Guidance for Streamlining Data Access with Jira Service Management and Amazon DataZone
Summary: This implementation guide shows how to streamline data access with Jira Service Management and Amazon DataZone. It includes an architecture diagram, its components and considerations for planning the deployment, and configuration steps for deploying this using Amazon Web Services (AWS). This guide is intended for solution architects, business decision makers, DevOps engineers, data scientists, and cloud professionals who want to streamline data access management through Amazon DataZone and Jira Ticketing Systems.
Get started
Summary: This implementation guide details how to streamline data access with Jira Service Management and Amazon DataZone. AWS customers using Amazon DataZone often want notification mechanisms outside of the Amazon DataZone portal that allow the data producers to quickly answer data subscription requests coming from data consumers. This Guidance provides a way for customers to extend the ‘publish and subscribe’ workflow of Amazon DataZone to external workflows, including the Atlassian Jira service management ticketing systems. This Guidance can also be extended to add new external workflows.
Guidance Overview
AWS customers who are actively building their data management platform on Amazon DataZone do so for the purpose of achieving effective governance over their data lakes and data warehouses. Amazon DataZone provides a subscription workflow that enables the abstract management of the underlying permissions when sharing access to data. As described in the “Publish & subscribe workflow” figure below, data producers can use the Amazon DataZone portal to request access for a project to a data asset published in the data catalog. Data consumers can then accept or reject this request. If accepted, all the members of the requesting project will be able to access the requested data asset and use it to create business value by building new use cases. Amazon DataZone is responsible for conferring the necessary IAM and AWS Lake Formation permissions (in the case of data lakes), as well as the requisite data share permissions (in the case of data warehouses), to the requesting project.
Some customers have already established standardized approval workflows using issue tracking systems such as Atlassian Jira. These customers want to use issues (some call it “tickets”) to track permission requests. Therefore, they want to integrate Amazon DataZone subscriptions with their issue tracking systems for the following reasons:
- Enhance efficiency by consolidating the request management process within a single, familiar interface. This eliminates the need to navigate to the Amazon DataZone portal separately.
- The ability to reassign Jira issues to other data access approvers.
- Streamline the data access process by automatically receiving email notifications from Jira regarding status changes of issues, as well as the capability to communicate through commenting on the issues.
The purpose of this Guidance is to help customers streamline data access permissions by integrating with external workflows like Jira Service Management by Atlassian.
This Guidance is built on top of an AWS Cloud Development Kit (CDK) and is designed to be an add-on for Amazon DataZone that is easy to deploy, extend, and customize. It is a fully automated, comprehensive approach for the data subscription lifecycle.
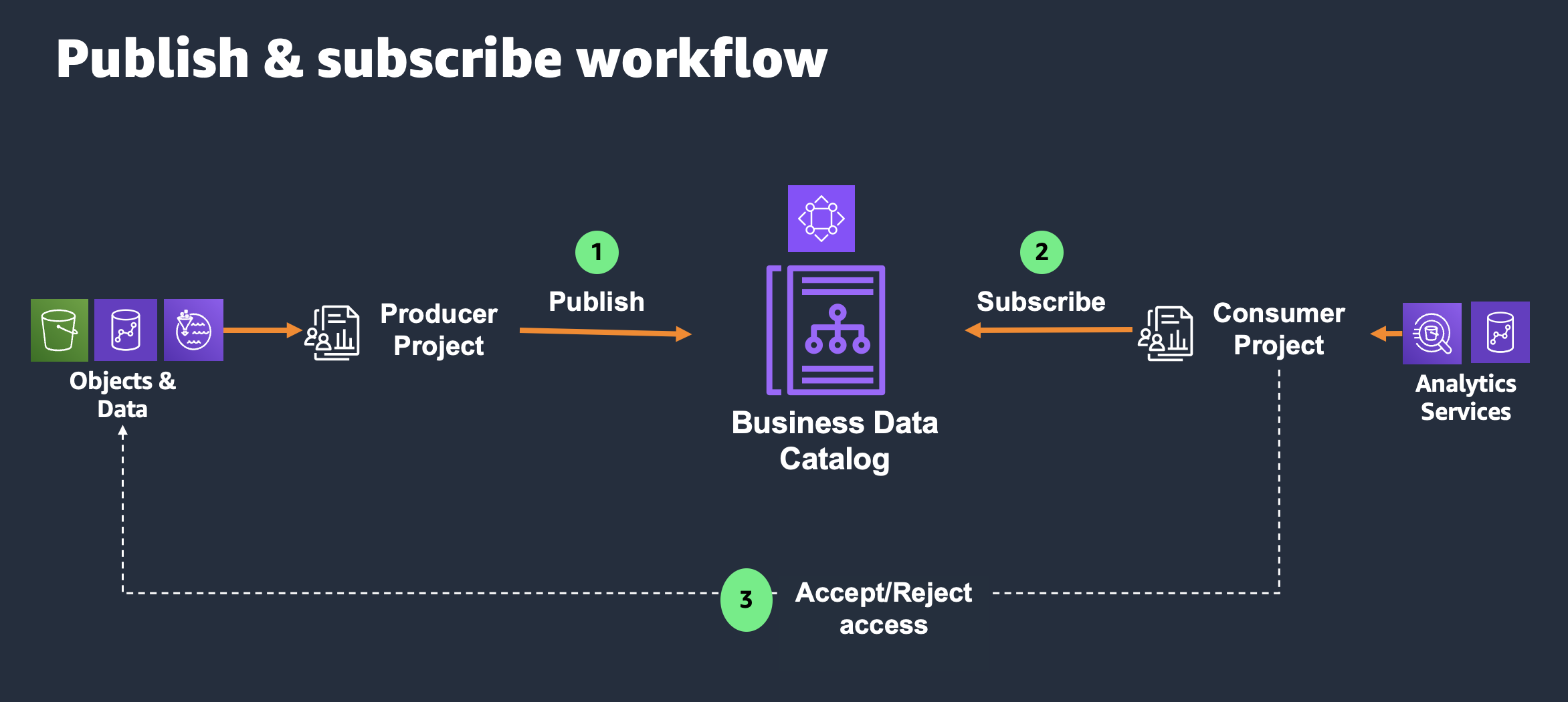
Figure 1: Publish-subscribe workflow
The integration described within this Guidance enables the automated creation of issues, as displayed in the image below, within an Atlassian Jira Project. Moving the issue to Accepted or Rejected will propagate this decision to Amazon DataZone, therefore granting access or rejecting the subscription request:
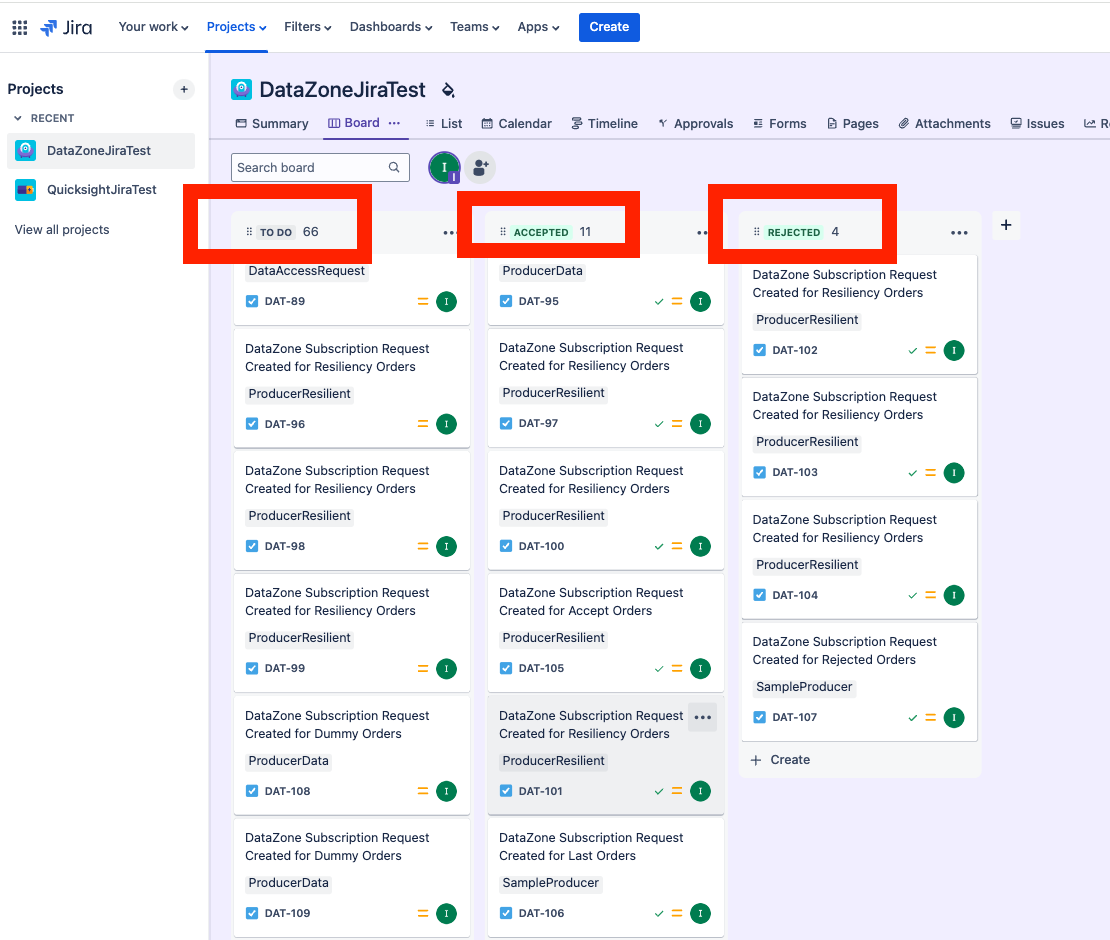
Figure 2: A sample Jira board
The following figure shows the data contained in the Jira issue:
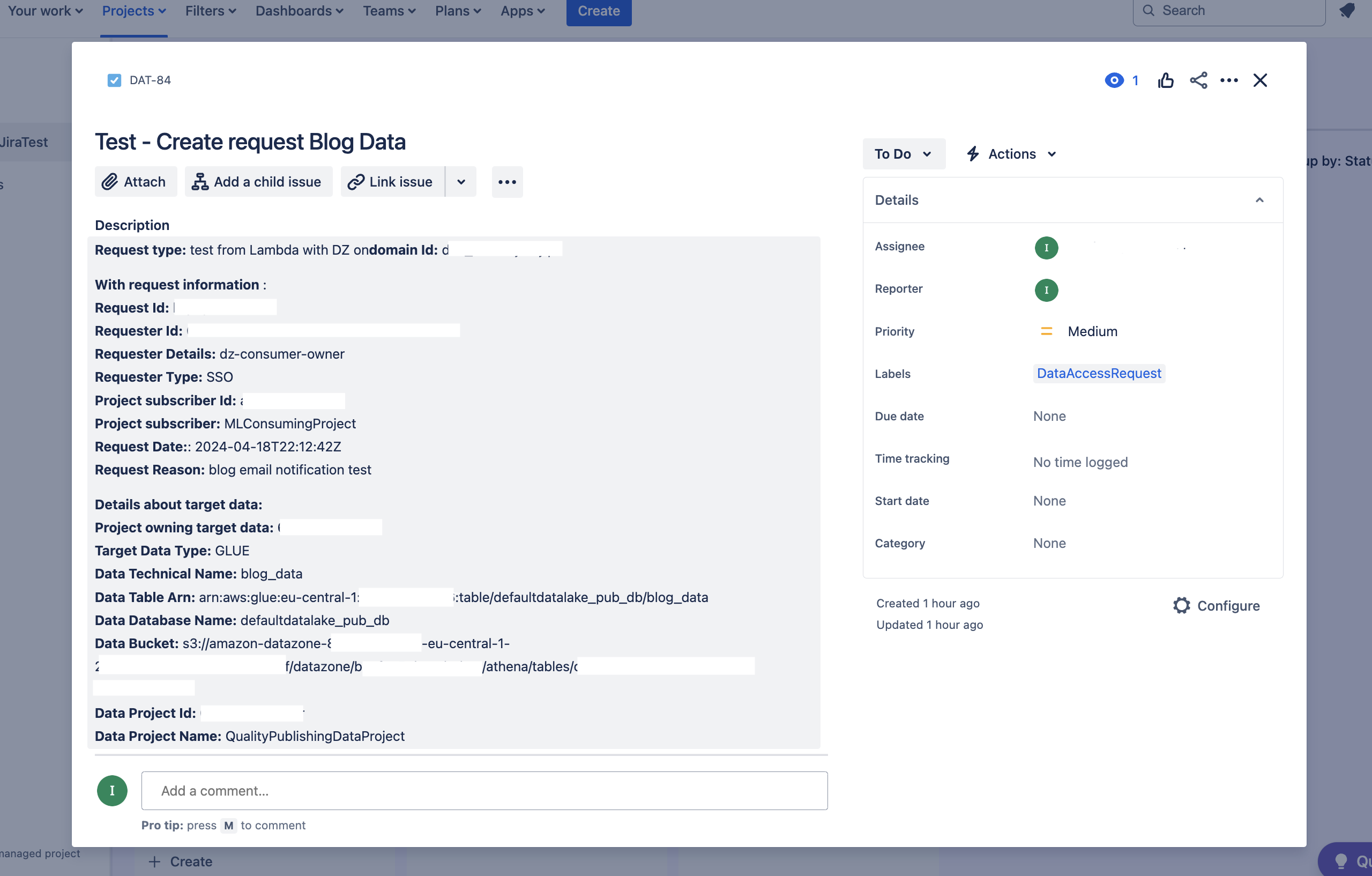
Figure 3: A sample Jira issue
Concepts and Definitions
This section describes key concepts and defines terminology specific to this Guidance.
Data asset
A data asset refers to a dataset that will be used as a means of collaboration between users and teams. Normally, it maps to a single table that can be hosted in a data lake, a database, or a data warehouse. A data asset can be classified in Amazon DataZone as Managed or Unmanaged. Managed data assets can have grants fulfilled automatically on any Amazon DataZone when a subscription to it is approved (including data assets hosted in Amazon S3 and Amazon Redshift). Unmanaged data assets cannot have grants managed automatically by Amazon DataZone, and there will be no attempts to do so.
Environment
Environments are an Amazon DataZone construct that allow users and teams that belong to the same Amazon DataZone project to publish their own data assets and to consume other projects’ published data assets with a granted subscription. This is the construct that enables users and teams to work with data when using Amazon DataZone.
Project
Amazon DataZone enables teams and analytics users to collaborate on projects by creating use case-based grouping of teams, tools, and data.
Producer
The producer is a role assumed by a user or a team in the context of data collaboration. The main goal of a data producer is to provide data that other users or teams can consume. This translates to “publishing” data assets in Amazon DataZone through an environment available to the user.
Consumer
The consumer is a role assumed by a user or a team in the context of data collaboration. The main goal of a data consumer is to consume data that other users or teams are producing. This translates to “subscribing” to data assets in Amazon DataZone through an environment available to the user and to query it through AWS Services like Amazon Athena and AWS Glue.
Subscription
A subscription in Amazon DataZone represents whether a consumer project has access to a data asset published by a producer. A subscription is created when a consumer submits a “Subscription Request” and is accepted by the producer. When a subscription is established, environments from the consumer project (whose profile is able to consume the data asset) will be added to the subscription as Subscription Targets. Note that Subscription Targets are associated only for Managed data assets. For Unmanaged data assets, no Subscription Targets are associated with the subscription.
Subscription workflow
A workflow is a set of steps that are executed through an orchestrated mechanism and as a result of a specific event that was initiated in Amazon DataZone. Workflows are orchestrated through AWS Step Functions, and each step can be executed through any AWS service. The current implementation uses AWS Lambda functions as initiators of steps in the workflows and is triggered by a subscription request.
Domain
You can use Amazon DataZone domains to organize assets, users, and their projects. By associating additional AWS accounts with Amazon DataZone domains, users can bring together their data sources. Users can then publish assets from these data sources to their domain’s catalog. Users can also search and browse these assets to see what data is published in the domain.
Secret
A secret is a resource construct of Amazon Secrets Manager used to store highly confidential values, such as database credentials. Secrets are used in this Guidance to store the credentials of the admin and token of the Jira project.
Refer to AWS documentation for more details.
Architecture Overview
The following figure shows the architecture diagram, illustrating the subscription workflow from a data access request on the Amazon DataZone portal to the update of its status through Jira.
Some components of the architecture are pre-requisites and not deployed by the CDK. To use the integration between Amazon DataZone and the Atlassian Jira management system, you need to:
- Create an Amazon DataZone domain.
- Create a set of consumer and producer projects for which you want to apply the workflow.
- Create an Atlassian Jira Project.
- Store Jira credentials in AWS Secrets Manager.
The workflow steps are:
- A consumer searches for a data asset in the Amazon DataZone portal and submits a subscription request to access a data asset.
- Amazon DataZone emits an event, which is then captured through an event rule in Amazon EventBridge. This event triggers the execution of an AWS Step Functions target.
- Step Functions adds tasks to an Amazon Simple Queue Service (Amazon SQS) queue.
- The Lambda function Create Get Issue polls a task from the Amazon SQS queue and subsequently creates content for the Jira issue based on the captured event.
- The Lambda function Create Get Issue gets Jira credentials from AWS Secrets Manager and creates the issue in the Jira project.
- Producers change the status of the issue in the Jira project board to status Accepted or status Rejected.
- Step Functions triggers the Lambda function Create Get Issue to retrieve the status of the issue and waits for the status to change. Once the status changes, Step Functions triggers the execution of the Lambda function DataZone Subscription Update.
- The Lambda function DataZone Subscription Update assumes an AWS Identity and Access Management (IAM) role that is a member of an Amazon DataZone project of the target data.
- The Lambda Function DataZone Subscription Update communicates with Amazon DataZone to update the status of the subscription request.
- If the status of the issue in Jira was changed to Accept, the consumer accesses the data.
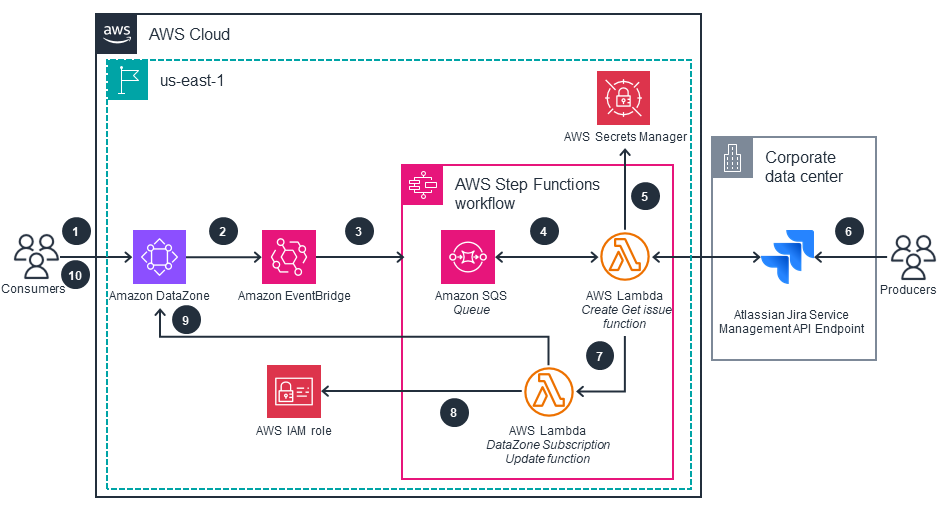
Figure 4: Reference architecture
AWS Well-Architected framework
This Guidance uses the best practices from the AWS Well-Architected Framework. It helps AWS customers design and operate workloads in the cloud that align to best practices for Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability. This section describes how the design principles and best practices of the Well-Architected Framework can help users become well-architected when configuring this Guidance.
Operational excellence
This Guidance uses a combination of Amazon DataZone, Step Functions, Lambda, AWS X-Ray, and an AWS Cloud Development Kit (CDK) for operational excellence.
First, Amazon DataZone simplifies data management for end users as well as operations. It provides the functionality to handle user authentication and data access at scale without the need for fine-grained permission management. It also offers the data portal, a web application for managing data assets, so users do not need to build a custom framework. It is a managed service without the need to manage individual EC2 instances. Second, Step Functions and Lambda are serverless and eliminate the need for managing compute infrastructure, reducing operational complexity. Third, AWS X-Ray helps users to gather deep insights into request processing, simplifying troubleshooting. Fourth, the CDK automates deployment of this Guidance into any target AWS account, and it can be integrated with any continuous integration and continuous delivery (CI/CD) toolchain that you use.
Security
This Guidance uses AWS Identity and Access Management (IAM) to implement the principle of least privilege. Every AWS service call implemented in this Guidance uses a custom IAM role with the minimum permissions necessary. Amazon DataZone simplifies user and data access management, thus eliminating the need for fine-grained configuration and reducing the potential of security-related configuration errors. It integrates with IAM Identity Center for users to reuse an existing corporate directory and single-sign on (SSO).
This Guidance also uses AWS Secrets Manager to store credentials for communicating with an Atlassian Jira instance. When communicating with Jira, it uses token authentication and HTTPS to ensure encryption in transit.
Reliability
Amazon DataZone is a managed service that uses the global AWS infrastructure to provide high availability. Amazon DataZone offers additional features to help support data resiliency and backup needs. Refer to Resilience in Amazon DataZone for more information.
This Guidance additionally uses Step Functions, Lambda, Amazon EventBridge, and Amazon SQS which are serverless AWS services. They help ensure high availability at a Regional level by default. Specifically, we use the combination of Lambda and Amazon SQS to implement resilience when communicating with the Jira instance.
Performance Efficiency
This Guidance integrates with Amazon DataZone, which is purpose-built for data management. Step Functions and Lambda provide lightweight compute capabilities, and they are ideal for modelling custom subscription workflows. This Guidance also deploys Lambda and Step Functions in the same Region as the Amazon DataZone assets to help ensure low latency.
Cost Optimization
Amazon DataZone ensures that you can set up a new data mesh within days rather than months. Step Functions, Lambda, EventBridge, Amazon SQS, and Secrets Manager are serverless AWS services, so you only pay for what you use. The subscription workflow state is maintained in AWS Step Functions and Amazon SQS instead of using EC2 instances and databases.
Sustainability
Amazon EventBridge, Step Functions, Amazon SQS, and Lambda eliminate the need for persistent storage or always-on EC2 instances, because compute resources are only used on demand and state is maintained within Step Functions and Amazon SQS. All of these services are serverless, so they scale as needed in relation to the current load on your system.
Guidance Components
In this section, we describe the architecture of this Guidance in more detail.
Amazon DataZone domain
This Guidance needs an existing Amazon DataZone domain in the target account as a prerequisite. You configure the domain ID when deploying this Guidance.
Amazon DataZone subscription workflow event
Amazon DataZone sends events to the account where the Amazon DataZone domain resides for all managed events (actions performed in the Amazon DataZone domain) and CloudTrail events (Amazon DataZone API calls).
Here is a sample event:
{
"version": "0",
"id": "28c794a8-265a-ba20-a5ed-e0562abd4cbf",
"detail-type": "Subscription Request Created",
"source": "aws.datazone",
"account": "12345678910",
"time": "2024-01-18T11:26:28Z",
"region": "eu-central-1",
"resources": [],
"detail": {
"version": "38",
"internal": "None",
"metadata": {
"id": "5tv5v6pjg3rqx7",
"version": "1",
"typeName": "SubscriptionRequestEntityType",
"domain": "dzd_cufc6djzvsjqff",
"user": "63744852-e091-70f8-76a6-2755fe774ff5",
"awsAccountId": "12345678910",
"owningProjectId": "aph16wal7pvdzf",
"clientToken": "aae736db-9553-43a3-988d-1bdf7b1276e8"
},
"data": {
"autoApproved": "False",
"requesterId": "63744852-e091-70f8-76a6-2755fe774ff5",
"status": "PENDING",
"subscribedListings": [
{
"id": "bnsuymo8kyqdfv",
"ownerProjectId": "6p9p76q6lg2bgr",
"version": "2"
}
],
"subscribedPrincipals": [
{
"id": "aph16wal7pvdzf",
"type": "PROJECT"
}
]
}
}
}
When a data consumer submits a subscription request (step 1 in the architecture), an event is triggered. This event is captured by an event rule (step 2) and is used to trigger a call to Step Function (step 3 in the architecture).
Step Functions then triggers the execution of a Lambda function responsible for parsing the event to get identifiers related to information about the subscription request from Amazon DataZone. It uses these identifiers to perform API calls to Amazon DataZone to retrieve detailed information needed to populate the content of the Jira issue. It reads the Jira API credentials from AWS Secret Manager and uses them to perform REST API calls to Jira instance endpoint to:
- Create an issue corresponding to the subscription request created in Amazon DataZone.
- Get the issue status.
Subscription Manager Role
This Guidance deploys a Subscription Manager role with IAM permissions to accept or reject subscription requests in Amazon DataZone. The “Subscription Update” Lambda function assumes this role in order to propagate the decision made in Jira to Amazon DataZone. In Amazon DataZone, projects enable a group of users to collaborate on various business use cases. Users must be a member of a project to be able to perform actions on the assets of this project. Users must be a project member to add members to a project. Refer to Add members to a project in Amazon DataZonen for more details on project membership. Therefore, users need to add the deployed IAM role as a member to Amazon DataZone projects where users want to enable automation.
Step Functions orchestration
AWS Step Functions is a serverless orchestration service. It allows users to coordinate multiple AWS services into serverless workflows and build scalable, fault-tolerant applications by defining state machines composed of steps, or states, that execute in a specific order. In this Guidance, we will demonstrate how to use Step Functions to orchestrate an approval workflow.
Step Functions is triggered after the event of the Subscription Request in Amazon DataZone is intercepted by the Amazon EventBridge rule. Users choose between two types of orchestration workflows:
- A Classic Workflow
- A Resilient Workflow
Classic workflow
The classic workflow uses polling to get the issue status from Jira.
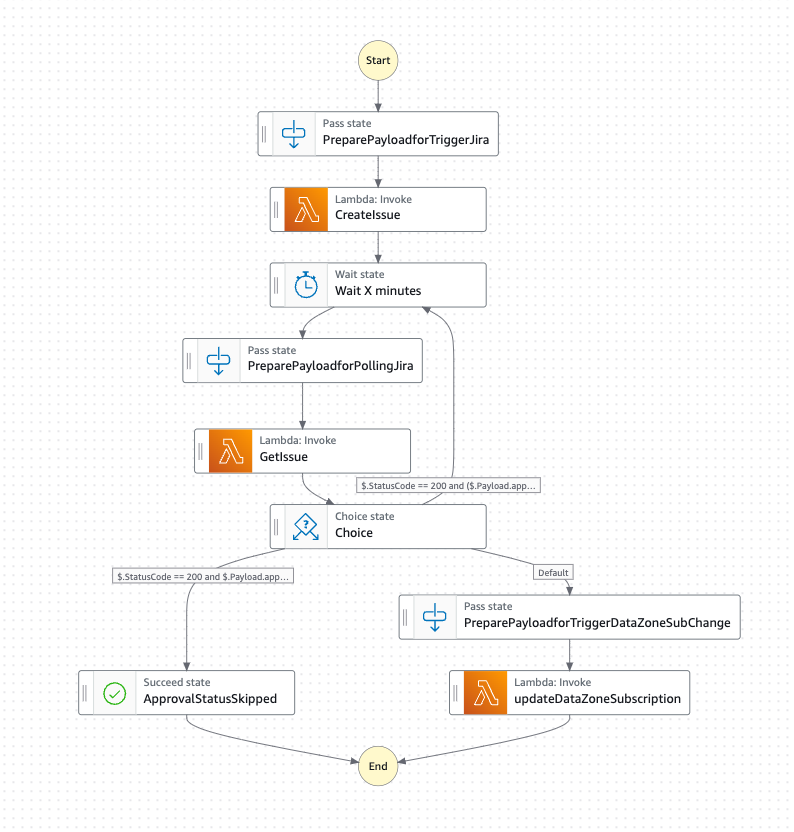
Figure 5: Classic workflow
The workflow involves the following steps:
- Trigger: The state machine is triggered by the creation of a subscription request in the Amazon DataZone portal.
- Invoke Lambda to Create Jira Issue: A Lambda function is invoked to create an issue in the corresponding Jira Project.
- Wait for Approval: The state machine then waits, and periodically retries to get the issue status from Jira. Users can configure the number of minutes for the wait time as an input.
Handle Approval or Rejection:
- If the issue is accepted, a second Lambda function updates the Amazon DataZone subscription request to grant access to the user for the desired dataset.
- If the issue is rejected, the subscription request status is updated to rejected by this Lambda function.
- If you are interacting with an external workflow that only receives notifications and does not respond with a status to change, it can return skipped in order to move Step Functions to a terminal state.
Resilient workflow
The resilient workflow uses Amazon SQS queues to provide better resiliency in communicating with Jira.
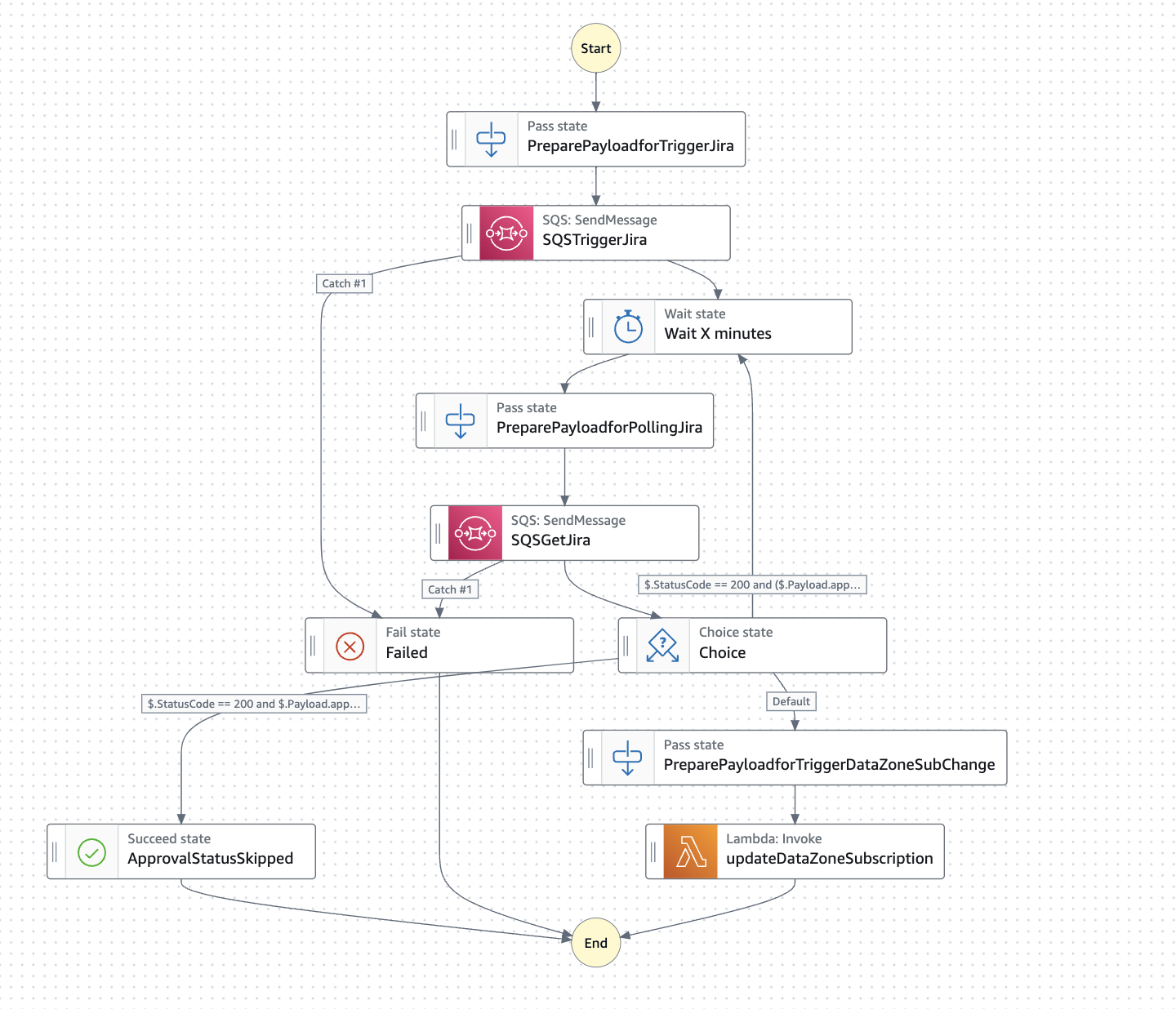
Figure 6: Resilient workflow
See the next section for a more in-depth description of this workflow.
Resilient Workflow Architecture
In this Guidance, considering a Jira instance on-premises, we often notice intermittent service outages while communicating with Jira. For example, network maintenance caused timeouts while accessing external urls. This caused a disruption in the workflow that required human intervention to fix and could lead to a negative user experience (UX). This is why we built a robust and resilient architecture for integrating Step Functions with external services like Jira. This utilizes Lambda, Amazon SQS, and resilient mechanisms like exponential backoff retries, rate limiting, dead-letter queues, and deduplication logic. Therefore, we reduce the impact of any temporary service disruptions for a smooth and efficient workflow for users.
The architecture supports a seamless handling of outages, throttling, and other issues while providing a better user experience and reducing operational overhead.
- A Step Functions workflow sends messages to an Amazon SQS queue, which is processed by a ‘singleton’ Lambda function.
- The Amazon SQS FIFO queue has content-based deduplication and spawns a single Lambda function. This queue is used to process messages in the order they are received. Lambda invocations that are throwing Jira related errors will be retried for a period of 24 hours, after which they will be sent to a dead-letter queue.
- Dead-letter queue: This queue is used to store messages that fail to be processed successfully. This can be due to various reasons, such as errors in the Lambda functions or network issues.
- The ‘singleton’ Lambda function allows users to limit requests, exponential back-offs, and message batch processing logic.
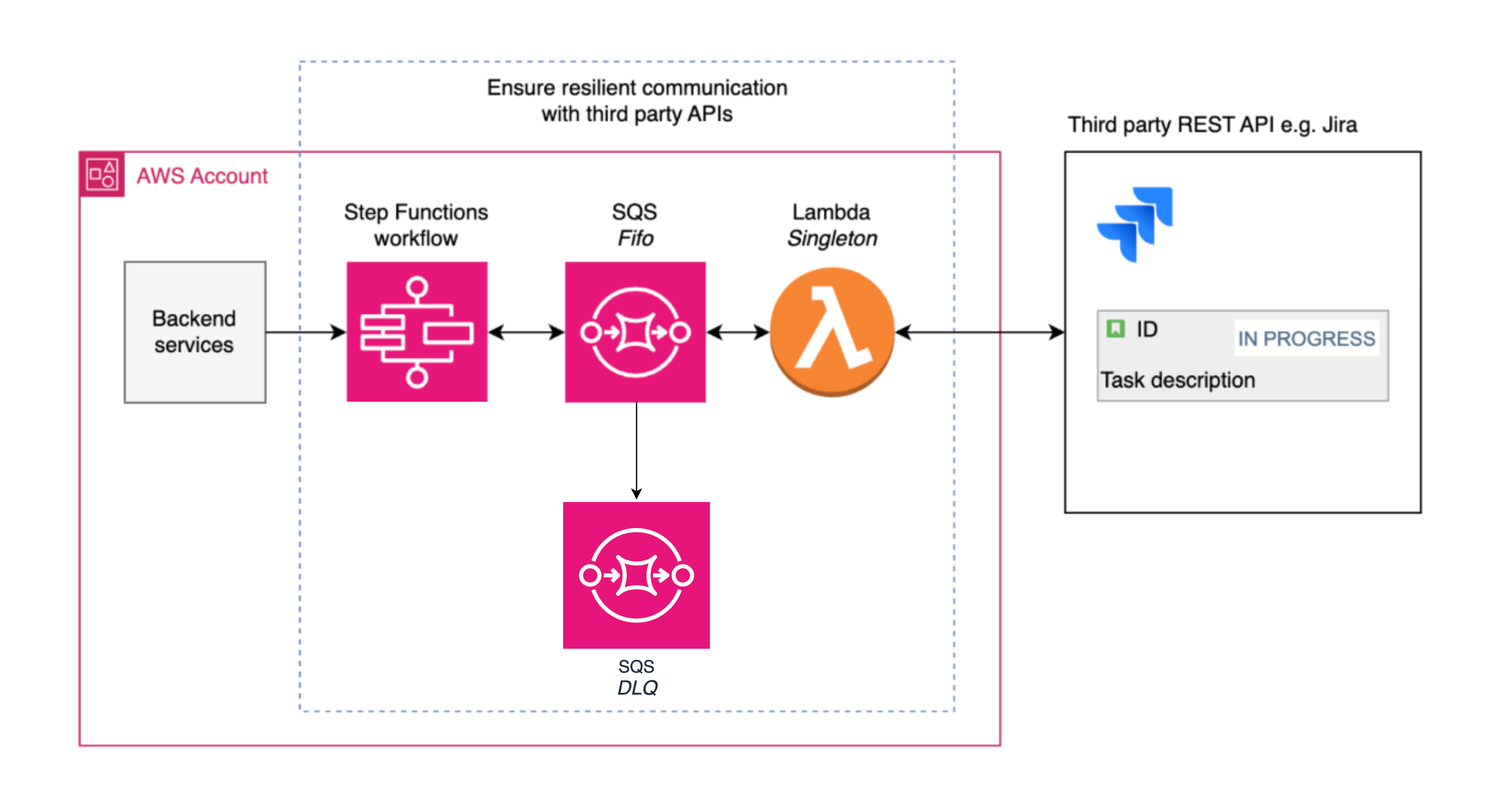
Figure 7: Resilience overview
Types of outages and how they are handled
API throttling
Services often use API throttling to limit the number of API requests a user can make in a certain period. Clients that exceed the allowed request rate limit can be temporarily blocked. If a Lambda function is used to talk to an API, then depending on the architecture, there is the risk of spawning a very large number of Lambda functions that then invoke the third-party API in parallel and exceed the request rate limit. Our pattern uses a single Lambda instance to communicate with the third-party API.
Service disruption or REST API error
REST APIs use error response codes to notify clients that something has gone wrong with the request. For example:
- 400 “Bad Request”
- 401 “Unauthorized”
- 500 “Internal Server Error”
The Lambda function handles these errors and either moves the error back into the queue or lets Step Functions know that it is a permanent failure.
General disruption
This can be any outage that has a negative impact on service. For example: an ongoing maintenance in an organization might suddenly cause traffic to slow down, causing a timeout while calling the third-party API. If the Lambda function notices a general error while communicating with the service, like a timeout, the Lambda function will first try to make requests to the service with exponentially increasing wait times or backoffs. The number of retries and the duration to wait before retrying can be configured within the Lambda function and is implemented using urllib3.
Sequence Diagram
This diagram illustrates how this Guidance manages the creation, polling, and updating of Jira issues in a reliable and scalable manner through AWS Step Functions. The diagram showcases three parallel executions of Step Functions, each with a different outcome:
- Purple Execution: Successful Jira Ticket Creation
- Green Execution: Internal Error (Unrelated to Jira Service)
- Yellow Execution: Jira Service Error (Jira Unavailable)
Purple Execution:
- Outcome: Successfully creates a Jira ticket.
- Details: Step Functions continues executing the remaining steps in the workflow as expected. No further error handling is needed.
Green Execution:
- Outcome: Internal error occurs when retrieving the status of the Jira ticket. This error is not related to the Jira service itself.
- Details: The Step Function detects the internal error and handles it accordingly. The message causing the error is removed from the queue since the error is not associated with the Jira service. Step Functions either retries or gracefully terminates, depending on the error handling logic implemented.
Yellow Execution:
- Outcome: Jira service error occurs while attempting to retrieve the status of the Jira ticket. The Jira service is unavailable.
- Details: Step Functions identifies this as a transient error related to the unavailability of the Jira service. In this case, the message is retained in the queue for up to 24 hours, during which retries will continue until the Jira service becomes available and the issue can be resolved. If the Jira service is still unavailable after the 24-hour retry window, the message is removed from the main queue and sent to a Dead-Letter Queue (DLQ). At this stage, human intervention is required to manually restart Step Functions with the same message once the Jira service becomes stable again.
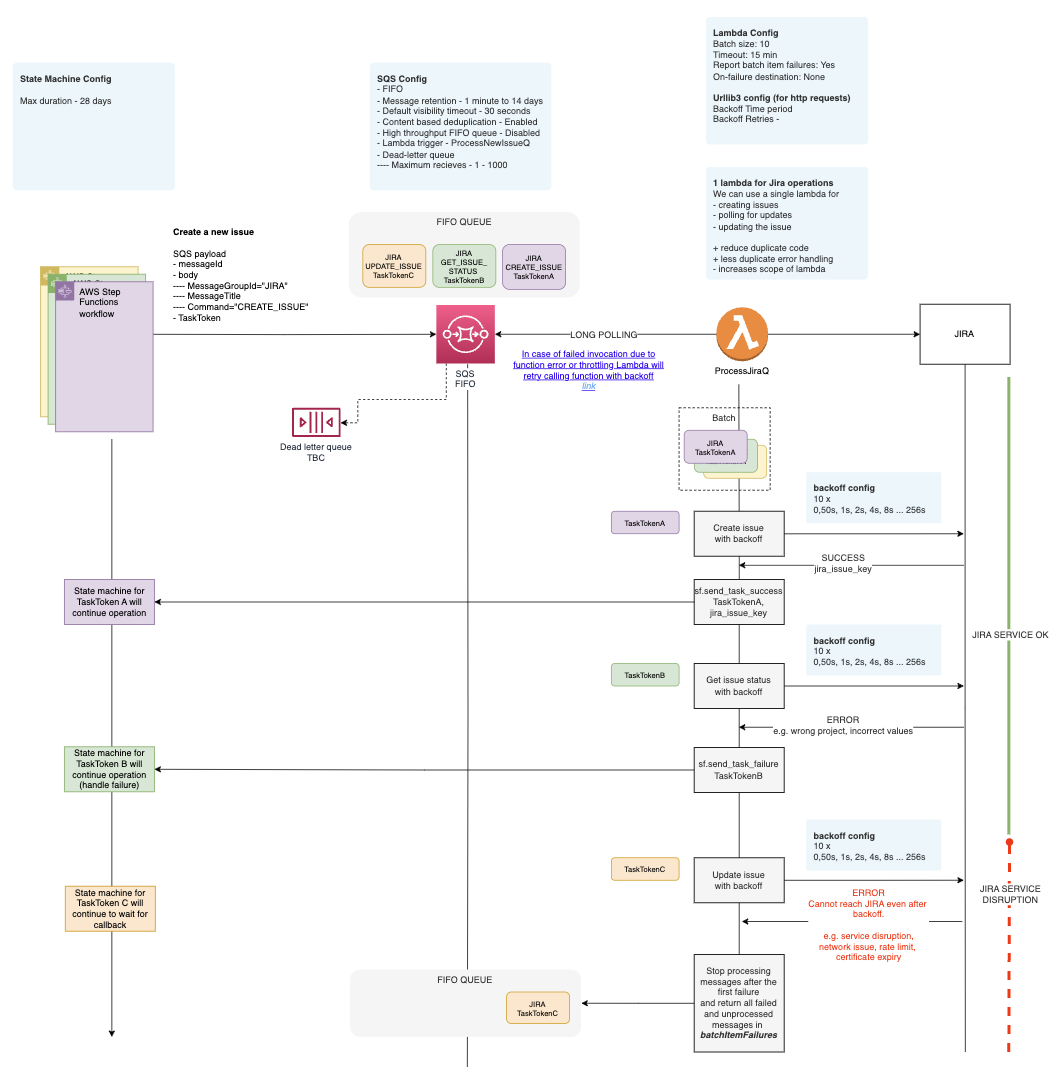
Figure 8: Resilience sequence diagram
Benefits of resiliency workflow:
- Scalability: The serverless components can scale automatically to handle varying workloads.
- Reliability: The use of Amazon SQS queues and retries helps ensure that messages are processed reliably, even in the case of failures.
- Cost-efficiency: The serverless model allows users to pay only for the resources they consume.
- Flexibility: The architecture can be easily modified to accommodate changes in requirements.
Plan your Deployment
This section describes the cost, security, AWS Regions, and other considerations prior to deploying this Guidance.
Cost
Users are responsible for the cost of the AWS services used while running this Guidance. As of this revision, the cost for running this Guidance with the default settings in the US East (N. Virginia) Region is approximately $16.33 per month. These costs are based on the resources shown in the sample cost table. We recommend creating a budget through AWS Cost Explorer to help manage costs. Prices are subject to change. For full details, see the pricing webpage for each AWS service used in this Guidance.
Sample Cost Table
The following table provides a sample cost breakdown for deploying this Guidance with the default parameters in the US East (N. Virginia) Region for one month. The estimate presented below assumes the following usage pattern:
- Number of users: 20,000
- Number of data assets: 7,000
- Number of requests for data asset access per user per month: 3
- Number of AWS Step Functions executions per month: 60,000
- Number of steps per execution: 6
- Average execution time of AWS Lambda functions: 2 seconds
- Number of AWS Lambda invocations per month: 120,000 (60,000 for each function)
- Memory allocated to each Lambda function: 128 MB
Each customer has its own specific usage pattern driven by the number of users, data assets, and the frequency of access requests.

Figure 9: Price estimate
Summary
The estimated monthly cost for deploying this Guidance with the parameters and usage patterns outlined is $16.33 per month. The costs are primarily driven by Step Functions and CloudWatch Logs usage. Additional costs could be incurred based on specific configurations or usage beyond the assumptions made in this estimate.
This estimation should be used as a baseline, and customers are encouraged to review their specific usage patterns and adjust accordingly.
Security
When you build systems on AWS infrastructure, security responsibilities are shared between you and AWS. This shared responsibility model reduces your operational burden because AWS operates, manages, and controls the components, including the host operating system, the virtualization layer, and the physical security of the facilities in which the services operate. For more information about AWS security, visit AWS Cloud Security.
When building this integration between Amazon DataZone and Atlassian Jira, we applied security best practices to secure the application-level resources and configurations.
IAM Roles and Permissions:
- IAM roles are used to grant the necessary permissions to the Lambda function that interacts with Jira, Amazon DataZone, Amazon SQS, and AWS Secret Manager. The trust relationship of the IAM role is restricted to only allow Lambda functions to assume the roles, preventing unauthorized access.
- IAM policies are created following the principle of least privilege, granting only the required permissions to the IAM roles. Wildcards (“*”) are avoided in the actions and resources clauses.
Secrets Management:
- All sensitive information, including the Jira API credentials, is stored in AWS Secrets Manager.
- Sensitive information is not logged in custom code before or after being retrieved from Secrets Manager.
- The resource-based policy is restricted to only allowing the Create Get issue Lambda function.
- We advise using a secret rotation in Jira and updating the secret in AWS Secrets Manager at a certain interval to limit exposure.
AWS KMS:
- AWS Key Management System (AWS KMS) keys are used to encrypt any sensitive data, such as Jira API credentials stored in AWS Secrets Manager and messages in Amazon SQS.
- Automatic AWS KMS key rotation is not enabled unless there is a strict regulatory or compliance requirement.
- AWS KMS-related events are monitored through AWS CloudTrail.
By implementing these security controls, this Guidance is designed to mitigate the identified threats and protect the confidentiality, integrity, and availability of the Amazon DataZone subscription workflow and the associated data.
In-Transit encryption
All communication between the Lambda function and the Jira API endpoint is encrypted using TLS, protecting data in transit from eavesdropping or man-in-the-middle attacks. For a private instance of Jira, users need to make sure to add a certificate. Details specified in Deploy The Guidance and then Configure Jira authentication.
AWS Lambda
No external dependencies: The Lambda function code does not include any external dependencies, reducing the risk of vulnerabilities in third-party libraries.
Jira Service Management configurations recommendations
The issues created when configuring this Guidance have a label corresponding to the project name of the requested data. To ensure the principle of least privilege, define access restrictions in the Jira project.
Advice for Securing Jira Issue Approvals:
- Give consumers permission to comment on the Jira issues to allow monitoring and oversight.
- Configure the Jira project admin to create:
- One group per data producer project and create transition conditions that only allow the group corresponding to the label to perform transitions. Refer to Error adding service for more details.
- Automation rules to automatically assign issues to members of the appropriate group based on the label. This approach prevents having a single bottleneck approver. Refer to Auto Assign Ticket Based on Label for more details.
Advice for Protecting Jira Credential Integrity:
- Regularly rotate the Jira API credentials by generating new API tokens.
- Restrict the permissions of the Jira credentials to the minimum required. The API token acts as a replacement for a users’ password in API requests. This means that the API token has the same permissions as a users’ Atlassian account with which they have generated the token. Users can create a dedicated Atlassian account with restricted permissions and generate the API token from that account.
Advice for Securing the Lambda Function and the AWS environment:
- Disable ClickOps operations with the Lambda function in a production environment.
- Ensure the AWS account where this Guidance is deployed follows the principle of least privilege, granting only the necessary permissions to the IAM roles and resources involved.
Networking considerations
This Guidance does not deploy any networking resources. It is intended to be deployed on top of the user’s current networking setup. This Guidance assumes that the user’s Jira instance is reachable through a public endpoint. If the Jira instance is in a private network, users need to ensure that their networking setup allows reachability between a create get issue Lambda function and their Atlassian Jira instance. If users want to set up a private connectivity between their on-premises Jira instance and Lambda, they can set up an AWS PrivateLink and virutual private cloud (VPC). Refer to Connecting inbound interface VPC endpoints for Lambda for more details.
DevOps considerations
This Guidance does not include a DevOps tool selection. It is an AWS CDK approach that can be deployed using any CI/CD tool (AWS native or third-party). One of the key points here is to deploy the custom part of this Guidance separately from the Amazon DataZone main stacks, which means that there are separate stacks with their own lifecycle.
Note: One of the approaches used previously in over 100+ deployments for CI/CD is the CDK CICD Wrapper.
It is important to understand the deployment steps, considering that this Guidance does not cover a fixed number of accounts when deployed in a multi-account setup. Each account deployment should be parametrized with account-specific resources, such as domain ID and project IDs. DevOps teams can use AWS X-Ray to dive deeper into troubleshooting with visualization.
Supported AWS Regions
This Guidance requires Amazon DataZone, which is currently not available in all AWS Regions. Refer to the AWS Regional Services List for current availabilities.
Where it is General Available (GA), Amazon DataZone domains can be provisioned in the following AWS Regions: US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (Stockholm), and South America (São Paulo).
Deploy the Guidance
This Guidance uses the AWS CDK command line interface (CLI) to automate the deployment of a project. It connects Amazon DataZone to an external service, like Jira, and orchestrates a subscription workflow where a user can accept or reject a subscription request. The application is parameterized and deployed to include account-specific resources. The entire deployment process takes approximately 5 minutes.
Prerequisites
General Configurations
- An AWS account (with an existing Amazon DataZone domain available)
- Bash or ZSH terminal
- AWS credentials and profiles for each environment under ~/.aws/config located CLI Configure Files
- Users must export
AWS_PROFILEandAWS_REGIONcontaining the AWS Account credentials where they will deploy Amazon DataZone. This is necessary to be present before performing any infrastructure deployment through an AWS CDK for the following:
* Python version >= 3.12 * AWS SDK for Python >= 1.34.87 * NPM >= v10.2.*
It is a prerequisite to create the following Amazon DataZone resources before using this Guidance:
1. Create an Amazon DataZone Domain - make sure to configure the ID of this domain in `DataZoneConfig.ts` when deploying this Guidance. Optionally, if users encrypt the domain with a customer managed key (CMK), they also need to configure the AWS KMS ID in the same file.
2. Create an Amazon DataZone Project.
3. Create an Amazon DataZone environment from where users want to publish data assets.
4. Publish at least one data asset.
It is also required to have an Atlassian Jira project with 3 statuses: To Do, Accepted, and Rejected.
Assuming that users have cloned the repository, they next run the following command to install the required dependencies:
npm install
Jira Prerequisites
- A Jira account.
- A Jira project within the account the users want to use to manage issues with statuses To Do, Accepted, and Rejected.
- A user with the appropriate permissions to manage issues.
Here is an example where Jira is on-premises and the project ID is DATAZN:
https://abc.xyz.com/jira/projects/DATAZN
Configure Jira authentication
Authentication mechanisms vary depending on how an organization is set up to use Jira. If a cloud instance of Jira is used, then a user + token is normally sufficient to authenticate. This Guidance has been tested with a Jira cloud instance for deployment and requires a user and a token to be configured in a secret in AWS Secrets Manager.
If an organization has its own Jira server, then users might additionally need a client certificate. Users can find in the code a placeholder in a comment where they can specify their client certificate (in jira_workflow.py, search for certificate authentication).
If there is a Jira instance running on-premises, here are the two steps required to configure access in such cases:
- Client Certificate - A client certificate was required to allow communication between the AWS account and the customer’s on-premises Jira service.
- A PKCS12 client certificate was generated by the customer and had a lifetime validity of 365 days.
- The certificate is stored in AWS Secrets Manager as a secret; for example: XYZ_JIRA_ClientCertificate
- The secret value was stored with the following format:
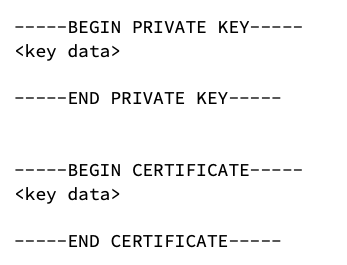
Figure 10: Jira certificate structure
- Jira Credentials
- Jira user - Create a user within the above project with the appropriate permissions to be able to create and update issues. Refer to Permissions Overview to understand Jira roles and permissions.
- API Token - Create an API token for the user using the Jira console.
- Store the Jira user and token as key value pairs in AWS Secrets Manager as a secret; for example: JiraCredentials.
Test access to Jira
Once Jira and the credentials are configured, users should test if access works as expected.
Below is an example using the serverInfo endpoint. Replace the url with the user’s project url:
curl --request GET \
--url 'https://<<your jira>>/rest/api/3/serverInfo' \
--user 'email@example.com:<api_token>' \
--header 'Accept: application/json'
The API Group Server Jira documentation includes more examples out testing Jira access.
Bootstrap governance and governed accounts
In order to bootstrap the account, users need to have an AWS CLI profile for their chosen account already in place. For more details, review the CLI Configuration Files for configuration and credential file settings. Run the following AWS CDK command to allocate the base AWS CDK resources (known as bootstrapping). Replace <AWS_PROFILE>and <AWS_REGION> with the corresponding profile name, account ID, and Region that maps to the account users are going to bootstrap.
npm run cdk bootstrap -- --region ${AWS_REGION} --profile ${AWS_PROFILE}
If users have not created an AWS_PROFILE, export the following environment variables and replace the placeholders with the right values:
export AWS_ACCESS_KEY_ID=<AWS_ACCESS_KEY_ID_PLACEHOLDER>
export AWS_SECRET_ACCESS_KEY=<AWS_SECRET_ACCESS_KEY_PLACEHOLDERS>
export AWS_SESSION_TOKEN=<TOKEN_PLACEHOLDER>
export AWS_REGION=<AWS_REGION>
This will allow users to run the command without the extra arguments as follows:
npm run cdk bootstrap
As part of the bootstrapping process, AWS CDK will create a set of IAM roles that will be used when deploying resources in the user’s accounts. These can be accessed through the AWS console or using the AWS CLI.
Deployment Steps
This stack is a CloudFormation (cfn) stack that deploys the subscription workflow. Follow these steps to deploy the stack in the user’s account:
- Clone the Guidance repository :
git clone https://github.com/aws-solutions-library-samples/guidance-for-streamlining-data-access-permissions-with-amazon-datazone-and-jira-ticketing-system - Go to the directory of the cloned repository
cd guidance-for-streamlining-data-access-permissions-with-amazon-datazone-and-jira-ticketing-system - Run the
scripts/prepare.shto provide the DZ_DOMAIN_ID which will then be replaced in the following fileconfig/DataZoneConfig.ts.This domain ID is referenced to provide the permissions to perform API calls on the specified Amazon DataZone domain.
Example: scripts/prepare.sh dzd_3abcdef0972oi3
- If the Amazon DataZone domain is encrypted with a KMS customer managed key, specify the ARN of the the key in
config/DataZoneConfig.tsfor argumentDZ_ENCRYPTION_KEY_ARN. Otherwise, keep the value ofDZ_ENCRYPTION_KEY_ARNasnull - Specify the input parameters regarding the Atlassian Jira project in
config/SubscriptionConfig.ts- In
SUBSCRIPTION_DEFAULT_APPROVER_ID, specify the Id of the Jira Project Lead with the administrator role. This can be found by following the steps in the accepted answers of the How to get the user ID of a user not me documentation. - In
WORKFLOW_TYPE,specifyJIRA - In
JIRA_PROJECT_KEY, specify the project key. It can be found in the URL used to access Jira - In
JIRA_DOMAIN,specify the host name of the domain of the Jira project. For examplesomedomain.atlassian.net. - Example: You have the following link to access your Jira project: https://somedomain.atlassian.net/jira/core/projects/PROJECT/board In this example,
JIRA_DOMAINcorresponds to somedomain.atlassian.net andJIRA_PROJECT_KEYcorresponds toPROJECT.
- In
- Run the following command to deploy the AWS CDK app, replacing
<AWS_PROFILE>and<AWS_REGION>with the AWS CLI profile name mapping to your account:
npm run cdk deploy -- --all --region ${AWS_REGION} --profile ${AWS_PROFILE}
You will be able to see the progress of the deployment in your terminal and the AWS CloudFormation console of your account.
Deployment validation
Open the CloudFormation console and verify the status of the templates with the names ExternalWorkflowIntegDataZoneAccessStack and ExternalWorkflowIntegDataZoneSubscriptionStack.
Running the Guidance
In order to have your end-to-end workflow working after perfoming the deployment, follow these steps:
Add Jira Admin credentials to Secret in Secrets Manager
- Create an API token from the API Tokens documentation.
- Next, follow the steps in the Manage API Tokens for your Atlassian Account documentation.
- In the AWS account where you deployed this Guidance, locate the secrets with the name:
/JIRA/subscription-workflow/credentials:
Figure 11: Step screenshot
- Select Retrieve secret value:

Figure 12: Step screenshot
- Select Edit. You will get the error below. However, this is an expected behaviour since access to read the secret has been restricted to only the AWS Lambda function creating and getting the issues.
Figure 13: Step screenshot
Select set secret and add Token with value as the value generated in the first step
Add an Admin as the email of an administrators of your project
Figure 14: Step screenshot
Add an IAM role to the projects where you want to enable the automation
Go to IAM to add IAM roles as members of Amazon DataZone projects. Add permissions to the AmazonDataZoneDomainExecution role as described in the Add members to a project in Amazon DataZone documentation:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:GetUser", "iam:GetRole" ], "Resource": "*" } ] }
- Find a role named dzLambdaSubscriptionManagerRole.
- Copy the arn of this IAM role
- Go to your Amazon DataZone project where you want to enable the automation
- Go to members section and select add a member. You will get pop up shown below:
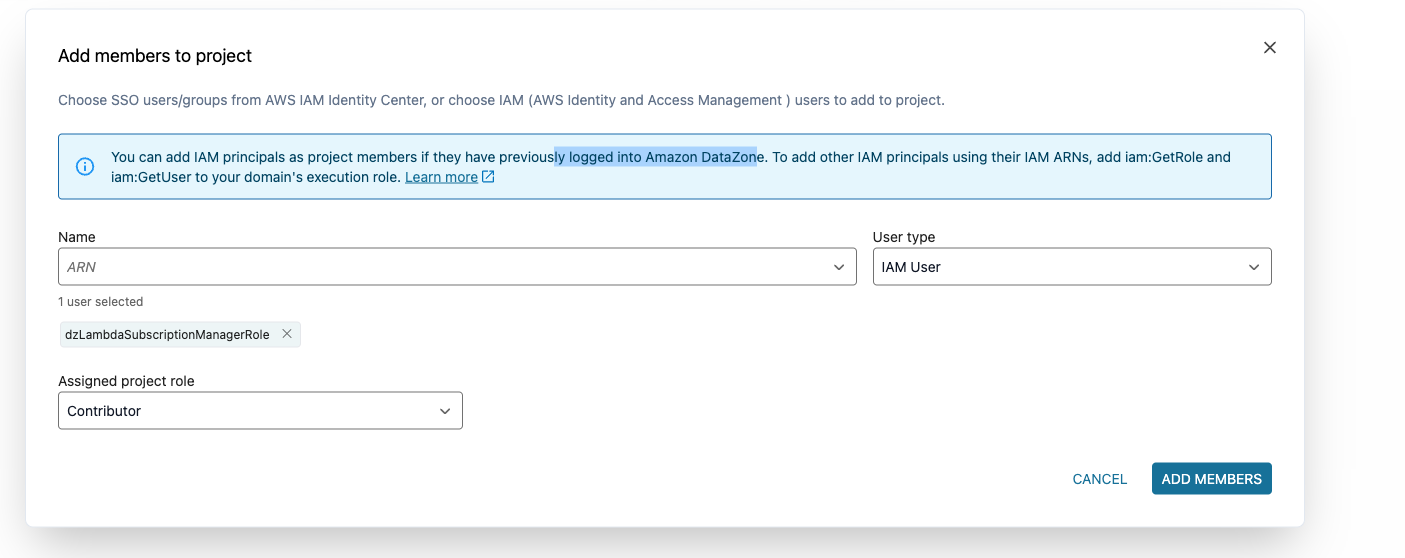
Figure 15: Step screenshot
- Paste the copied IAM Arn and select enter.
- Add it as a member of the projects with the Contributor role
Example: If you want to test the workflow end-to-end
Create a sample producer project and sample data asset
- Go to your Amazon DataZone domain specified in your configuration before deploying. Create an Amazon DataZone sample producer project with the name: SampleProducer:
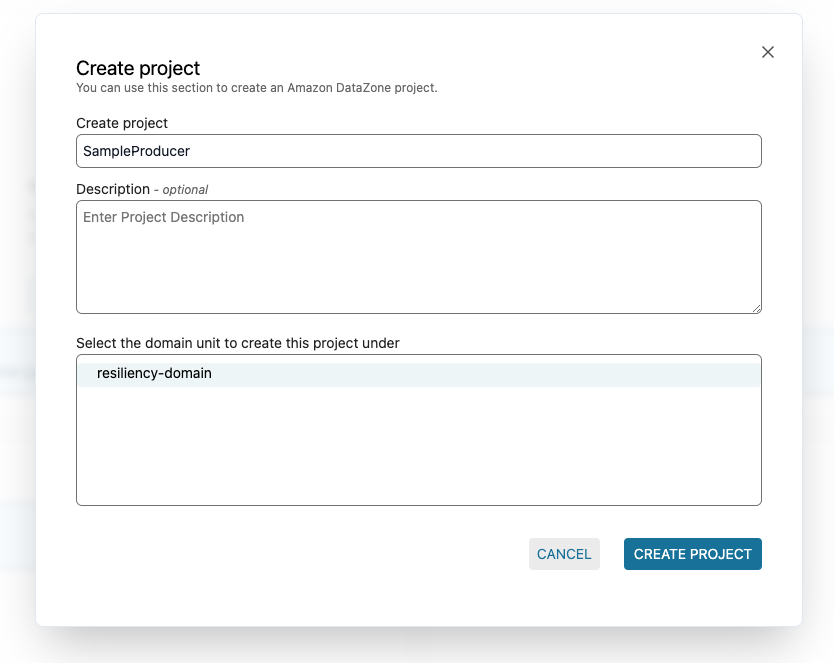
Figure 16: Step screenshot
- Create an environment with the name: DefaultAccount and select the environment profile as DatalakeProfile, then select create environment:
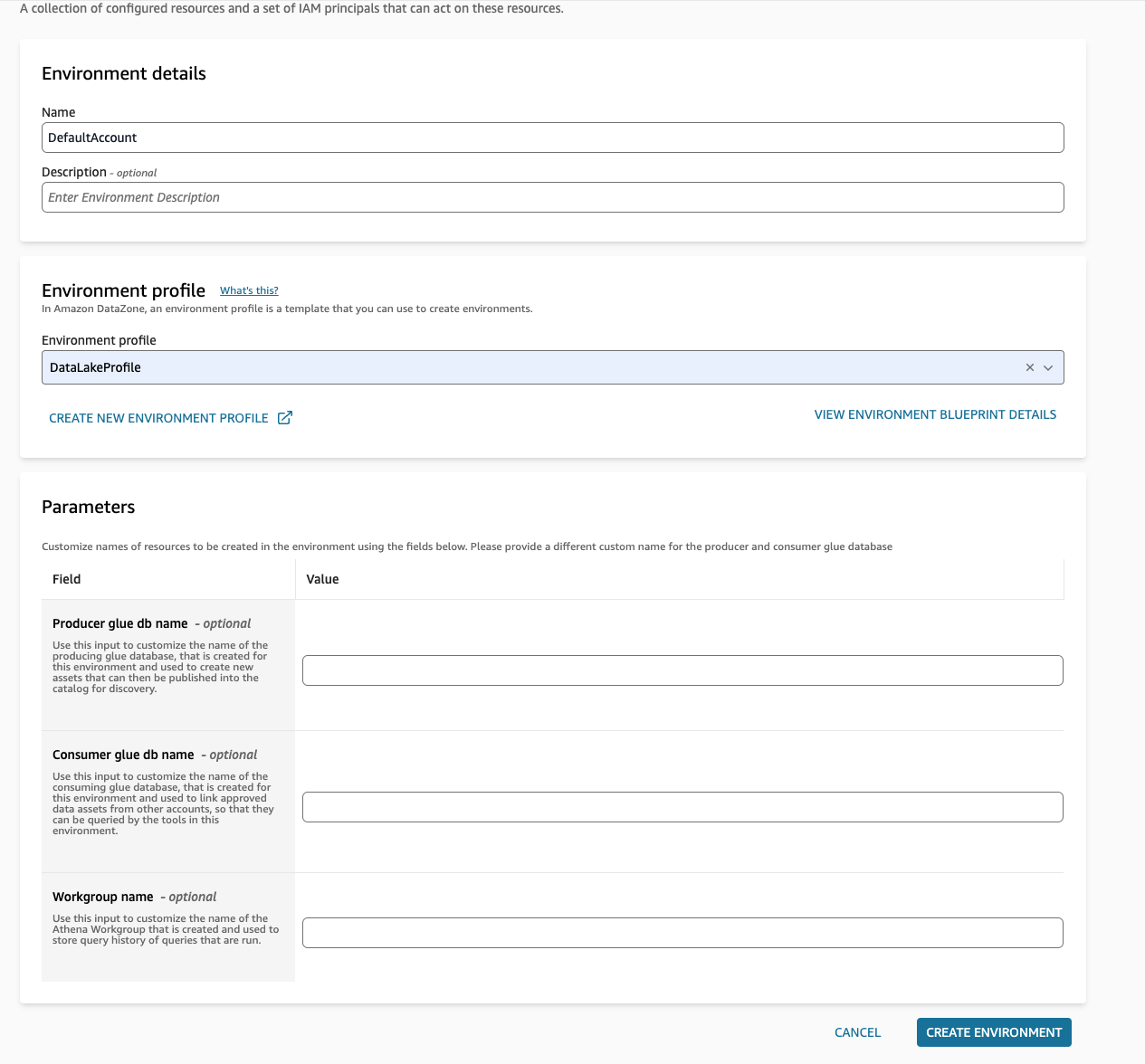
Figure 17: Step screenshot
Create sample dataset
1. Open the query editor by selecting **Query data** in the analytics tools. Make sure the right workgroup is selected. The workgroup name is by default the environment name.
2. Copy the following SQL query to create a dummy date:
CREATE TABLE sample_orders AS
SELECT 146776932 AS ord_num, 23 AS sales_qty_sld, 23.4 AS wholesale_cost, 45.0 as lst_pr, 43.0 as sell_pr, 2.0 as disnt, 12 as ship_mode,13 as warehouse_id, 23 as item_id, 34 as ctlg_page, 232 as ship_cust_id, 4556 as bill_cust_id
UNION ALL SELECT 46776931, 24, 24.4, 46, 44, 1, 14, 15, 24, 35, 222, 4551
UNION ALL SELECT 46777394, 42, 43.4, 60, 50, 10, 30, 20, 27, 43, 241, 4565
UNION ALL SELECT 46777831, 33, 40.4, 51, 46, 15, 16, 26, 33, 40, 234, 4563
UNION ALL SELECT 46779160, 29, 26.4, 50, 61, 8, 31, 15, 36, 40, 242, 4562
UNION ALL SELECT 46778595, 43, 28.4, 49, 47, 7, 28, 22, 27, 43, 224, 4555
UNION ALL SELECT 46779482, 34, 33.4, 64, 44, 10, 17, 27, 43, 52, 222, 4556
UNION ALL SELECT 46779650, 39, 37.4, 51, 62, 13, 31, 25, 31, 52, 224, 4551
UNION ALL SELECT 46780524, 33, 40.4, 60, 53, 18, 32, 31, 31, 39, 232, 4563
UNION ALL SELECT 46780634, 39, 35.4, 46, 44, 16, 33, 19, 31, 52, 242, 4557
UNION ALL SELECT 46781887, 24, 30.4, 54, 62, 13, 18, 29, 24, 52, 223, 4561
- Go to the data sources of your project and run the data source related to the previously created environment. The
sample_ordersis added to the inventory of your project. Select Publish asset to make it visible on the Amazon DataZone catalog.
Create a sample consumer project
Follow the previous steps to create a consumer project with the name: SampleConsumer. Create an environment for that project. Look for the data asset sample orders using the search bar and create a subscription request with request reason: sample test of subscription workflow
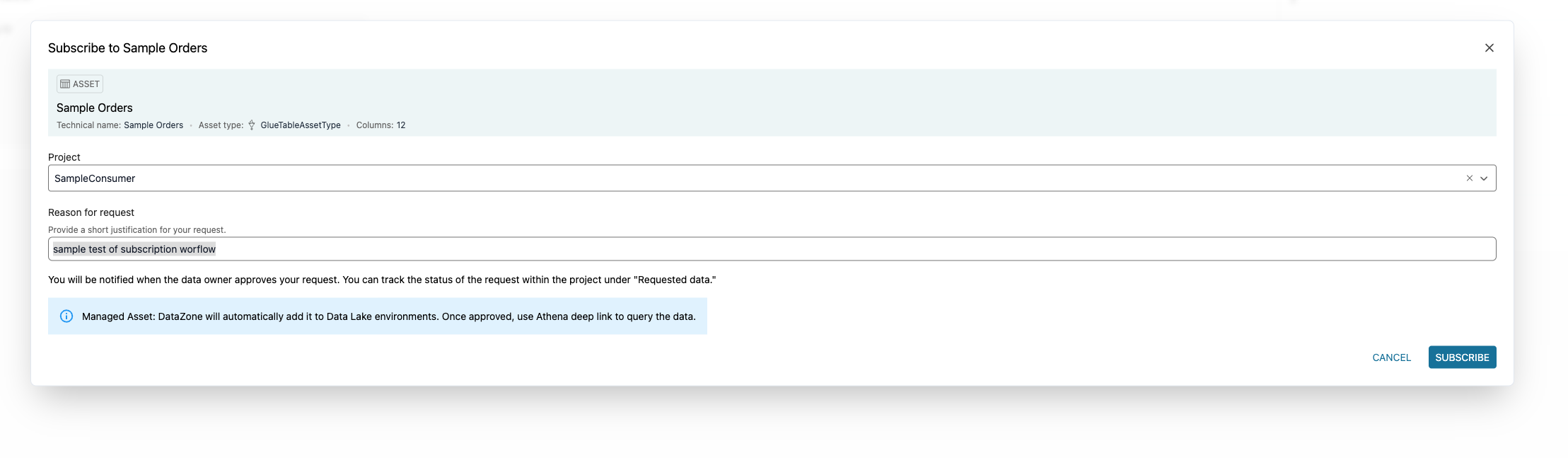
Figure 18: Step screenshot
Then, you will be able to see a new Jira ticket created on the Jira board related to your subscription request. You should see a task similar to the one depicted in the following figure
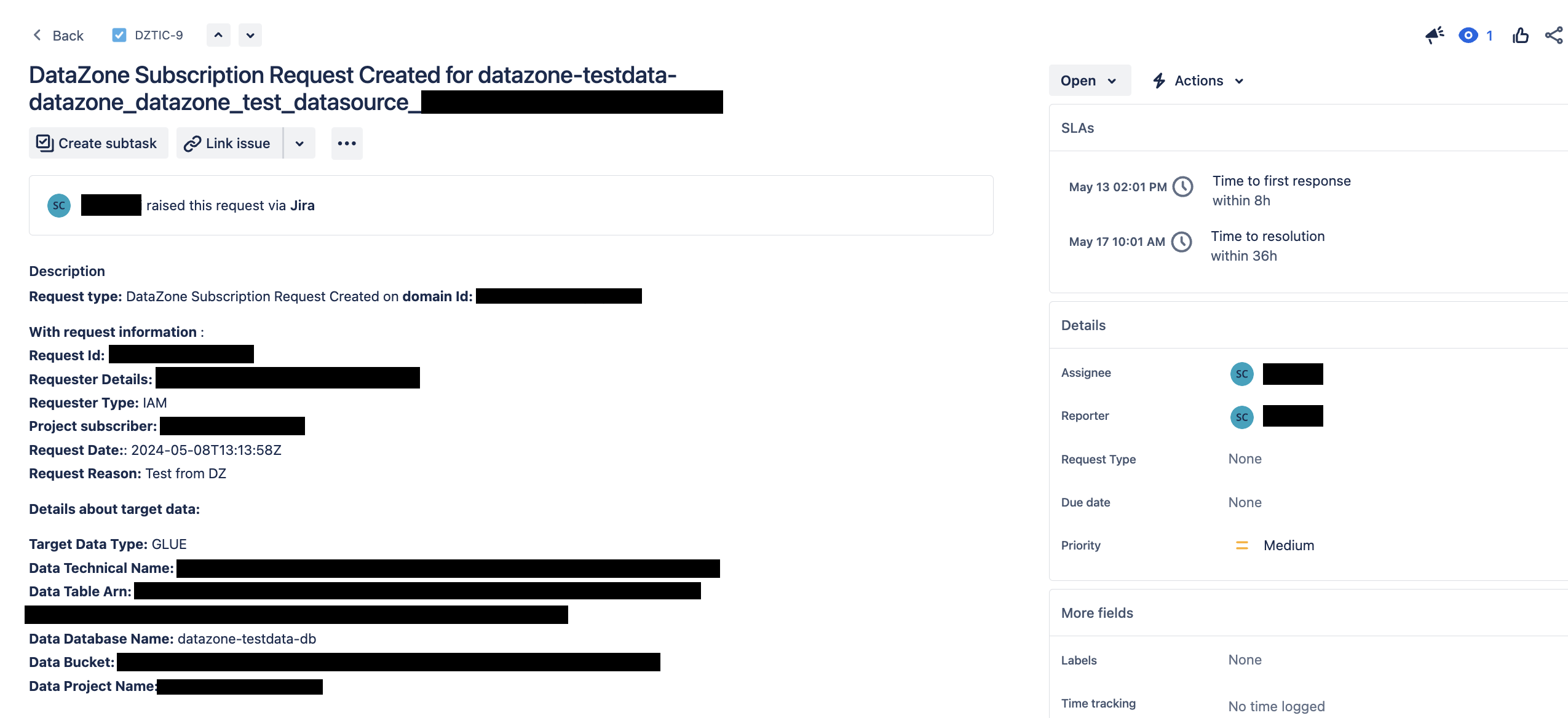
Figure 19: Step screenshot
- Move it to Accepted (or Rejected)
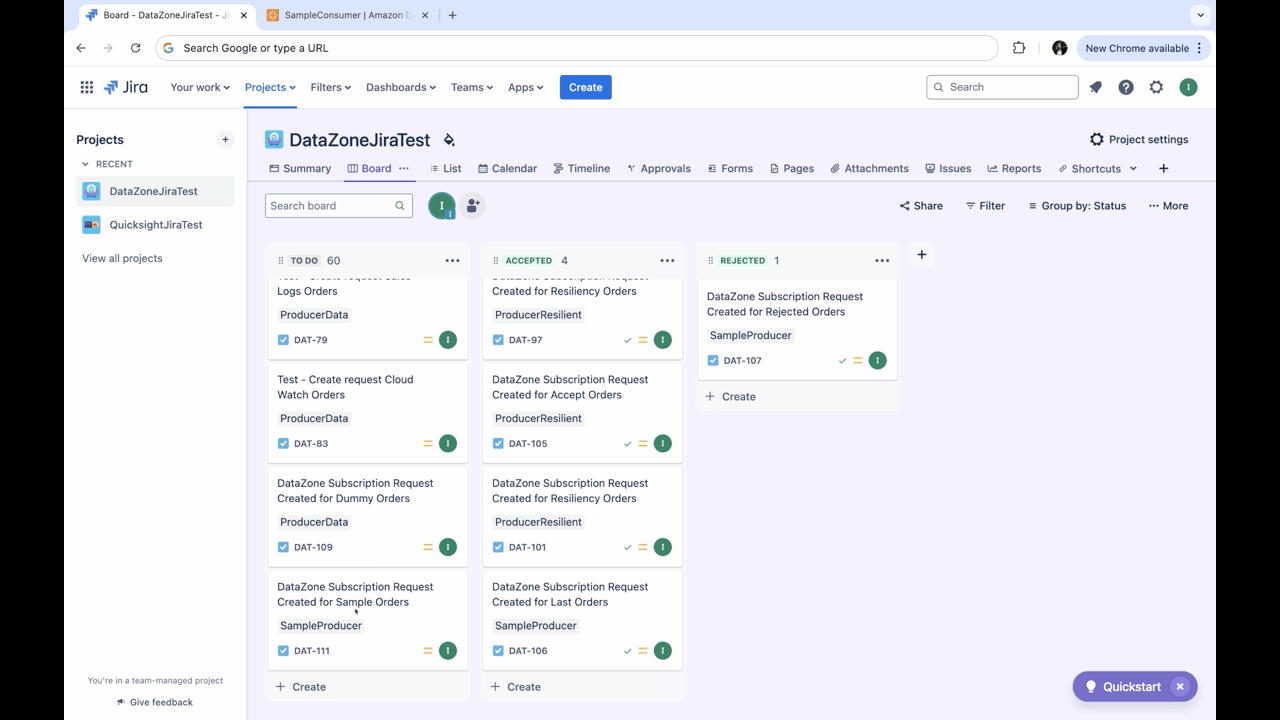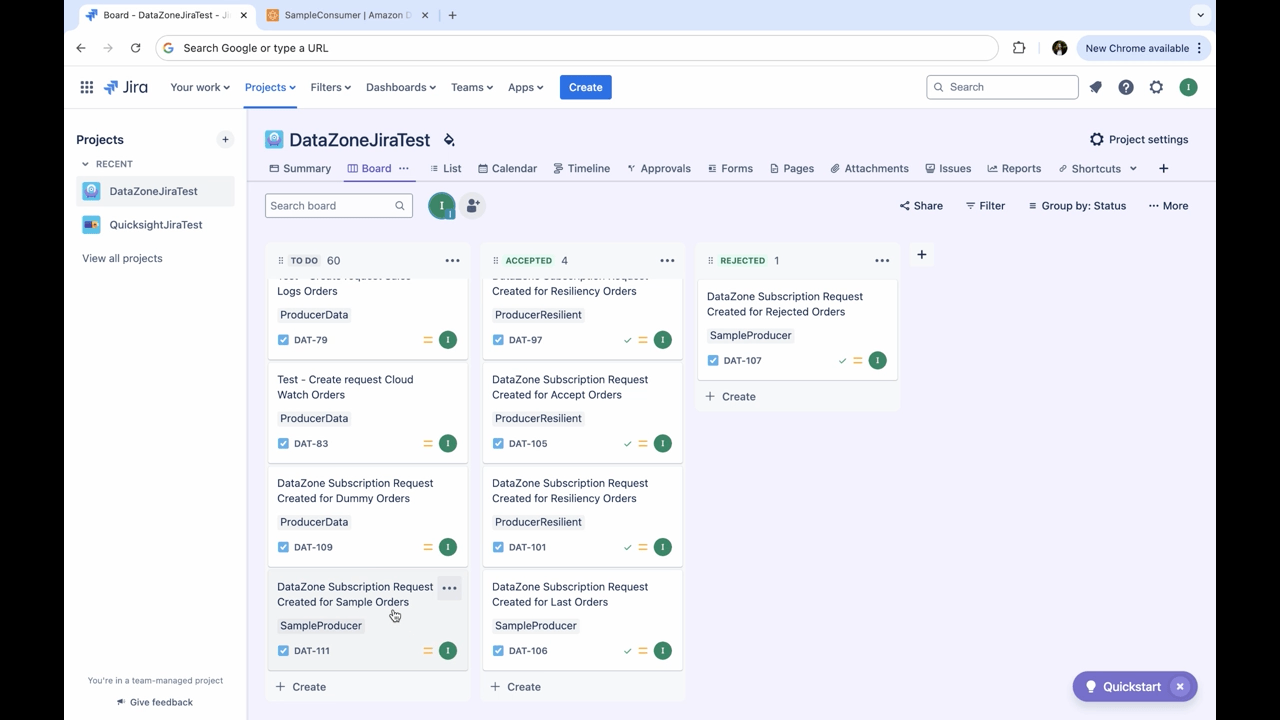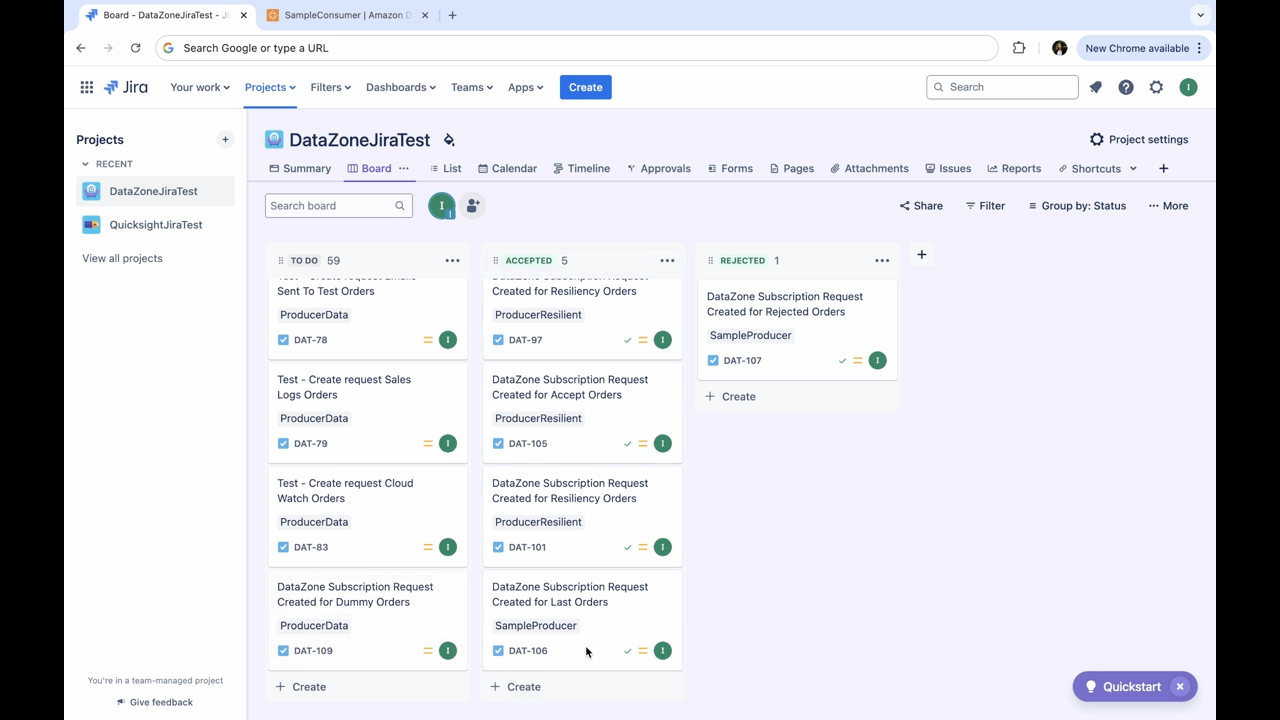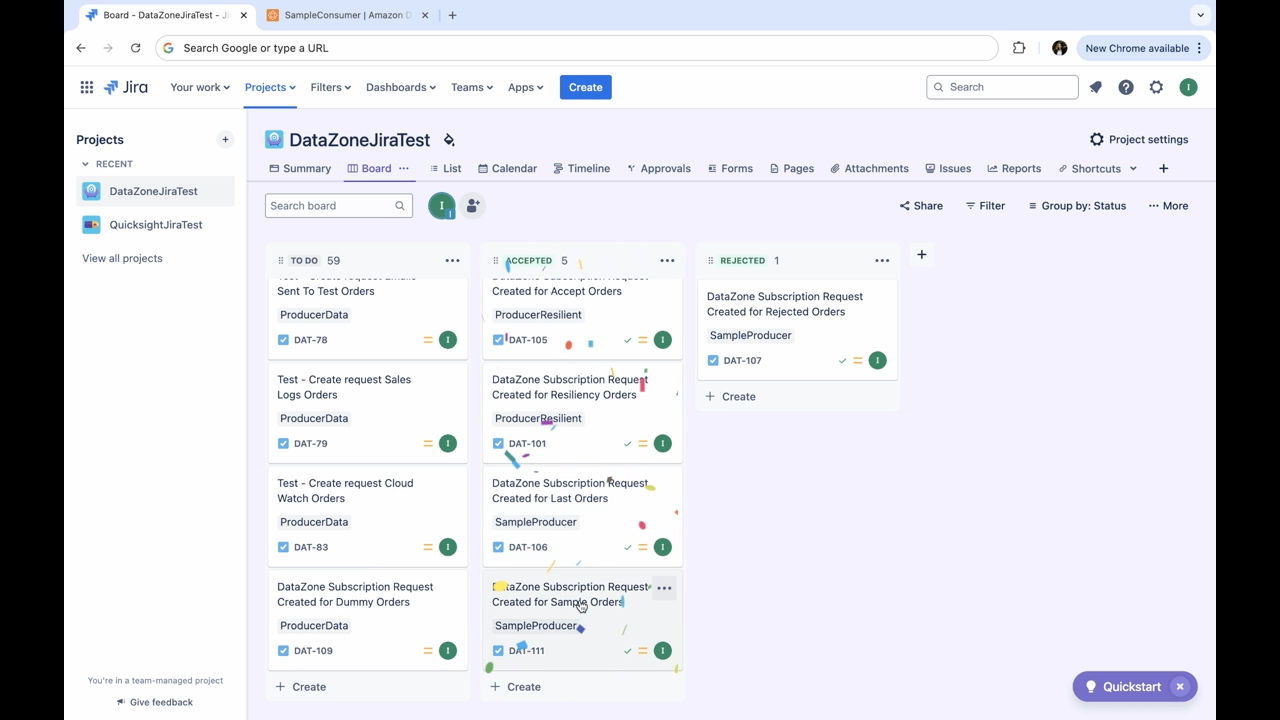
Figure 20: Step screenshot
- Wait for Status Update:
- Wait for at least 60 seconds, as this is the default waiting time of the step function before checking the status of the ticket. You will be able too see the issue the subscription request accepted (or rejected) on your Amazon DataZone portal under Subscribed Data section.
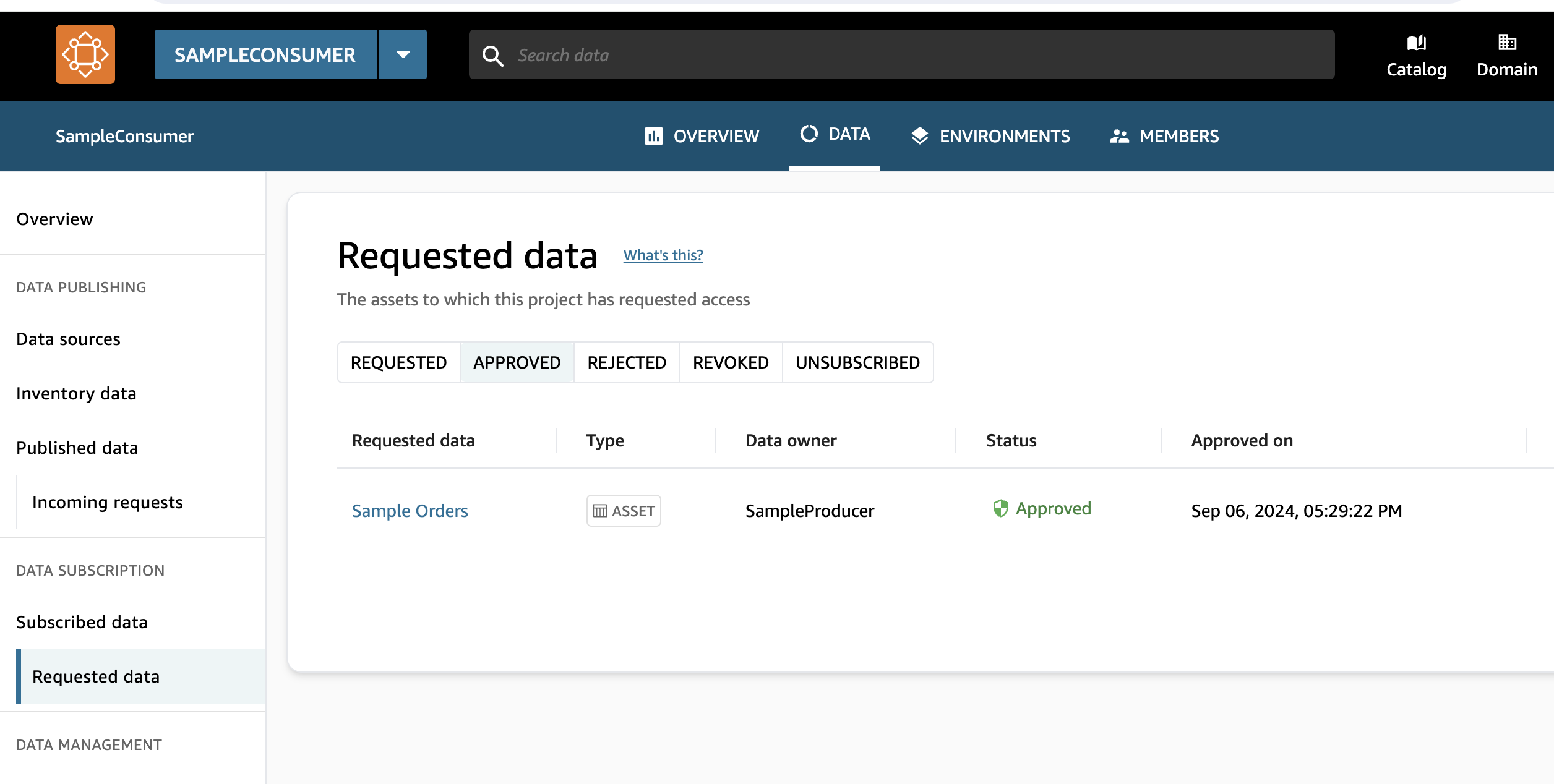
Figure 21: Step screenshot
Update the Guidance
To update this Guidance, follow the same steps for deployment, using the CDK’s change set functionality. Deploy it from your favourite CI/CD tooling. Always remember to review the change set produced to ensure no unintentional changes or downtimes are caused. Perform deployments first in your test environments or accounts to ensure the change is not breaking existing functionality or features. Continue to deploy to your production environment only after having verified your changes.
Uninstall the Guidance
Uninstall using AWS Management Console
- Sign in to the CloudFormation console.
- On the Stacks page, go through the following stacks in the suggested order, and choose Delete for each one of them. It is recommended to wait for deletion of each stack before moving to the next:
DataZoneSubscriptionAutomationRoleStackDataZoneSubscriptionStack
Uninstall using the AWS CDK CLI
Execute the following command to destroy the CDK app, replacing <AWS_REGION> and <AWS_PROFILE> with the AWS CLI profile name mapping to your governed account: npm run cdk destroy -- --all —region ${AWS_REGION} --profile ${AWS_PROFILE}
Even though the AWS CDK CLI will give you live updates on the destroy process, you can always follow along in the CloudFormation console.
Developer Guide
Source code
Visit the GitHub repository to get the source files for this Guidance and optionally to share your changes with the community.
Repository structure
The repository contains the following folders:
bin:Contains the CDK application entry source file namedapp.ts.config:Contains the CDK configuration for deploying this Guidance. Refer to the Application Stack Configuration.docs:Contains the repository documentation images used in theREADME.md.lib:Contains all the CDK stacks deployed by this Guidance. These are referenced in theapp.tsfile.scripts:Contains scripts to check and update the Open Source licenses of the dependencies that you use in your package.json (CDK dependencies) as well as in your Lambda functions.src:Contains code for all the Lambda functions that are deployed by this Guidance.datazone-subscription:Contains the code for the subscription Lambda functions that implement the subscription workflow with the external workflow systems.
In addition, there are additional technical configuration files in the root folder of the repository that configure the repository for development and deployment purposes:
package.json:The NPM package configuration file, including the NPM dependencies for your CDK stacks.cdk.json:Central CDK configuration file..eslintrc.json:Linting configuration for the CDK typescript code in this repository.
Application stacks
The CDK application consists of the following stacks:
DataZoneSubscriptionAutomationRoleStack: Creates the Subscription Manager role that is used to automate approval or rejection of subscription requests.DataZoneSubscriptionStack: Creates the resources that implement the subscription workflow:- The Create/GetIssue Lambda function that creates or retrieves the Jira issue.
- The Change Subscription Status Lambda function that can accept or reject a subscription.
- The subscription workflow Step Functions.
- The execution roles for these.
Application stack configuration
The application stacks can be configured in two different source files:
DataZoneConfig.ts:Contains the main Amazon DataZone related configuration:- Change the
DZ_DOMAIN_IDin this file to the existing domain that you are using. DZ_APP_NAME: The application name to use for prefixing all the CDK stacks.DZ_ENCRYPTION_KEY_ARN: The ARN of the custom encryption key that has been used for encrypting the Amazon DataZone domain, or null if default encryption has been used.
- Change the
SubscriptionConfig.ts:Contains the configuration of the subscription workflow. All of these values are handed into the subscription workflow Lambda functions as environment variables.SUBSCRIPTION_DEFAULT_APPROVER_ID: The ID of a default assignee in the external workflow system.WORKFLOW_TYPE: Defines which kind of workflow to use. Refer to External workflow class hierarchy for more details. Currently supported values:JIRA, MOCK_ACCEPT, MOCK_REJECT.JIRA_DOMAIN: Specific forWORKFLOW_TYPE = JIRA. Contains the Jira domain to communicate with.JIRA_PROJECT_KEY: Specific forWORKFLOW_TYPE = JIRA. Contains the Jira project key to communicate with.JIRA_POLLING_FREQUENCY: The frequency of polling Jira in the resilient version of the implementation.RESILIENCY_ENABLED: Set to true to use the resilient handler for communication with the external workflow system, false to use the default polling mechanism.
Lambda function implementation
This section of the Guidance describes how the Lambda functions work in detail from a design and implementation point of view. The Lambda functions are implemented in Python 3.11.
Entry points
This Guidance contains a single deployment package including two Lambda function handlers. This package is deployed through a CDK in to two distinct Lambda function instances, one for each of the handlers.
- Create/GetIssue Lambda Handler: This handler has two implementations in
handler_create_get_issue_status.py(classic workflow) andhandler_create_get_issue_status_resilient.py(resilient workflow). Depending on the command handed to the function handler, it has the following responsibilities:CREATE_ISSUE: Creates a new issue in the external workflow system; for example - in Jira.GET_ISSUE: Checks the status of the given issue in the external workflow system; for example - in Jira, and returns its status.
- Change Subscription Status Lambda Handler: Based on its input, this function handler either approves or rejects a subscription request in DataZone.
There are two versions of the Create/GetIssue Lambda Handler, depending on the value of RESILIENCY_ENABLED: A normal direct implementation using polling (refer to Classic workflow), and a resilient implementation that uses an SQS queue (refer to the Resilient workflow) section.
Environment variables
The Lambda function handlers need specific environment variables to be configured properly. All of them are derived from the configuration described in the Application Stack Configuration.
Create/GetIssue Lambda Handler: Requires workflow type and external workflow configuration:
* `SUBSCRIPTION_DEFAULT_APPROVER_ID`: The ID of a default assignee in the external workflow system. Configured in and `SubscriptionConfig.t` is passed into the Lambda function by the CDK deployment.
* `WORKFLOW_TYPE`: Defines which kind of workflow to use, refer to [External workflow class hierarchy](#external-workflow-class-hierarchy) for more details. Currently supported values: `JIRA, MOCK_ACCEPT, MOCK_REJECT`. Configured in and `SubscriptionConfig.ts` passed into the Lambda function by the CDK deployment.
* `JIRA_DOMAIN`: Specific for `WORKFLOW_TYPE = JIRA`. Contains the Jira domain to communicate with. Configured in and `SubscriptionConfig.ts` passed into the Lambda function by the CDK deployment.
* `JIRA_PROJECT_KEY`: Specific for `WORKFLOW_TYPE = JIRA`. Contains the Jira project key to communicate with. Configured in and `SubscriptionConfig.ts` passed into the Lambda function by the CDK deployment.
* `JIRA_ISSUETYPE_ID`: Specific for `WORKFLOW_TYPE = JIRA`. Contains the Jira issue type to create. Hardcoded and passed with value `10004`.
* `JIRA_SECRET_ARN`: Specific for `WORKFLOW_TYPE = JIRA`. Contains the ARN of an AWS Secrets Manager secret containing the credentials for communication with Jira. The secret is created during the CDK deployment and its ARN is passed to this environment variable.
Change Subscription Status Lambda Handler: * SUBSCRIPTION_CHANGE_ROLE_ARN: The ARN of the subscription manager role. This role is assumed by the Lambda handler in order to accept or reject subscription requests in DataZone.
External workflow class hierarchy
The Lambda function handlers use a Python class hierarchy to represent the external workflow systems for extensibility. The concrete workflow to use is determined by setting the environment variable WORKFLOW_TYPE to the desired value.
The class hierarchy is displayed in the image below:
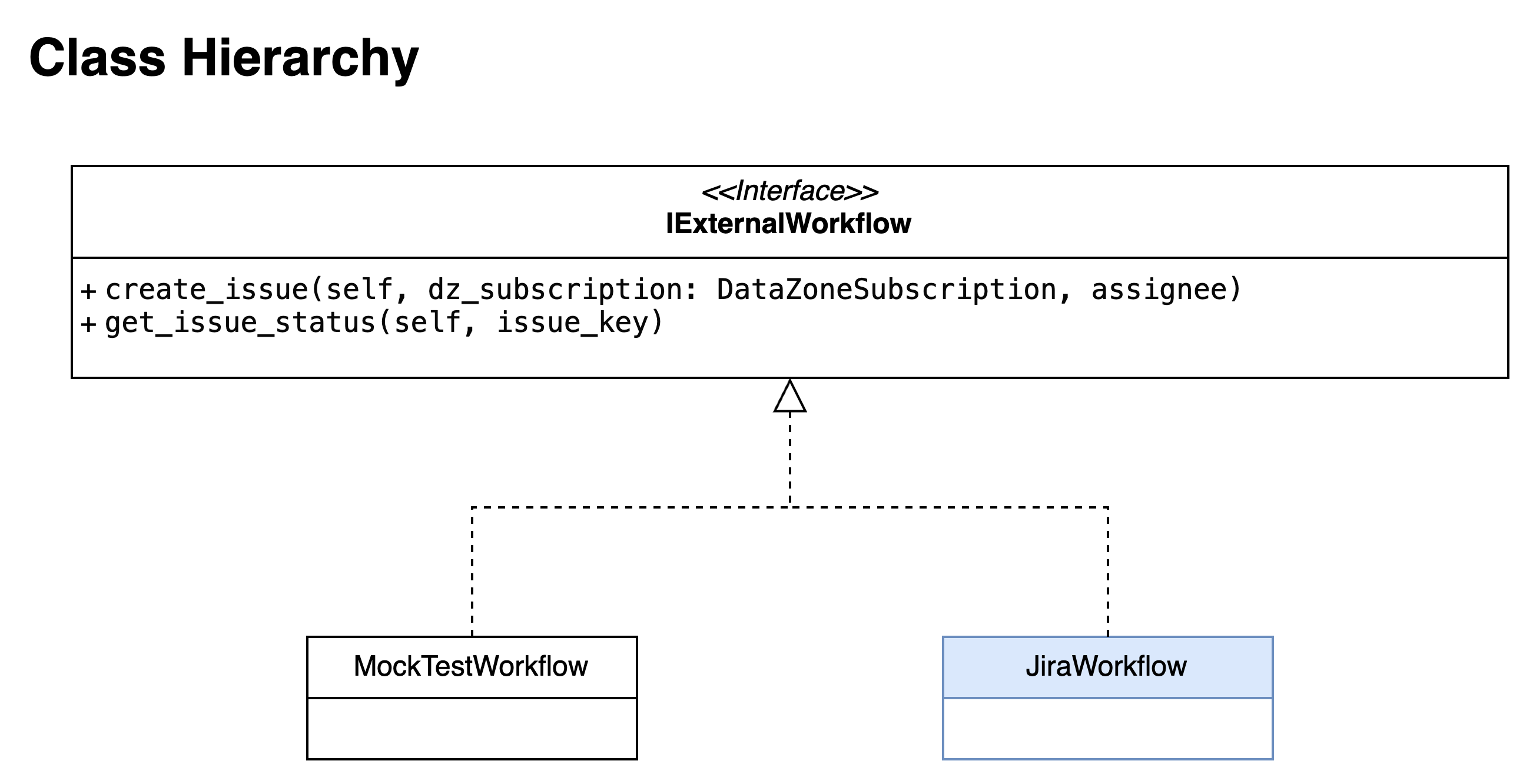
Figure 22: External workflow class hierarchy
The IExternalWorkflow is an interface that defines the contract for each workflow class:
- create_issue: Creates an issue in the external workflow system using the information provided for the details about the DataZone subscription as well as an assignee. It returns the issue ID that has been created.
- get_issue_status: Retrieves the status for the given issue ID from the external workflow system.
There are currently the following implementations for the IExternalWorkflow:
JiraWorkflow- Corresponds toWORKFLOW_TYPE = JIRA. This is the default Jira implementation that creates an issue in Jira and retrieves its status, both through the REST APIs of Jira. A Jira instance configuration is required to pass as environment variables for this workflow type. It is used with both the classic and the resilient workflow.MockTestWorkflow- Corresponds toWORKFLOW_TYPE = MOCK_ACCEPTorWORKFLOW_TYPE = MOCK_REJECT. This is just for testing the Step Functions workflow and it does not communicate with any external system. It either directly accepts or rejects the subscription request in Amazon DataZone.
The DataZoneSubscription class
The DataZoneSubscription class implements all aspects of communication with the Amazon DataZone API through Boto 3. It has the following responsibilities:
- It parses the input event passed to the Create/GetIssue Lambda Handler, as this is an EventBridge event specific to Amazon DataZone subscription requests. It extracts all necessary information from the input event and stores them as instance attributes.
- As the input event basically contains IDs referring to Amazon DataZone objects, as well as the subscription requests, this class needs to retrieve additional information from the Amazon DataZone API to enrich the issue created in the external workflow system:
- The project name of the requesting project through the get_project API.
- The requesting user’s name through the get_user_profile API.
- The subscription details, such as the owners project name, bucket location, table ARN, and request reason, among others through the get_subscription_request_details API.
- It accepts or rejects a subscription request through the API:
- Calls the accept_subscription_request API for accepting a request.
- Calls the reject_subscription_request API for approving a request.
Rest API communication (Jira)
This section describes the Jira Rest API communication that is implemented in the jira_workflow.py module in the JiraWorkflow class.
This class uses urlib3 for communicating with Jira. It configures urllib3 with 10 retries and an exponential backoff factor of 0.5. It uses HTTPs encrypted basic authentication with the following headers:
- Content-Type: application/json
- Authorization: Basic with token
The Jira REST API endpoints that are called are:
- Create Issue:
POST [https://{JIRA_DOMAIN}/rest/api/latest/issue/](https://{jira_domain}/rest/api/latest/issue/)- Input: Assignee (=
SUBSCRIPTION_DEFAULT_APPROVER_ID), project (=JIRA_PROJECT_KEY), description, summary, issue type (=JIRA_ISSUETYPE_ID), labels (= DataZone owner project name) - Output: The key of the newly created issue in Jira; for example: the ticket ID.
- Input: Assignee (=
- Get Issue: GET
- Input: Issue key as path parameter
- Output: Assignee as approver, status of the issue
These endpoints are documented in the Atlassian REST API V2 developer documentation.
Error handling
The implementation follows the principle of fail fast to abort processing whenever an irrecoverable error is detected:
- When parsing the input Amazon DataZone subscription event in the
DataZoneSubscriptionclass,ValueErrorsare raised when an expected input key is not found in the event; for example, it is a malformed event. - When an API call fails, the result is logged, and the Lambda execution is terminated by raising the error.
For handling resilience, there are two special exception types defined in exceptions.py that are dealt with in the resilient workflow. Every IExternalWorkflow implementation may throw these errors if appropriate:
ExternalWorkflowRespondedWithNOK: Could not communicate with the external workflow system to create issues or obtain the issue status. This is for non-recoverable errors where retry does not make sense. For example, Jira returned HTTP 401 or 403, (authorization issues). The resilient handler implementation fails if this exception is caught by signaling to the state machine that processing needs to be halted.ExternalWorkflowNotReachable: Temporarily could not communicate with the external workflow system to create issues or obtain the issue status. Should only be used for recoverable, temporary error situations where a retry is applicable. The resilient handler implementation retries if this exception is caught by reraising the exception. This leads to the message being kept on the Amazon SQS queue and reprocessed during the next try. This exception is also raised when the maximum number of retries for the resilient implementation is exceeded. For example, this exception is raised when Jira returns HTTP 429 due to rate limiting.
Extend this Guidance
Thanks to the external workflow class hierarchy, this Guidance offers some level of extensibility if you want to connect to similar external workflow systems that support the concept of issue creation and retrieval through API. For this you need to:
- Add a new implementation of
IExternalWorkflowto implement communication with the new external workflow system. - Create class attributes for all the input parameters needed to communicate with the external workflow.
- Implement create_issue and get_issue functions respecting the functions signatures in
IExternalWorkflow.
Below is the MockTestWorkflow class as an example, found in the source code of this Guidance:
import logging
from external_workflow import IExternalWorkflow
from data_zone_subscription import DataZoneSubscription
logger = logging.getLogger()
logger.setLevel(logging.INFO)
class MockTestWorkflow(IExternalWorkflow):
'''A mock test external workflow doing nothing but returning fixed values. Just for testing purposes.'''
def __init__(self, accept: bool) -> None:
self.accept = accept
def create_issue(self, dz_subscription: DataZoneSubscription, assignee):
logger.info(f"Mock Test Workflow: create_issue for assignee {assignee}")
return 'IssueId1234567'
def get_issue_status(self, issue_key):
logger.info(f"Mock Test Workflow: get_issue_status for issue_key {issue_key}")
return ('Accepted' if self.accept else 'Rejected', 'assignee')
- Add a new
WORKFLOW_TYPEcondition for the new external workflow system increate_workflowfunction incommon.py - Read the input parameters needed by the workflow as environment variables
- Instantiate the new class
As an example, refer to the statements for the Mock workflow:
def create_workflow(workflow_type_string):
if workflow_type_string == "MOCK_ACCEPT":
return MockTestWorkflow(True)
elif workflow_type_string == "MOCK_REJECT":
return MockTestWorkflow(False)
elif workflow_type_string == "JIRA":
# ... continued
- If extra environment variables are needed because the new workflow needs more parameters than the ones already present in
SubscriptionConfig.ts- add an entry to
SubscriptionConfig.ts - Pass that entry as an environment variable to the dataZone_create_get_issue lambda function in
DataZoneSubscriptionStack.ts
- add an entry to
Related Resources
- Amazon DataZone API
- Eventbridge rules for Amazon DataZone
- IAM Roles with Amazon DataZone:
- Jira API
Contributors
- Inas Kaci
- Sindi Cali
- Jens Ebert
- Sanjay Kashalkar
- Gezim Musliaj
- Guido Pomidoro
- Leonardo Gomez
- Deepika Suresh
Notices
Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents AWS current product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. AWS responsibilities and liabilities to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers.