Guidance for Securing Sensitive Data in RAG Applications using Amazon Bedrock
Summary: This implementation guide provides an overview of security patterns for protecting sensitive data in Retrieval Augmented Generation (RAG) applications using Amazon Bedrock. The guide presents two architecture patterns: data redaction at storage level and role-based access control, both implemented with Amazon Bedrock Knowledge Bases, Amazon Bedrock Guardrails and complementary AWS services. These patterns address the critical need to safeguard personally identifiable information (PII), protected health information (PHI), and confidential business data throughout the RAG workflow while maintaining high-quality AI responses. This guide is intended for solution architects, DevOps engineers, data scientists, and cloud professionals implementing generative AI applications in regulated industries.
Overview
Organizations implementing Retrieval Augmented Generation (RAG) applications face security challenges when handling sensitive information such as personally identifiable information (PII), protected health information (PHI), and confidential business data. Without proper security controls, organizations risk exposing sensitive information to unauthorized users, potentially resulting in regulatory violations, breach of customer trust, and reputational damage. This Guidance helps organizations implement a threat model for generative AI applications while maintaining the utility and effectiveness of RAG workflows.
This Guidance for Securing Sensitive Data in RAG Applications using Amazon Bedrock addresses these challenges by providing security architecture patterns that protect sensitive data throughout the RAG workflow, from ingestion to retrieval. The Guidance presents two security architecture patterns implemented with AWS services:
Data Redaction at Storage Level: A zero-trust approach that identifies and redacts sensitive data before storing it in vector databases, ensuring sensitive information is never exposed during retrieval and generation.
Role-Based Access Control: A permission-based approach that enables selective access to sensitive information based on user roles during retrieval, appropriate for environments where sensitive data needs to be accessible to authorized personnel while being protected from unauthorized access.
Both patterns are implemented using Amazon Bedrock Knowledge Bases as the foundation, complemented by security services such as Amazon Comprehend, Amazon Macie, Amazon Cognito, and Amazon Bedrock Guardrails to create a defense-in-depth security strategy.
Features and benefits
This section describes features and benefits specific to this Guidance.
- Multi-layered Security Architecture: Combines PII/PHI detection, data redaction, deep security scanning, role-based access, and guardrails for comprehensive protection
- Automated Detection and Redaction: Leverages Amazon Comprehend to identify and mask sensitive entities in documents before ingestion
- Secondary Verification: Uses Amazon Macie to verify redaction effectiveness and identify remaining sensitive data
- Fine-grained Access Control: Implements role-based access with metadata filtering to control data visibility based on user permissions
- Input and Output Protection: Applies guardrails on both queries and responses to prevent policy violations
- Deployment Flexibility: Implemented through AWS CDK with customizable components that adapt to specific security requirements
- Regulatory Compliance Support: Helps organizations maintain compliance with data privacy regulations by preventing unauthorized data exposure
Use cases
This section describes some potential use cases for this Guidance. The security patterns implemented in this solution can be adapted to various industries and scenarios beyond those listed below.
Healthcare Data Protection for HIPAA Compliance
Healthcare providers can leverage RAG applications to assist medical staff with patient information while maintaining HIPAA compliance. The role-based access control pattern enables doctors to access complete patient information while limiting nurses to only the information they’re authorized to view. PHI is protected according to regulatory requirements, ensuring patient privacy is maintained while improving care quality through AI-assisted knowledge retrieval.
Financial Services Document Processing with Regulatory Compliance
Investment firms can process client financial documents through the redaction pipeline before using them in RAG applications. This ensures sensitive financial data is redacted before storage, maintaining compliance with regulations like GLBA and GDPR. Client confidentiality is preserved while still allowing financial advisors to leverage AI assistance for investment recommendations and portfolio analysis without exposing PII.
Enterprise Knowledge Management with Confidentiality Controls
Organizations can implement secure RAG applications for internal documents containing confidential information across different departments. The metadata filtering capabilities ensure different departments receive information appropriate to their clearance level, protecting intellectual property while enabling knowledge sharing without compromising security policies. Executive teams can receive complete information while other employees see appropriately filtered content.
Legal Document Analysis with Client Privacy Protection
Law firms can process case documents with sensitive client information through the redaction pipeline for AI-assisted research and analysis. Client identifiers are redacted at storage level while case facts remain accessible without exposing protected information. This preserves attorney-client privilege in AI interactions while enhancing legal analysis through appropriate information access controls that maintain document context.
Secure Multi-tenant RAG Applications
SaaS providers can build multi-tenant RAG applications where tenant data is protected through isolation and role-based access controls. The security architecture ensures that users from one organization cannot access data belonging to another organization, while still allowing shared model infrastructure. This enables cost-efficient deployment of RAG capabilities across multiple customers while maintaining strict data separation and compliance.
This Guidance was designed to be flexible and customizable, allowing organizations to adapt the security patterns to their specific requirements while leveraging the capabilities of Amazon Bedrock for generative AI applications.
Architecture overview
This section provides a reference implementation architecture diagram for the components deployed with this Guidance.
This Guidance presents two distinct architectural patterns for securing sensitive data in RAG applications using Amazon Bedrock. Each pattern addresses different security requirements and organizational needs. The first focuses on proactive redaction of sensitive data before storage, while the second implements role-based access controls for situations where sensitive data must be preserved but accessed selectively.
Scenario 1: Data redaction at storage level
Figures 1a and 1b show this scenario’s reference architecture, illustrating how customers can safely ingest sensitive documents through automated redaction and verification processes while enabling secure, guardrail-protected access to their knowledge base. The architecture demonstrates a complete security workflow that begins with document upload and PII detection, continues through multi-layered redaction and verification mechanisms, and culminates with authenticated retrieval protected by input and output guardrails. This comprehensive approach ensures sensitive information is properly secured throughout the entire lifecycle while maintaining functional access for authorized users.
Scenario 1: Architecture diagram
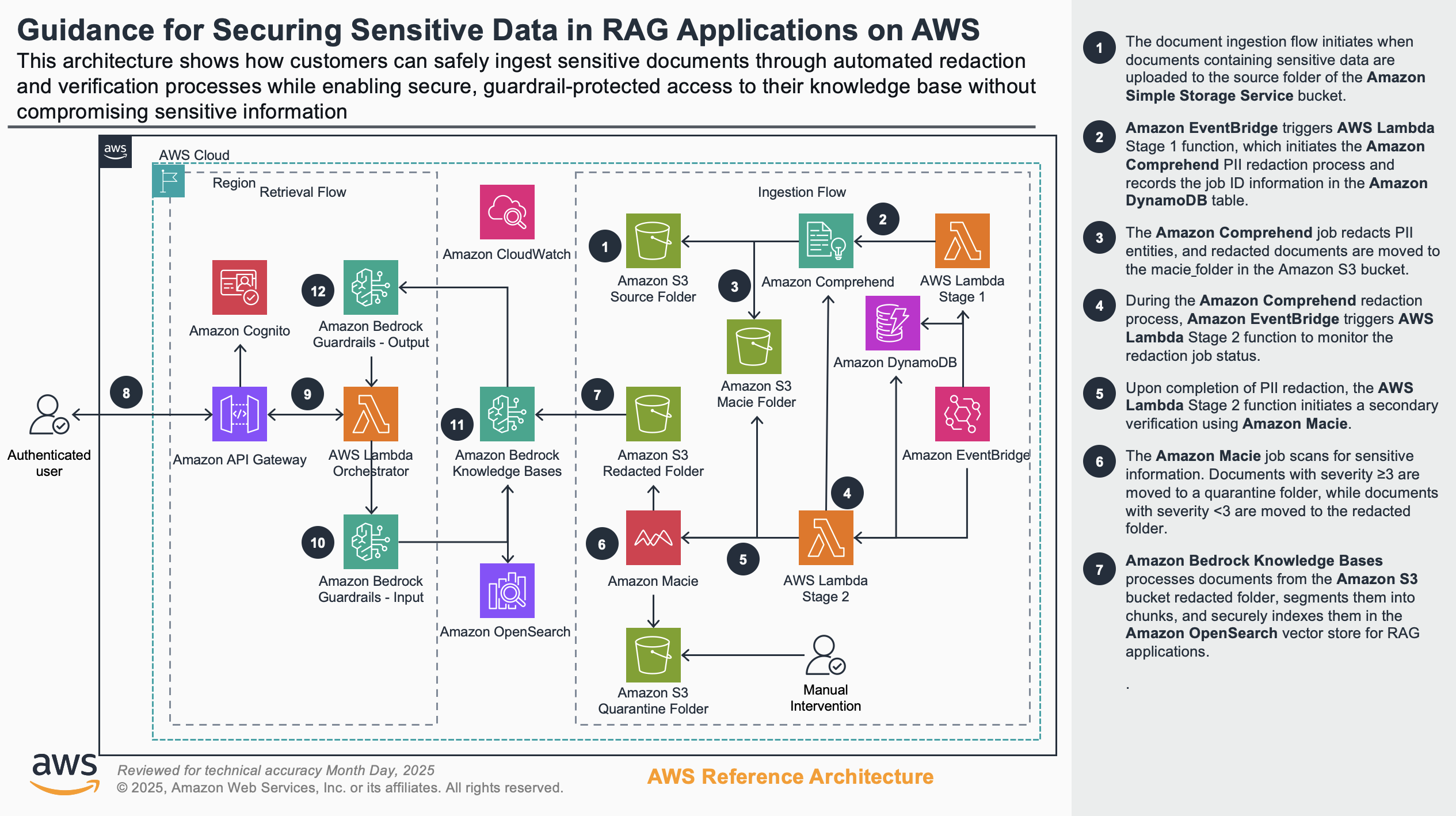
Figure 1a: Architecture for Scenario 1: Data redaction at storage level - Part 1
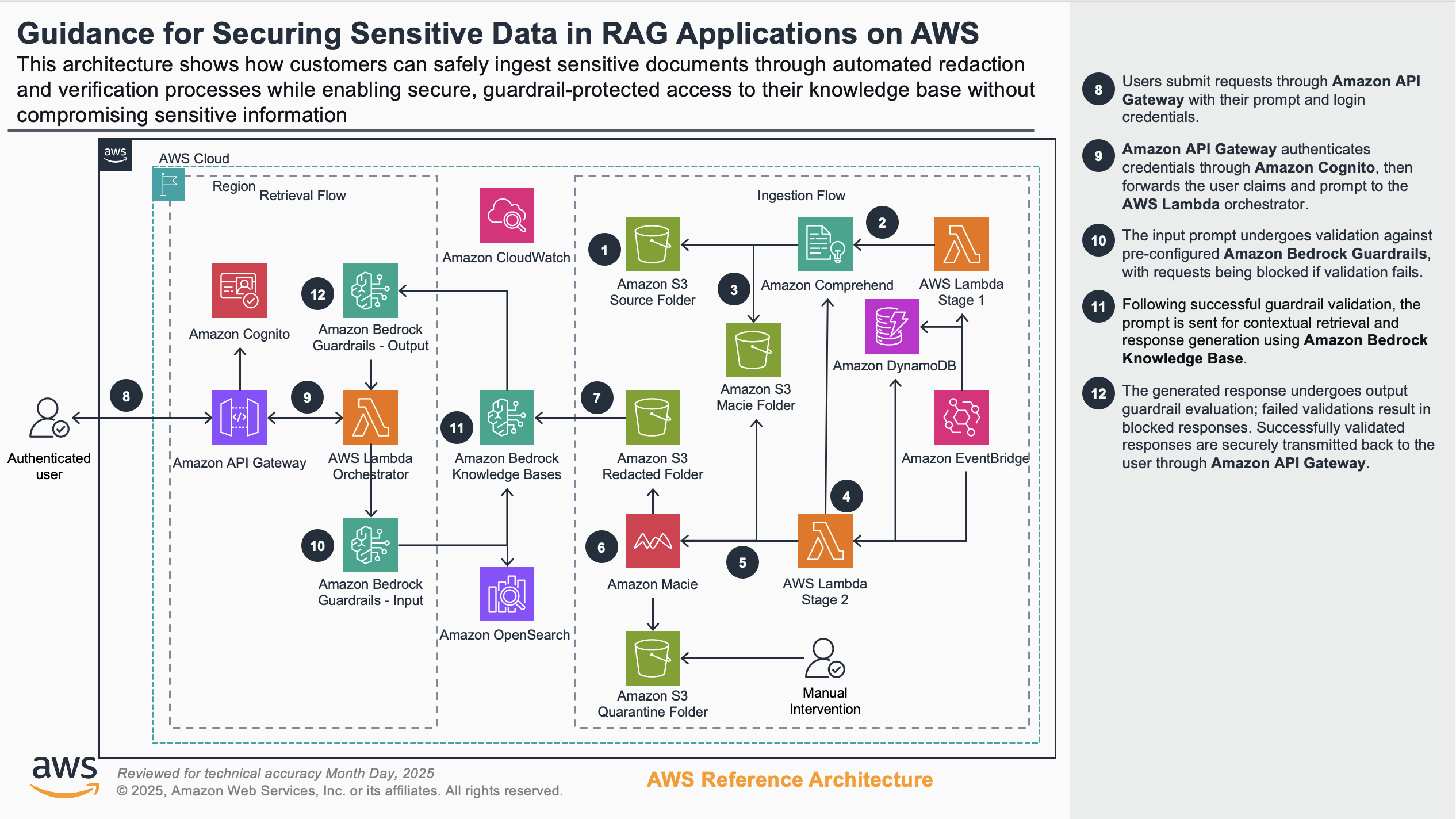
Figure 1b: Architecture for Scenario 1: Data redaction at storage level - Part 2
Scenario 2: Role-based access to sensitive data
Figure 2 shows this scenario’s reference architecture, illustrating the dynamic application of security controls based on user roles when accessing sensitive information. Unlike Scenario 1, this approach maintains sensitive data in the knowledge base but implements sophisticated controls to restrict access based on user permissions and identity attributes.
The diagram illustrates the technical implementation that enables fine-grained access control. It features dual guardrail configurations—one for administrators and another for non-administrators—that are automatically applied based on user authentication claims. When users submit queries, the Lambda orchestrator analyzes their role and applies the appropriate guardrail to the request.
This approach ensures Amazon Bedrock Knowledge Bases retrieves only documents with metadata attributes matching the user’s permission level. The result is a seamless but secure experience where users receive only the information appropriate to their role, allowing organizations to maintain a single knowledge base while enforcing different levels of information access.
Scenario 2: Architecture diagram
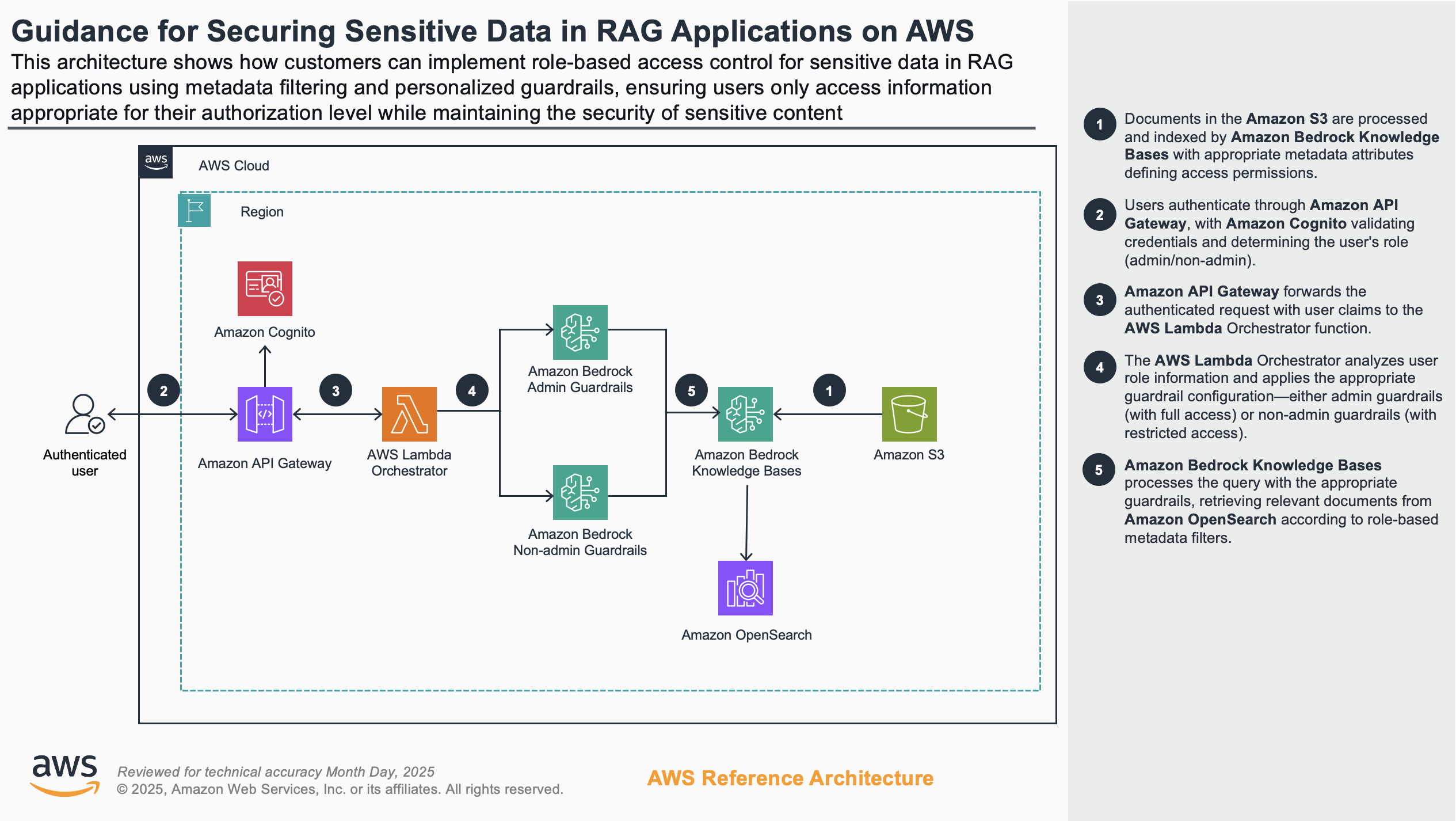
Figure 2: Architecture for role-based access to sensitive data in RAG applications
AWS services in this Guidance
| AWS service | Description |
|---|---|
| Amazon Bedrock Knowledge Bases | Core - Provides the retrieval augmented generation capabilities, enabling the system to store, retrieve, and generate responses based on your organization’s data while maintaining security controls. |
| Amazon Bedrock Guardrails | Core - Implements customizable safeguards in generative AI applications to filter sensitive information and ensure responses comply with organizational policies. |
| Amazon Comprehend | Core - Provides PII detection and redaction capabilities, identifying and masking sensitive information before document storage. |
| Amazon Macie | Core - Performs deep security scanning to verify redaction effectiveness and identify remaining sensitive data objects. |
| Amazon S3 | Supporting - Stores source documents, redacted documents, and quarantined documents requiring manual review. |
| Amazon OpenSearch Service | Supporting - Functions as the vector database that stores document embeddings for semantic similarity searches. |
| AWS Lambda | Supporting - Orchestrates the document processing workflow, including redaction initiation, verification, and query processing. |
| Amazon API Gateway | Supporting - Handles user requests and authenticates access to the RAG application. |
| Amazon Cognito | Supporting - Provides authentication and user identity management with role-based access control. |
| Amazon DynamoDB | Supporting - Tracks redaction and verification job status and metadata. |
| Amazon EventBridge | Supporting - Triggers Lambda functions based on events like document uploads and job completions. |
Plan your deployment
This section describes the cost, security, AWS Regions, and other considerations prior to deploying the solution.
Cost
You are responsible for the cost of the AWS services used while running this Guidance. As of April 2025, the cost for running this Guidance with an estimated 10GB of document processing in the US East (N. Virginia) Region is approximately $572.30 per month.
Refer to the pricing webpage for each AWS service used in this Guidance.
We recommend creating a budget through AWS Cost Explorer to help manage costs. Prices are subject to change. For full details, refer to the pricing webpage for each AWS service used in this Guidance.
Sample cost table
The following table provides a sample cost breakdown for deploying this Guidance with the default parameters in the US East (N. Virginia) Region for one month.
| AWS service | Dimensions | Cost [USD] |
|---|---|---|
| Amazon S3 | 100GB Standard Storage, various operations and data transfers | $4.30/month |
| AWS Lambda | 20,000 total invocations across functions | $2.00/month |
| Amazon DynamoDB | On-demand capacity for job tracking | $5.00/month |
| Amazon Comprehend | PII Detection & Redaction for 5,000 documents | $20.00/month |
| Amazon Macie | Sensitive Data Discovery for 100GB | $100.00/month |
| Amazon Bedrock | 10,000 Knowledge Base queries and Guardrails processing | $81.00/month |
| Amazon OpenSearch | 10GB Serverless capacity | $350.00/month |
| Amazon API Gateway | 10,000 API calls | $3.50/month |
| Amazon Cognito | 100 monthly active users | $5.50/month |
| Amazon EventBridge | 10,000 events | $1.00/month |
| Total | $572.30/month |
Security
When you build systems on AWS infrastructure, security responsibilities are shared between you and AWS. This shared responsibility model reduces your operational burden because AWS operates, manages, and controls the components including the host operating system, the virtualization layer, and the physical security of the facilities in which the services operate. For more information about AWS security, visit AWS Cloud Security.
IAM roles and permissions
- Least privilege access: All Lambda functions use IAM roles with specific permissions limited to only what’s required for their operation.
- Resource-based policies: S3 buckets containing sensitive documents have bucket policies that restrict access to only authorized services and roles.
- Service roles: Custom IAM roles for Amazon Comprehend and Amazon Macie with permissions to access only the specific S3 buckets needed for document processing.
- Cross-service permissions: Lambda functions have scoped permissions to interact with Amazon Bedrock Knowledge Bases, Amazon Comprehend, and Amazon Macie.
Authentication and authorization
- Amazon Cognito user pools: Provides secure user authentication and stores user attributes including role information (admin/non-admin).
- JWT token validation: API Gateway validates JSON Web Tokens (JWTs) issued by Amazon Cognito to authenticate API requests.
- Role-based access control (RBAC): Different guardrails are applied based on user roles extracted from authentication tokens.
- Session management: Secure handling of user sessions with appropriate token expiration and refresh policies.
Data protection
- PII detection and masking: Amazon Comprehend identifies and replaces sensitive entities with placeholder tokens (e.g., [NAME], [SSN]) rather than using generic mask characters to preserve document context.
- Multiple security verification layers: Two-stage verification process with Amazon Comprehend for initial redaction followed by Amazon Macie for deep scanning in Scenario 1.
- Document security classification: Documents receive severity ratings based on remaining sensitive data after redaction.
- Secure storage segregation: Different S3 folders for processing, scanning, redacted, and quarantined documents with appropriate access controls.
- Metadata-based access control: In Scenario 2, document metadata attributes control which users can access specific documents based on security classification.
Application security
- Input validation: Amazon Bedrock Guardrails validate user inputs against defined policies.
- Output filtering: Guardrails filter model responses to prevent leakage of sensitive information.
- Custom guardrail policies: Different guardrail configurations for admin versus non-admin users, particularly important in Scenario 2.
- Metadata filtering: In Scenario 2, vector store queries are filtered based on user role metadata to restrict access to sensitive documents.
- Event-driven security workflows: In Scenario 1, EventBridge rules trigger security processes automatically when new documents are detected.
Logging and monitoring
- CloudTrail integration: All API calls to AWS services are logged for security audit and compliance purposes.
- Job tracking: DynamoDB tables track security job status and completion for PII redaction and verification processes.
- Access logging: S3 access logs and API Gateway access logs capture all access attempts to protected resources.
- Error handling: Security-focused error handling prevents information disclosure in error messages.
This comprehensive security architecture ensures sensitive data is protected throughout the document processing pipeline, from initial ingestion through storage to retrieval and response generation, while maintaining appropriate access controls based on user roles and permissions.
Supported AWS Regions
This Guidance uses the Amazon Bedrock Knowledge Bases, which is not currently available in all AWS Regions. You must launch this solution in an AWS Region where Amazon Bedrock Knowledge Bases is available. For the most current availability of AWS services by Region, refer to the AWS Regional Services List.
Gudiance for Securing Sensitive Data in RAG Applications using Amazon Bedrock is supported in the following AWS Regions:
| Region Name | |
|---|---|
| US East (Ohio) | Europe (Frankfurt) |
| US East (N. Virginia) | Europe (Zurich) |
| US West (Oregon) | Europe (Stockholm) |
| Asia Pacific (Tokyo) | Europe (Ireland) |
| Asia Pacific (Seoul) | Europe (London) |
| Asia Pacific (Mumbai) | Europe (Paris) |
| Asia Pacific (Singapore) | South America (São Paulo) |
| Asia Pacific (Sydney) | AWS GovCloud (US-East) |
| Canada (Central) | AWS GovCloud (US-West) |
Quotas
Service quotas, also referred to as limits, are the maximum number of service resources or operations for your AWS account.
Quotas for AWS services in this Guidance
Make sure you have sufficient quota for each of the services implemented in this solution. For more information, see AWS service quotas.
To view the service quotas for all AWS services in the documentation without switching pages, view the information in the Service endpoints and quotas page in the PDF instead.
Deploy the Guidance
Prerequisites
Before you deploy this Guidance, ensure that you have the following:
- An AWS account with administrator permissions
- Python version 3.10.16 or later installed on your local machine
- AWS Cloud Development Kit (CDK) CLI version 2.1005.0 or later installed
- Docker Desktop installed and running (required for custom CDK constructs)
- Amazon Macie enabled in your AWS account
- Model access enabled in Amazon Bedrock for:
- Anthropic Claude (Text and Text & Vision generation models)
- Amazon Titan Text Embedding V2 (Embedding Model)
Deployment process overview
Before you launch the Guidance, review the cost, architecture, security, and other considerations discussed in this guide. Follow the step-by-step instructions in this section to configure and deploy the Guidance into your account.
Time to deploy: Approximately 45-60 minutes
Step 1: Clone the repository and prepare the environment
- Open a terminal window.
Clone the Amazon Bedrock samples repository.
git clone https://github.com/aws-solutions-library-samples/guidance-for-securing-sensitive-data-in-rag-applications-using-amazon-bedrock.gitNavigate to the repository directory.
cd guidance-for-securing-sensitive-data-in-rag-applications-using-amazon-bedrockCreate and activate a Python virtual environment.
python -m venv .venv source .venv/bin/activateUpgrade pip and install the required dependencies.
pip install -U pip pip install -r requirements.txt
Step 2: Generate synthetic data for testing
Generate sample data containing synthetic PII for testing purposes.
python synthetic_data.py --seed 123 generate -n 10Verify that the data files are created in the
data/directory.
Step 3: Deploy and test your chosen scenario
Choose either Scenario 1 or Scenario 2 based on your security requirements.
Option A: Deploy Scenario 1 (Data redaction at storage level)
Navigate to the scenario_1 directory.
cd scenario_1Make the deployment script executable and run it.
chmod +x run_app.sh ./run_app.sh- When prompted, set a password for the Cognito user
jane@example.com. - Wait for the deployment to complete (approximately 30-45 minutes). The script will:
- Deploy the CDK stack
- Trigger Lambda functions
- Monitor Amazon Comprehend and Amazon Macie job completions
- Launch the Streamlit application
- After deployment completes, the Streamlit app will automatically launch at http://localhost:8501/.
- Log in with
jane@example.comand the password you set earlier. - From the sidebar, select a model and optionally adjust parameters like temperature and top_p.
- Test the application with sample queries such as:
- “What medications were recommended for Chronic migraines”
- “What is the home address of Nikhil Jayashankar”
- “List all patients under Institution Flores Group Medical Center”
Option B: Deploy Scenario 2 (Role-based access to sensitive data)
Navigate to the scenario_2 directory.
cd scenario_2Make the deployment script executable and run it.
chmod +x run_app.sh ./run_app.sh- Wait for the deployment to complete. The script will deploy the CDK stack and launch the Streamlit application.
- After deployment completes, the Streamlit app will automatically launch at http://localhost:8501/.
- Log in with either:
jane@example.comfor Admin accessjohn@example.comfor Non-Admin access
- From the sidebar, select a model and optionally adjust parameters.
- Test the application with sample queries such as:
- “List all patients with Obesity as Symptom and the recommended medications”
- “Generate a list of all patient names and a summary of their symptoms grouped by symptoms. Output in markdown table format.”
- “Tell me more about Mr. Smith and the reason PMD is needed” (works for Admins only)
Troubleshooting
This section provides solutions for common issues you might encounter when deploying and using this Guidance.
Deployment Issues
| Issue | Possible Cause | Resolution |
|---|---|---|
| CDK deployment fails with permissions error | Insufficient IAM permissions | Ensure your AWS account has administrator permissions as specified in prerequisites. Check CloudFormation logs for specific permission errors and add required permissions to your deployment role. |
| Docker-related errors during deployment | Docker not running or insufficient resources | Verify Docker Desktop is running and restart Docker if necessary. For Linux environments, check Docker daemon status with systemctl status docker. |
| Amazon Bedrock model access errors | Models not enabled in your account | Navigate to the Amazon Bedrock console, select “Model access” in the left navigation pane, and enable access to required models (Anthropic Claude and Amazon Titan Text Embedding). |
| Scenario 1: Certain PII Entity types not redacted | Unsupported Entity type in Comprehend | Check Amazon Comprehend’s Redaction Config if the entity type is supported. If it is, then edit redaction_config in comprehend_lambda.py to include the entity type you wish to redact. |
| Macie job failures | Macie not properly enabled or missing service-linked role | 1. Verify Macie is enabled in your account and region. Run aws macie2 enable-macie via AWS CLI if needed. Check if the service-linked role exists with proper permissions. 2. Check for errors in Lambda logs for MacieLambda in CloudWatch. Run the below command to get the MACIE_LAMBDA function name and check for logs either from Lambda console or CloudWatch. STACK_NAME="CdkPiiScenario1Stack" && MACIE_LAMBDA=$(aws cloudformation describe-stacks --stack-name $STACK_NAME --query 'Stacks[0].Outputs[?OutputKey=="MacieLambdaFunction"].OutputValue' --output text) && echo $MACIE_LAMBDAFilter CloudWatch log groups under namespace ‘/aws/lambda/«MACIE_LAMBDA»’ (replace «MACIE_LAMBDA» with Function name from above.) |
Knowledge Base and Query Issues
| Issue | Possible Cause | Resolution |
|---|---|---|
| Knowledge Base queries return irrelevant results | Embedding quality or retrieval configuration issues | Adjust the number of retrieved chunks and relevance threshold. Consider reprocessing documents with different chunking strategies. |
| Guardrails blocking legitimate queries | Overly restrictive guardrail policies | 1. Review guardrail configurations in the Amazon Bedrock console. Adjust topic and sensitive information filters to balance security with usability. Consider creating separate guardrails for different user roles. 2. For Scenario1 check Bedrock APIGW Lambda |
Authentication and Access Control Issues
| Issue | Possible Cause | Resolution |
|---|---|---|
| Unable to log in to Streamlit app | Cognito user not properly created or password issues | Verify the Cognito user was created successfully. Reset the user password using the AWS CLI: aws cognito-idp admin-set-user-password --user-pool-id YOUR_POOL_ID --username jane@example.com --password NewPassword123! --permanent |
| Access denied errors in Scenario 2 | Role-based permissions not properly configured | Check IAM roles and policies. Verify user attributes in Cognito match expected values for role-based access. |
| Unauthorized access to sensitive data | Metadata filtering not working correctly | Verify document metadata attributes are correctly set during ingestion. |
Monitoring and Observability
Amazon CloudWatch provides comprehensive monitoring for all components of your secure RAG application. Configure CloudWatch Logs to capture security-relevant events from Amazon Comprehend PII detection activities, Amazon Macie findings, and Amazon Bedrock Guardrails enforcement actions. Create CloudWatch dashboards to visualize security metrics such as document classification status, guardrail effectiveness, and access patterns.
Security Monitoring
For Scenario 1 (Data redaction at storage level), focus monitoring on the document processing pipeline to ensure redaction effectiveness. Track the status of redaction jobs, verification processes, and document quarantine events. Monitor the percentage of documents successfully processed versus those requiring manual review.
For Scenario 2 (Role-based access), prioritize monitoring of access patterns and guardrail applications based on user roles. Track which users are accessing what types of information and verify that appropriate guardrails are consistently applied based on authentication claims.
Threat Detection and Response
Configure alerts for suspicious activities such as multiple authentication failures, unusual access patterns, or guardrail bypass attempts. Consider integrating with AWS Security Hub to consolidate security findings across your RAG application and maintain a comprehensive view of your security posture.
Implement automated response workflows using EventBridge rules that trigger remediation actions when security events are detected. For example, automatically quarantine documents that fail verification or temporarily restrict access when unusual query patterns are detected.
Performance and Scalability
When deploying secure RAG applications in production environments, it’s critical to establish performance baselines and understand scaling considerations, especially as they relate to security controls. This section outlines key performance dimensions and scalability factors for both security scenarios.
Performance Dimensions
- Query Response Time: Monitor the full lifecycle of user queries, from initial authentication through guardrail evaluation, vector retrieval, and model generation. In Scenario 1 (data redaction), measure the impact of working with redacted content on retrieval quality. For Scenario 2 (role-based access), track how metadata filtering affects response times across different user roles.
- Processing Throughput: Establish baselines for document ingestion rates, PII detection effectiveness, and verification processes. The security pipeline in Scenario 1 introduces additional processing overhead that should be measured - particularly how document complexity and PII density affect redaction and verification times.
- Concurrency Handling: Understand how security controls perform under varying loads. For Scenario 2, test how the system maintains role separation during peak usage when multiple users with different permission levels access the system simultaneously.
Scalability Considerations
- Knowledge Base Optimization: As your knowledge base grows, security considerations become more complex. For Scenario 1, monitor how larger document volumes affect redaction accuracy and verification timing. For Scenario 2, test how metadata filtering performance scales with increasing document counts and user roles.
- Service Quota Management: Security processes consume additional quota capacity. Monitor usage against service quotas for Amazon Bedrock Guardrails, Amazon Comprehend PII operations, and Amazon Macie scanning jobs to prevent security process interruptions.
- Security Pipeline Scaling: The document processing workflow in Scenario 1 includes multiple security checkpoints that must scale independently. Consider implementing queue-based architectures for high-volume document processing while maintaining complete security verification.
- Verification Backlog Handling: Implement strategies for managing documents that require human verification when scaling to large volumes. This might include priority queuing systems for sensitive document review.
Performance and Security Trade-offs
When optimizing for performance, always consider the security implications. Techniques like document batching or parallel processing can improve throughput but should be implemented while maintaining separation of duties and least privilege principles. Similarly, caching mechanisms should be designed to avoid inadvertently exposing sensitive information across user sessions.
As usage increases, regularly review performance metrics alongside security audit logs to verify that security controls remain effective at scale. Establish appropriate alerts for performance degradation that could impact either security effectiveness or user experience.
Customizing the Solution
The security patterns in this Guidance can be adapted to meet the unique requirements of various regulated industries. Below are examples of how organizations in specific sectors can customize the solution to address their particular security and compliance needs.
Healthcare Example
For healthcare organizations implementing RAG applications with patient data:
- Configure Amazon Comprehend to detect PHI entities like patient identifiers and medical record numbers
- Implement role-based access that mirrors clinical hierarchies (doctors see complete records, nurses see limited information)
- Create guardrails that prevent generation of diagnostic content or medical advice
- Enhance the verification pipeline to apply additional healthcare-specific checks on redacted documents before ingestion
Financial Services Example
For financial institutions handling sensitive client information:
- Extend PII detection to include account numbers, transaction data, and investment details
- Apply metadata tagging based on data classification policies (confidential, restricted, public)
- Implement guardrails that prevent generation of investment advice that could violate SEC regulations
- Customize the Macie verification process to detect financial-specific sensitive data patterns that standard PII detection might miss
Implementation Considerations
When customizing the solution for your industry, consider the following:
- Regulatory Mapping: Identify the specific regulations governing your industry and map them to the security controls implemented in the solution.
- Entity Recognition Enhancement: Extend the default entity recognition capabilities with industry-specific entity types and custom entity recognizers.
- Guardrail Customization: Create industry-specific guardrail policies that address unique concerns such as preventing the generation of regulated advice or maintaining appropriate professional boundaries.
- Metadata Strategy: Develop a comprehensive metadata strategy that enables fine-grained access control based on industry-specific classification schemes.
The CDK-based implementation provides extension points that allow organizations to incorporate these customizations without modifying the core security architecture. By leveraging the flexible components of the solution, organizations can maintain compliance with industry-specific regulations while still benefiting from the power of generative AI applications.
Maintenance and Updates
Securing sensitive data in RAG applications requires continuous attention as both threats and organizational needs evolve. Regular maintenance ensures your security controls remain effective and adapt to new challenges.
Security Control Maintenance
Guardrail Configuration Reviews: Schedule quarterly reviews of your Amazon Bedrock Guardrails configurations to ensure they align with evolving organizational policies and emerging threats. During these reviews, evaluate the effectiveness of existing patterns for detecting sensitive information, test guardrail policies against new prompt injection techniques, and update topic filters based on recent security incidents. Involve both security teams and business stakeholders to balance protection with usability requirements.
PII Detection Updates: Periodically review Amazon Comprehend PII entity types used in your redaction workflows and enhance detection patterns to address new types of sensitive information or improved recognition patterns. Consider emerging data privacy regulations that may identify new categories of protected information. Test these updates against sample documents to verify detection accuracy before deployment to production.
Access Control Audits: For Scenario 2 (role-based access), conduct regular reviews of user roles and permissions to ensure the principle of least privilege is maintained as organizational structures evolve. Map roles to specific job functions and verify that access permissions match current responsibilities. Look for instances where roles might have accumulated unnecessary permissions over time through organizational changes.
Knowledge Base Optimization
Document Reprocessing: Schedule periodic reprocessing of sensitive documents using updated PII detection methods to catch previously unidentified sensitive data, especially for Scenario 1 (data redaction). Create a prioritized schedule that focuses first on high-risk document categories or those processed with earlier versions of your detection models.
Metadata Schema Evolution: For Scenario 2, plan for metadata schema evolution to support more granular access controls as your organization’s security requirements mature. Review how document metadata is structured and utilized for access control decisions. Consider whether additional attributes could provide more precise control over document access, such as evolving from simple role-based filters to include department, project, or data classification level attributes.
Chunking Strategy Refinement: Review and refine your document chunking strategy based on retrieval quality metrics, balancing information context with security considerations. Analyze whether your current chunking approach is adequately preserving context while preventing sensitive data leakage. Adjust chunk size, overlap, and boundary decisions based on these insights.
Implementing these maintenance practices on a regular schedule helps ensure your RAG security controls remain effective against evolving threats while supporting changes in organizational structure and information sensitivity classifications. Establish clear ownership for each maintenance activity and incorporate findings into a continuous improvement process for your secure RAG implementation.
Uninstall the Guidance
You can uninstall the Guidance for Securing Sensitive Data in RAG Applications by following these steps:
Using CDK to destroy resources
- Navigate to the appropriate scenario directory (scenario_1 or scenario_2).
Change to the cdk directory.
cd cdkRun the CDK destroy command.
cdk destroy- When prompted, confirm the deletion of the stack.
Important note on resource cleanup
The cdk destroy command will delete all deployed resources including S3 buckets. Ensure you’ve saved any important data before proceeding with the cleanup.
Related resources
- Amazon Bedrock Documentation - Provides detailed information about Amazon Bedrock services and capabilities.
- Amazon Bedrock Knowledge Bases - Explains how to create and manage knowledge bases for RAG applications.
- Amazon Bedrock Guardrails - Describes how to implement safeguards in your generative AI applications.
- Bedrock Guardrails sensitive information filters - Information about configuring sensitive data filters in Bedrock Guardrails.
- OWASP Top 10 for Large Language Model Applications - Provides information about security risks associated with generative AI applications.
Contributors
- Praveen Chamarti
- Srikanth Reddy
Revisions
| Date | Change |
|---|---|
| Jun 2025 | Initial Release |
Notices
Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents AWS current product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. AWS responsibilities and liabilities to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers.