Guidance for Low-Latency, High Throughput Model Inference Using Amazon Sagemaker
Summary: This implementation guide provides an overview of the Guidance for Low Latency High Throughput Model Inference Using Amazon Sagemaker, its reference architecture and components, considerations for planning the deployment, and configuration steps for deploying the Guidance to Amazon Web Services (AWS). This guide is intended for solution architects, business decision makers, DevOps engineers, data scientists, and cloud professionals who want to implement the Guidance for Low-Latency, High Throughput Model Inference Using Amazon Sagemaker.
Overview
This Guidance is aimed at advertising technology (adtech) companies, like demand-side platforms (DSP) and supply-side platforms (SSP), that use AWS to host a real-time bidding infrastructure. Taking the example of a DSP, they need to reduce server load and optimize costs. For this, they can implement a machine learning (ML) solution that predicts the likelihood of bids on a given request and filters out low-probability requests before they reach bidders.
Typically, the data scientists train the model and hand it over to the operations team, which has to research and establish optimal practices for hosting the model. Such an ML model must be capable of scaling to millions of requests per second while maintaining a low latency of less than 20 milliseconds while being cost-effective. This guide provides detailed instructions on deploying such a solution using Amazon SageMaker.
Scenario
To help you navigate the instructions throughout this guide, we created a fictional scenario with a company named ACME, a DSP that utilizes Amazon Web Services (AWS) to host its ad servers. To reduce server load and optimize costs, ACME is looking to implement an ML solution that predicts the likelihood to bid on a given request and filters out low-probability requests before they reach ad servers. ACME’s data scientists have trained the model, and the ACME operations team is assigned to research and establish optimal practices for hosting the model. This model must be capable of scaling to millions of requests per second while maintaining a low latency of less than 20 milliseconds. Furthermore, the solution must be cost-effective.
Implementation Details
This guide provides detailed instructions on deploying this Guidance using Amazon SageMaker and consists of the following sections:
- Solution Overview and reference architecture
- Deployment using Amazon SageMaker
- Optimizing SageMaker Endpoint Performance
- Walkthrough of the SageMaker deployment code for inference
- Stress Testing and Optimizing Real-time Inference Endpoints using Inference Recommender
Solution Overview and architecture diagram
When deploying advertising technology infrastructure, ACME must carefully evaluate several key factors, such as cost, latency, performance, and scalability. Maintaining and supporting the infrastructure should also be straightforward to minimize downtime and ensure seamless operations.
Amazon SageMaker helps address these considerations by providing the full machine learning workflow—from training models to deployment. SageMaker supports low-latency inference, can be scaled to support millions of requests cost-effectively, enables easy management and deployment of models, and integrates with MLOps tools, thus reducing operational burden.
In this guide, we will be using a pre-built traffic filtering machine learning model that predicts the likelihood of a DSP to bid for an ad request submitted by an ad exchange. This model was trained on OpenRTB data. The model’s dataset and features can be found in the RTB Intelligence Kit workshop.
For simplicity, we have hosted this model in an Amazon Simple Storage Service (Amazon S3) bucket. A SageMaker real-time endpoint is then created with the deployable artifact of the trained model.
Although outside the scope of this guide, you can use SageMaker DataWrangler and the capabilities of broader AWS services, such as Amazon EMR or AWS Glue, to perform feature engineering on your own set of data. You can then use SageMaker to train your own models, publish them as deployable artifacts to the SageMaker Model Registry, and host them using SageMaker Endpoints using the recommendations provided in this guide.
The endpoint configurations of SageMaker allows you to specify the instance type and initial instance count. Once the SageMaker real-time endpoint is created, it can be invoked using new data for ongoing predictions.
To communicate with the model, the ad server submits an HTTP/REST request to invoke the endpoint using the SageMaker Runtime API. The Ad Server can be hosted on an Amazon Virtual Private Network (Amazon VPC) on Amazon Elastic Compute Cloud (Amazon EC2) instances, AWS Lambda, Amazon Elastic Container Service (Amazon ECS), or Kubernetes platforms, such as Amazon Elastic Kubernetes Service (Amazon EKS).
We recommended configuring access to SageMaker endpoints through a VPC Interface Endpoint for the SageMaker Runtime API to minimize latency and jitter, and to avoid communicating with the SageMaker platform using public IPs.
Using SageMaker endpoints incurs overhead and network latency, typically in the single-digit milliseconds.
Architecture diagram
This architecture diagram shows how to use Amazon SageMaker to deploy and host machine learning models while supporting low-latency, high-throughput workloads, such as programmatic advertising and real-time bidding RTB.
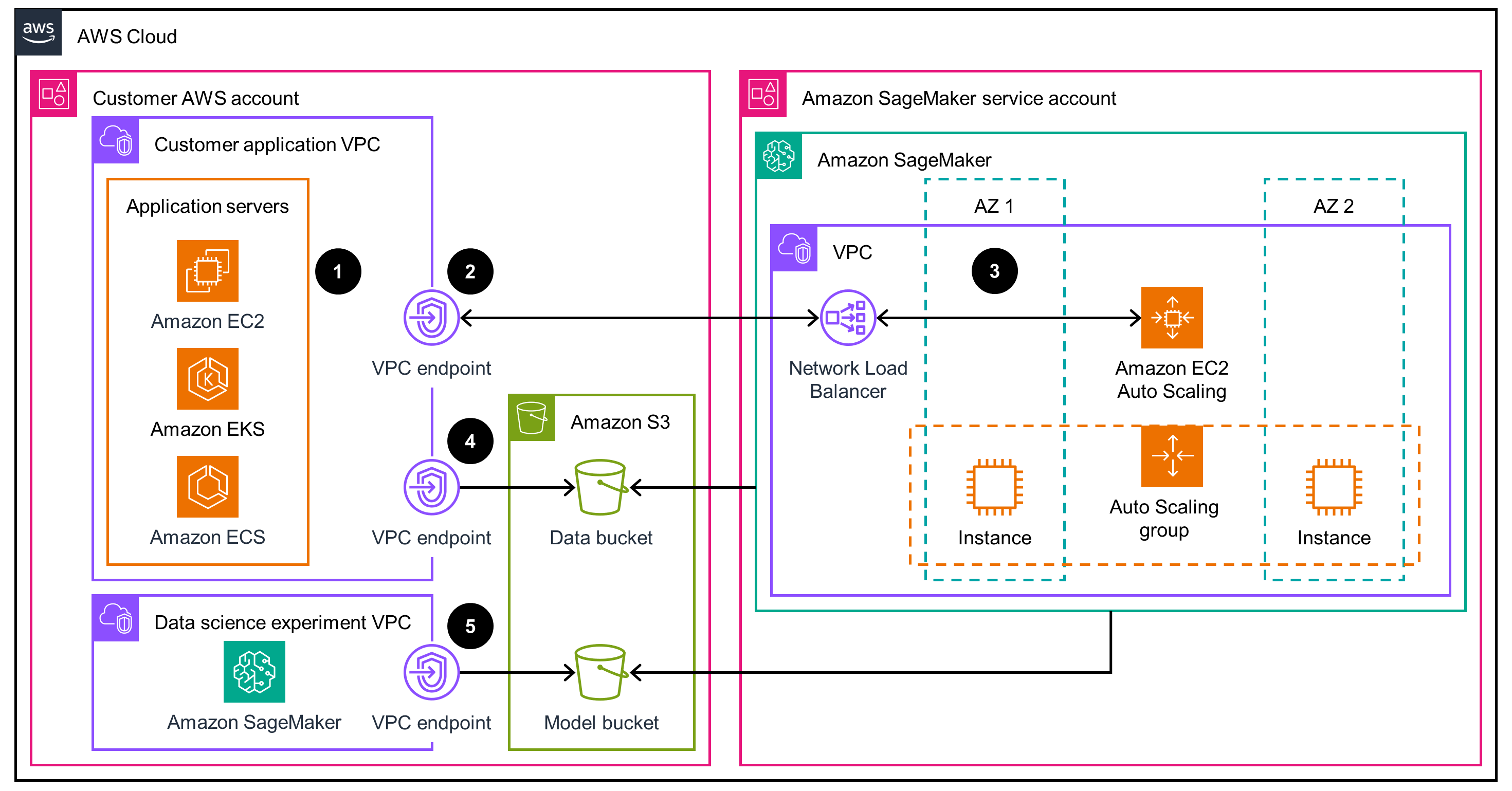
Figure 1: Architecture diagram
Deployment using Amazon SageMaker
SageMaker provides a variety of built-in algorithms and frameworks for training and deploying models, including tabular data algorithms like Scikit-Learn and XGBoost commonly used to model real-time bidding (RTB) datasets. You can train models directly in SageMaker or bring your own pre-trained model to deploy using SageMaker endpoints.
To deploy a model, you need to first specify the framework, including version, language, and instance type. SageMaker uses this information to retrieve an optimized, pre-built container for hosting your model.
Then you specify the instance type and initial number of compute instances to use for your endpoint. Deploying a real-time endpoint creates a hosted inference service, ready to receive incoming requests through HTTP/REST or the SageMaker API. SageMaker can host single or multiple models on an endpoint, handling inference requests with payloads up to 6MB.
To maintain steady performance and optimize cost for real-time inference endpoints, and to support variable volumes of requests or handle peak events, we recommend enabling autoscaling. Autoscaling automatically monitors workloads and adjusts instance capacity as needed.
Optimizing SageMaker Endpoint Performance
You can scale the SageMaker endpoint to high throughput by hosting the model on a fleet of instances. SageMaker offers hosting models on various instance types with various memory, vCPUs, generation, and architecture (including CPUs, GPUs, and custom accelerators like Inferentia2.
Important considerations when scaling:
- Stress test endpoints to determine the target instance count. Note that autoscaling is not instantaneous. To ensure consistent low latency, include a safety factor so client load does not exceed maximum performance. Monitor instance health by tracking CPU, memory, model latency, and failed requests as load increases. Refer to Load testing your auto scaling configuration for more information.
- Experiment with instance sizes to optimize CPU and memory utilization on a single instance. SageMaker provides standard, compute, memory-optimized, and accelerated instance configurations. Refer to Amazon SageMaker pricing for instance types and pricing information.
- Use SageMaker optimizations and specify additional parameters to improve performance.
- Use the SageMaker runtime APIs included with the SageMaker software development kit (SDK) packages for many popular languages to invoke the model. These APIs include important performance optimizations, such as connection pooling and reuse, which can significantly improve performance with high-volume invocations.
- Compile models into optimized executables to potentially improve inference speed and reduce compute and memory needs. For an example, refer to Unlock near 3x performance gains with XGBoost and Amazon SageMaker Neo.
Walkthrough of the SageMaker deployment code for inference
In SageMaker Studio, open the source/rtb_xgboost_Sagemaker_realtime_endpoint_deploy_invoke.ipynb notebook.
We have provided a Jupyter Notebook containing deployment code and the model as a deployable artifact (tar.gz file). This artifact was created as part of the RTB Intelligence Kit workshop.
Run the Notebook line-by-line. For added context, follow the comments provided in the Notebook.
At a high level, the code in the Notebook demonstrates the process of deploying a machine learning model on Amazon SageMaker:
It starts by setting up the necessary AWS services, including SageMaker, and retrieving the default S3 bucket and execution role.
Next, it creates a SageMaker model object by uploading a pre-trained XGBoost model artifact to the S3 bucket and specifying the Docker container image URI, environment variables, and other required parameters. The model is then registered with SageMaker using the
create_modelAPI.The code proceeds to create an endpoint configuration, which specifies the compute instance type and initial instance count for hosting the model. This configuration is then used to create a real-time SageMaker endpoint using the
create_endpointAPI.The endpoint creation process is monitored by periodically calling the
describe_endpointAPI until the endpoint reaches the “InService” status, indicating that it is ready to receive real-time predictions.Finally, the code demonstrates how to invoke the deployed endpoint using the
invoke_endpointAPI, passing a sample input data point in CSV format and receiving the model’s prediction as the response.
In summary, it encapsulates the key steps involved in deploying a machine learning model on Amazon SageMaker, enabling real-time inference capabilities, and facilitating the integration of the model into your applications.
Stress Testing and Optimizing Real-time Inference Endpoints using Inference Recommender
When stress testing SageMaker endpoints, we will use SageMaker Inference Recommender, a built-in load testing solution, to test various hardware combinations.
In SageMaker Studio, open the source/rtb_xgboost_SageMaker_inference_benchmark_tests.ipynb notebook.
You must complete steps in the source/rtb_xgboost_Sagemaker_realtime_endpoint_deploy_invoke.ipynbnotebook before running code in this notebook.
For added context, follow the comments provided in the Notebook.
At a high level, the code in the Notebook demonstrates how to use Amazon SageMaker’s Inference Recommender to obtain optimal instance type recommendations for deploying a machine learning model.
It begins by setting up the necessary AWS resources, such as initializing the SageMaker session, retrieving the default S3 bucket, and importing data and variables from a previous notebook.
The code then showcases how to retrieve instant deployment recommendations from the
DescribeModelAPI and visualize them using pandas. However, to obtain more accurate and comprehensive recommendations, it suggests running additional instance recommendation jobs.The code defines variables for the machine learning domain, task, framework, and framework version. It then creates a sample payload archive containing representative data that the Inference Recommender can use to test the model’s performance.
Next, the code registers the pre-trained model as a new version in the SageMaker Model Registry, specifying the model group, domain, task, sample payload URL, and other relevant configurations.
With the model registered, the code creates an Inference Recommender ‘Default’ job, which provides initial instance recommendations within 15-20 minutes. It then retrieves and displays the recommended instance types, along with associated environment variables, cost, throughput, and latency metrics.
In summary, the code suggests an easy-to-implement approach that can help narrow down the optimal endpoint configuration based on specific use-case requirements, such as prioritizing overall price-performance with an emphasis on throughput or balancing latency and throughput.
Close out
This implementation guide provides instructions for deploying a machine learning model on Amazon SageMaker to enable low-latency, high-throughput real-time inferences. It covers creating a SageMaker endpoint, optimizing performance through instance selection, stress testing, and benchmarking different instance types.
The guide aims to help ACME’s operations teams deploy models cost-effectively while meeting demanding latency and scalability requirements.
Security
When you build systems on AWS infrastructure, security responsibilities are shared between you and AWS. This shared responsibility model reduces your operational burden because AWS operates, manages, and controls the components, including the host operating system, the virtualization layer, and the physical security of the facilities in which the services operate. For more information about AWS security, visit AWS Cloud Security.
Add components that were used to improve security (for example: IAM roles and permissions and AWS Secrets Manager). Also, include the Amazon CloudFront section if your Guidance has a web console or app. Include the VPC Security Groups section if your Guidance includes security groups. List examples used in each category, where applicable. If your Guidance is a security Guidance, you may be able to delete this section.
Supported AWS Regions
This Guidance uses the Amazon SageMaker service, which may not be available in all AWS Regions. You must launch this solution in an AWS Region where Amazon SageMaker is available. For the most current availability of AWS services by Region, refer to the AWS Regional Services List.
Quotas
Service quotas, also referred to as limits, are the maximum number of service resources or operations for your AWS account.
Quotas for AWS services in this Guidance
Make sure you have sufficient quota for each of the services implemented in this solution. For more information, refer to AWS service quotas.
To view the service quotas for all AWS services in the documentation without switching pages, view the information in the Service endpoints and quotas page in the PDF instead.
Contributors
- Sovik Nath
- Punit Shah
- Ram Vegiraju
- Ranjith Krishnamoorthy
- Steven Alyekhin
Notices
Customers are responsible for making their own independent assessment of the information in this document. This document: (a) is for informational purposes only, (b) represents AWS current product offerings and practices, which are subject to change without notice, and (c) does not create any commitments or assurances from AWS and its affiliates, suppliers or licensors. AWS products or services are provided “as is” without warranties, representations, or conditions of any kind, whether express or implied. AWS responsibilities and liabilities to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers.