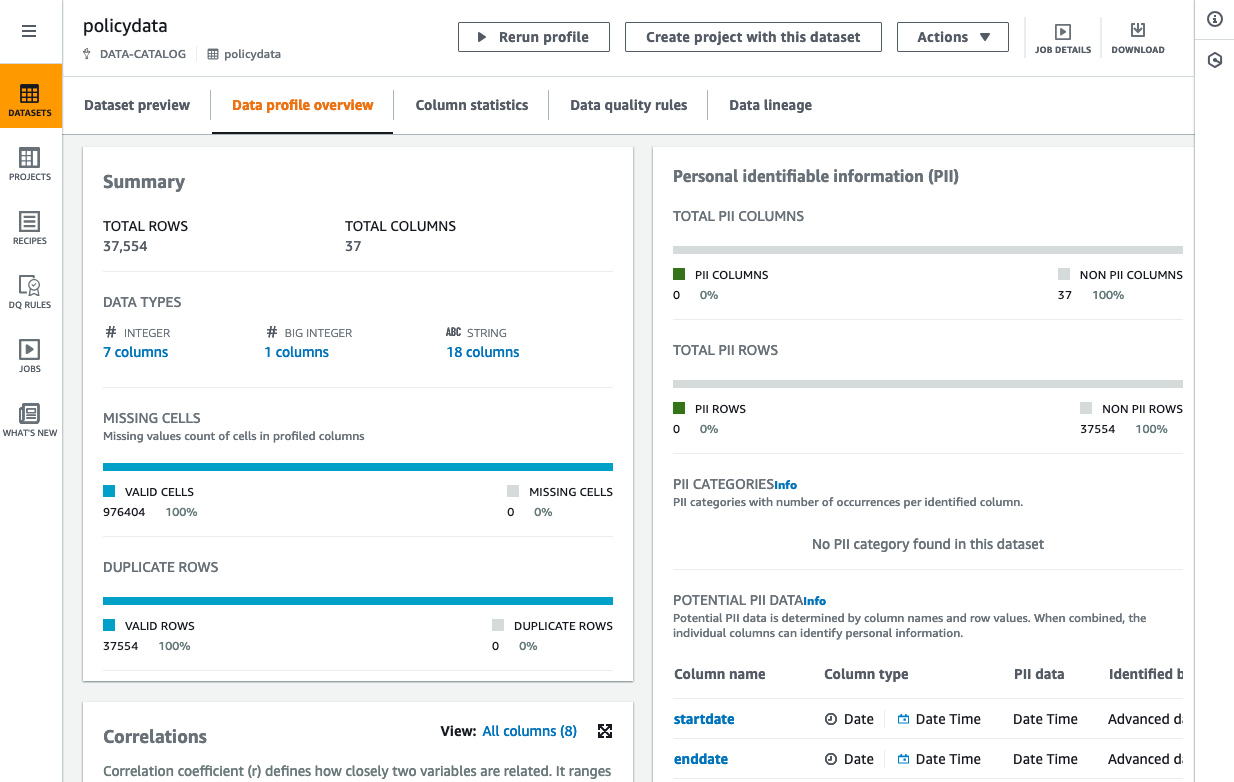
Enable PII statisticsto identify personally identifiable information (PII) columns when running the data profile job. Under PII categories, select any categories you wish to check.
This option is disabled by default due to its impact on time and cost; you must enable it manually before running the data profile job.
Take note of PII categories with a red dot to the right of the name; the dot indicates a significant impact on time and cost.
- Keep the remaining settings at their default.
- In the Permissions section, choose
Create new IAM rolefrom the Role name dropdown. Enter
Profileras the role suffix.This creates a new IAM role called AWSGlueDataBrewServiceRole-Profiler.
- Select
Create and run job.
This will take you to Data profile overview tab for the selected dataset. It will display a job in progress while running. Once the job finishes, you may observe the profile output, including statistics and identified PII rows and columns.
File Format Identification
This section describes file format considerations when loading data for the first time.
Auto Detection Formats
The ETL can load many source file formats for the first time with no configuration (in other words, no schema mapping file, no input/transformation specification file, no data quality file, and no SQL files). We recommend using this minimalistic configuration approach whenever possible, because it reduces the time to load and publish data.
Comma Separated Value (CSV) is the default file format for the ETL. If no other file format is identified or configured, the ETL will assume the file is CSV.
The table below lists the formats that could require no configuration for initial loading (with exceptions noted). Follow the provided links in the table for details on configuration options.
| Format | Exceptions |
|---|---|
| CSV | The ETL will default to using the first row of a CSV file as the header, " as the quote character, and " as the escape character. To change these options, you must provide an input_spec configuration. Other Spark CSV read defaults affect the way the ETL interprets CSV files. Refer to the Spark CSV File Data Source Option Documentation for details. |
| Parquet | Parquet files that do not end with a parquet extension will need to be renamed or you must provide an input_spec configuration indicating the file format. Multi-file Parquet data sources will require pipeline customization detailed in Handling Multi-file Data Sets. |
| Excel | Excel files are identified by the extensions xls, xlsx, xlm, xlsm. Loading Excel files requires the installation of the Spark Excel libraries. In addition, the ETL will default to using the first sheet in an Excel workbook, the data at cell A1, and assume the first row of data is the header. If your Excel file has data on a different sheet, in a different position, has no header, or requires a password, you must provide an input_spec configuration. |
| JSON | JSON files are identified by the extensions json, .jsonl. The ETL will default to loading JSON files as JSON Lines (each line contains one JSON object). If your JSON file uses multiple lines for a single object, you must provide an input_spec configuration. |
| XML | XML files are identified by the extension xml. Loading XML files requires the installation of the Spark XML driver. XML files must be row-based data. The ETL will default to a row tag of row. If your XML data uses a different row tag, you must provide an input_spec configuration. |
Other formats require some configuration, even for the first load.
TSV, Pipe-delimited, Other Delimiters
The ETL will not attempt to detect source data files containing Tab Separated Values (TSV), pipe (|) delimiters, or other delimiter characters. If your source data file uses a delimiter other than commas, you must specify an input_spec configuration indicating the file format (and optionally whether there is a header). Refer to the Pipe-delimited file format documentation and TSV file format documentation for configuration details.
Fixed Width
With no configuration, the ETL will load fixed width data files as single column data sets. In order to load the source data with multiple columns, you must specify the field widths using the schema mapping configuration file. Refer to the Fixed Width File Format Schema Mapping Documentation for details on how to do this.
Corrupt Data
When loading source data, you will likely encounter files with some corrupt rows of data. Examples of corruption include missing columns (such as a totals row), text in numeric columns, shifted columns, and unrecognized encoding for characters in a field.
Corrupt data in source data files can cause unexpected behavior with Spark’s ability to infer schema types and with performing required aggregate operations, such as a summation of a numeric column. To work around these issues and make your data pipeline more resilient, we recommend using data quality rules to quarantine corrupt data or interrupt the pipeline. Configuration details can be found in the Data Quality with Glue Data Quality Reference.
The table below shows an example data set with a totals row that causes schema problems:
| CoverageCode | EffectiveDate | WrittenPremium |
|---|---|---|
| WC | 2024-01-01 | 50000 |
| Auto | 2024-02-01 | 2500 |
| Total | 52500 |
The value of Total in the EffectiveDate column will cause Spark to infer a field type of string, which is not desirable. If you simply use a date transform to convert the field type, Spark will convert the value Total to null, and you will be left with an extra $52,500 of written premium. To work around this issue, you can use one of two methods:
Method 1
This method uses a before_transform data quality rule to quarantine the row of data with the value Total in the EffectiveDate column. The data quality rule identifies the row by looking for values that match a standard date pattern, and removing rows that do not match. Because the before_transform rule runs before transforms, you can next use a date transform to convert the clean column of data to a date field type.
dq-rules configuration:
{
"before_transform": {
"quarantine_rules": [
"ColumnDataType 'EffectiveDate' = 'DATE'"
]
}
}
transformation-spec configuration:
{
"transform_spec": {
"date": [
{
"field": "EffectiveDate",
"format": "yyyy-mm-dd"
}
]
}
}
Method 2
This method uses a filterrows transform to remove the row of data with the value Total in the EffectiveDate column. The filterrows condition looks for null values in the CoverageCode column, and filters out those rows. Because the filterrows transform occurs first in the transfom_spec section, you can next use a date transform to convert the clean column of data to a date field type.
transformation-spec configuration:
{
"transform_spec": {
"filterrows": [
{
"condition": "CoverageCode is not null"
}
],
"date": [
{
"field": "EffectiveDate",
"format": "yyyy-mm-dd"
}
]
}
}
Building Dependent Workflows
Consume level views will often bring together tables from multiple workflows using a Join or Union. If you run a multi-table view workflow when one of the referenced tables does not exist, your workflow will cause an error. If workflows have not updated one table, and another workflow joins to it, you may have missing rows (inner join) or rows with empty values (outer join). In both situations you have one workflow that depends on another.
In practice your workflow likely does not need to be tolerant of non-existent dependent table schemas: this is only a problem when building a workflow for the first time, or when promoting a workflow to a new environment. However, your workflow may need to be aware of data freshness for runs beyond the first.
To reach a more targeted solution, we recommend separating the problem of non-existent dependent tables from the problem of managing data freshness within dependent tables.
Scenarios and workarounds for non-existent dependent tables
| Scenario | Workaround |
|---|---|
| You are building a set of workflows for the first time and do not want an error. | First, configure all tables for the Cleanse layer† only so that their schema is created. Second, add the Consume layer SQL for all tables‡ and rerun workflows (for example, using Step Functions New Execution capability). |
| You are promoting an already-built set of workflows to a new environment. | Promote the workflow configuration after the building the Cleanse layer tables, then promote again when you add the Consume layer SQL. |
Copy the Cleanse layer table schema between environments in Athena using SHOW CREATE TABLE or Generate table DDL from the Athena console§, then promote the workflow configuration. |
†Configure Cleanse layer tables using input configuration, transform specification, schema mapping, and data quality Rules. Review the Location of Configuration Files table for more details.
‡Configure Consume layer tables using Spark and Athena views. Review the Location of Configuration Files table for more details.
§In Athena, click the vertical ellipsis to the right of the table name in the schema browser side panel. Select Generate table DDL, which runs a SHOW CREATE TABLE command. Copy and paste the query results into the editor window. Update the S3 bucket name in the LOCATION parameter to reference the consume bucket. In the side panel, change to the database with the _consume suffix, and execute the query.
Scenarios and workarounds for data freshness dependencies
| Scenario | Workaround |
|---|---|
| Your dependent tables update at different frequencies and you want to ensure that the Consume layer views always have the latest data. | Create multiple identical copies of the Consume layer SQL†, renamed for each dependent workflow, so the views are refreshed any time any of the dependent tables are updated. |
| Your dependent tables update inconsistently and you want to ensure that the Consume layer view only updates when dependent tables have fresh data. | Use Data Freshness checks to halt workflows or trigger alerts when dependent data is stale. |
| You do not want to initiate an AWS Glue job execution if dependent tables have stale data due to cost, performance, or a concern about excessive failure notifications. | Workflow dependency management and scheduling requires customizing InsuranceLake ETL AWS Glue job execution with services such as Amazon EventBridge Schedules or AWS Glue Triggers using a Schedule. |
†Consume layer views include both Spark and Athena SQL files. For more details, refer to Cleanse-to-Consume SQL Usage.
Execute Pipeline without Upload
If local development is not desirable or possible (for example, access to AWS account through API is restricted or testing of data quality rules is needed), you will need a method to rapidly iterate through additions, improvements, and fixes until you reach your desired state.
Using the Start Execution capability of Step Functions on historical executions allows you to quickly iterate through schema mapping, transform specification, data quality rules, and SQL changes when working with data in development. This method will ensure you replace the data in the original partition and skip the S3 file upload.
- Navigate to Step Functions in the AWS Console.
- Select the ETL State Machine which follows the naming convention
<environment>-insurancelake-etl-state-machine. - Click on a prior execution for the workflow you want to rerun, which will open the detailed view.
- Click
New Executionat the top of the screen.
- Inspect the execution parameters to ensure you are loading the correct source file with the correct partition values.
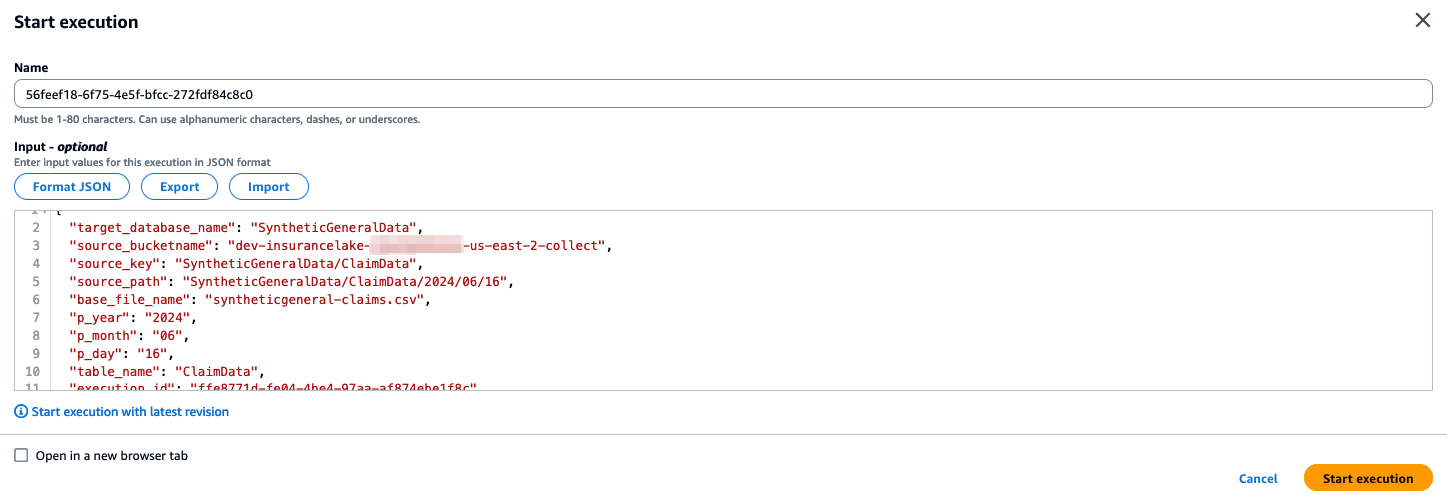
- Optionally edit the execution name to something easier to identify in the execution history.
- Click
Start Execution.- The new execution detail will automatically open in the AWS console.
Using this procedure allows overriding of the partition parameters in the Start Execution modal form. Simply edit the JSON formatted input parameters for
year,month, andday.Step Functions execution history entries are kept for 90 days after the execution is closed. Refer to the Step Functions AWS Documentation on Service Limits for the most current details.
Override Partition Values
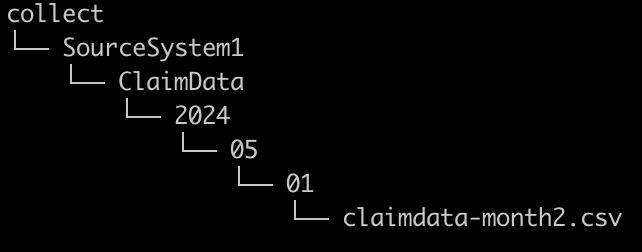
For historical data loads or replacing an existing partition with new data, the InsuranceLake ETL supports defining partition values in the folder structure of the Collect bucket.
Specifically, within the table level (second level) folder, you can create a folder representing the year partition value, another folder representing the month partition value, and another folder representing the day partition value. The source data file can then be landed in this nested folder structure and folder names will override the values from the created date of the Collect S3 bucket source file.
When you override partition values, keep in mind the behavior of the ETL loading data in the Cleanse and Consume layers.
Example bucket layout with partition value overrides follows:
If you’ve made changes to the Collect to Cleanse AWS Glue job in order to support multi-file Parquet data sets, the partition value override functionality may be disabled. More details can be found in the Handling Multi-file Data Sets Documentation.
Other methods to override partition values are covered in other sections of the documentation:
Using the Step Functions New Execution capability, a pipeline maintainer can repeat a previously completed workflow, skipping the file upload step, and override execution parameters such as partition year, month, day, and source file S3 location.
AWS Glue jobs can be manually executed with override parameters for individual AWS Glue jobs. For details on how to manually initiate AWS Glue jobs and override parameters, review the InsuranceLake Developer Documentation on AWS Glue Jobs.